
Mākslīgais intelekts
EfficientViT: Atmiņas efektīvas redzes transformators augstas izšķirtspējas datora redzei

Pateicoties lielajai modeļu ietilpībai, Vision Transformer modeļi pēdējā laikā ir guvuši lielus panākumus. Neskatoties uz to veiktspēju, redzes transformatoru modeļiem ir viens būtisks trūkums: to ievērojamā skaitļošanas spēja ir saistīta ar augstām skaitļošanas izmaksām, un tas ir iemesls, kāpēc redzes transformatori nav pirmā izvēle reāllaika lietojumiem. Lai risinātu šo problēmu, izstrādātāju grupa uzsāka EfficientViT — ātrgaitas redzes transformatoru saimi.
Strādājot pie EfficientViT, izstrādātāji novēroja, ka pašreizējo transformatoru modeļu ātrumu bieži ierobežo neefektīvas atmiņas darbības, īpaši elementu funkcijas un tenzoru pārveidošana MHSA vai Multi-Head Self Attention tīklā. Lai novērstu šīs neefektīvās atmiņas darbības, EfficientViT izstrādātāji ir izstrādājuši jaunu bloku, izmantojot sviestmaižu izkārtojumu, ti, EfficientViT modelī tiek izmantots viens ar atmiņu saistīts Multi-Head Self Attention tīkls starp efektīviem FFN slāņiem, kas palīdz uzlabot atmiņas efektivitāti un uzlabojot arī kopējo kanālu komunikāciju. Turklāt modelis arī atklāj, ka uzmanības kartēm bieži ir liela līdzība starp galvām, kas izraisa skaitļošanas dublēšanos. Lai risinātu atlaišanas problēmu, EfficientViT modelī ir iekļauts kaskādes grupas uzmanības modulis, kas nodrošina uzmanības galviņas ar dažādiem pilnas funkcijas sadalījumiem. Metode ne tikai palīdz ietaupīt skaitļošanas izmaksas, bet arī uzlabo modeļa uzmanības daudzveidību.
Visaptveroši eksperimenti, kas veikti ar EfficientViT modeli dažādos scenārijos, liecina, ka EfficientViT pārspēj esošos efektīvus modeļus datora vīzija vienlaikus radot labu kompromisu starp precizitāti un ātrumu. Tāpēc iedziļināsimies un izpētīsim EfficientViT modeli nedaudz dziļāk.
Ievads par Vision Transformers un EfficientViT
Vision Transformers joprojām ir viens no populārākajiem ietvariem datoru redzes nozarē, jo tie piedāvā izcilu veiktspēju un augstas skaitļošanas iespējas. Tomēr, pastāvīgi uzlabojot redzes transformatoru modeļu precizitāti un veiktspēju, palielinās arī darbības izmaksas un skaitļošanas pieskaitāmās izmaksas. Piemēram, pašreizējie modeļi, par kuriem zināms, ka tie nodrošina jaunāko veiktspēju tādās ImageNet datu kopās kā SwinV2 un V-MoE, izmanto attiecīgi 3B un 14.7B parametrus. Šo modeļu milzīgais izmērs kopā ar skaitļošanas izmaksām un prasībām padara tos praktiski nepiemērotus reāllaika ierīcēm un lietojumprogrammām.
EfficientNet modeļa mērķis ir izpētīt, kā uzlabot veiktspēju redzes transformatoru modeļiun atrast principus, kas saistīti ar efektīvu un iedarbīgu uz transformatoriem balstītu ietvara arhitektūru projektēšanu. EfficientViT modelis ir balstīts uz esošajām redzes transformatoru sistēmām, piemēram, Swim un DeiT, un tas analizē trīs būtiskus faktorus, kas ietekmē modeļu traucējumu ātrumu, tostarp aprēķinu dublēšanu, piekļuvi atmiņai un parametru izmantošanu. Turklāt modelī ir novērots, ka redzes transformatoru modeļu ātrums ar atmiņu saistīts, kas nozīmē, ka pilnīga skaitļošanas jaudas izmantošana CPU/GPU ir aizliegta vai ierobežota ar atmiņas piekļuves aizkavi, kas negatīvi ietekmē transformatoru darbības ātrumu. . Elementu funkcijas un tensoru pārveidošana MHSA vai Multi-Head Self Attention tīklā ir atmiņas ziņā visneefektīvākās darbības. Modelis arī norāda, ka optimāla attiecības starp FFN (padeves pārvades tīkls) un MHSA pielāgošana var palīdzēt ievērojami samazināt atmiņas piekļuves laiku, neietekmējot veiktspēju. Tomēr modelis arī novēro zināmu dublēšanos uzmanības kartēs, jo uzmanības galvas tieksme apgūt līdzīgas lineāras projekcijas.
Modelis ir EfficientViT izpētes darba laikā iegūto atklājumu nobeigums. Modelim ir jauns melns ar sviestmaižu izkārtojumu, kas izmanto vienu ar atmiņu saistītu MHSA slāni starp pārvades tīkla vai FFN slāņiem. Šī pieeja ne tikai samazina laiku, kas nepieciešams ar atmiņu saistītu darbību izpildei MHSA, bet arī padara visu procesu efektīvāku atmiņu, ļaujot vairākiem FFN slāņiem atvieglot saziņu starp dažādiem kanāliem. Modelis izmanto arī jaunu CGA vai Cascaded Group Attention moduli, kura mērķis ir padarīt aprēķinus efektīvākus, samazinot skaitļošanas dublēšanos ne tikai uzmanības galvās, bet arī palielina tīkla dziļumu, kā rezultātā palielinās modeļa jauda. Visbeidzot, modelis paplašina galveno tīkla komponentu kanāla platumu, tostarp vērtību projekcijas, vienlaikus samazinot tīkla komponentus ar zemu vērtību, piemēram, slēptiem izmēriem padeves tīklos, lai pārdalītu parametrus sistēmā.

Kā redzams iepriekš redzamajā attēlā, EfficientViT sistēma darbojas labāk nekā pašreizējie jaunākie CNN un ViT modeļi gan precizitātes, gan ātruma ziņā. Bet kā EfficientViT sistēmai izdevās pārspēt dažas pašreizējās jaunākās sistēmas? Noskaidrosim to.
EfficientViT: redzes transformatoru efektivitātes uzlabošana
EfficientViT modeļa mērķis ir uzlabot esošo redzes transformatoru modeļu efektivitāti, izmantojot trīs perspektīvas,
- Aprēķinu atlaišana.
- Piekļuve atmiņai.
- Parametru lietošana.
Modeļa mērķis ir noskaidrot, kā iepriekš minētie parametri ietekmē redzes transformatoru modeļu efektivitāti, un kā tos atrisināt, lai ar labāku efektivitāti sasniegtu labākus rezultātus. Parunāsim par tiem mazliet dziļāk.
Atmiņas piekļuve un efektivitāte
Viens no būtiskākajiem faktoriem, kas ietekmē modeļa ātrumu, ir atmiņas piekļuve virs galvas vai MAO. Kā redzams zemāk esošajā attēlā, vairāki transformatora operatori, tostarp elementu pievienošana, normalizācija un bieža pārveidošana, ir atmiņas neefektīvas darbības, jo tām ir nepieciešama piekļuve dažādām atmiņas vienībām, kas ir laikietilpīgs process.
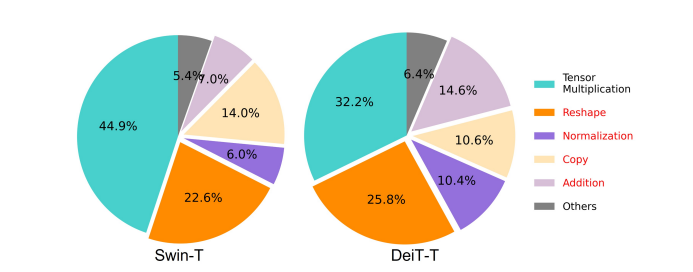
Lai gan ir dažas esošās metodes, kas var vienkāršot standarta softmax pašapziņas aprēķinus, piemēram, zemas pakāpes tuvināšanu un niecīgu uzmanību, tās bieži piedāvā ierobežotu paātrinājumu un pasliktina precizitāti.
No otras puses, EfficientViT ietvara mērķis ir samazināt atmiņas piekļuves izmaksas, samazinot atmiņu neefektīvo slāņu skaitu sistēmā. Modelis samazina DeiT-T un Swin-T līdz maziem apakštīkliem ar lielāku traucējumu caurlaidspēju 1.25X un 1.5X, un salīdzina šo apakštīklu veiktspēju ar MHSA slāņu proporcijām. Kā redzams zemāk esošajā attēlā, šī pieeja palielina MHSA slāņu precizitāti par aptuveni 20 līdz 40%.

Aprēķinu efektivitāte
MHSA slāņi mēdz iegult ievades secību vairākās apakštelpās vai virsrakstos un atsevišķi aprēķina uzmanības kartes, un ir zināms, ka šī pieeja uzlabo veiktspēju. Tomēr uzmanības kartes nav skaitļošanas ziņā lētas, un, lai izpētītu skaitļošanas izmaksas, EfficientViT modelis pēta, kā samazināt lieko uzmanību mazākos ViT modeļos. Modelis mēra katras galviņas un atlikušo galviņu maksimālo kosinusa līdzību katrā blokā, apmācot samazināto platuma DeiT-T un Swim-T modeļus ar 1.25 reižu palielinājumu. Kā redzams zemāk esošajā attēlā, starp uzmanības galvām ir daudz līdzību, kas liecina, ka modelim rodas skaitļošanas dublēšana, jo daudzām galvām ir tendence apgūt līdzīgas precīzas pilnas funkcijas projekcijas.

Lai mudinātu galvas apgūt dažādus modeļus, modelis nepārprotami izmanto intuitīvu risinājumu, kurā katrai galvai tiek ievadīta tikai daļa no visas funkcijas, kas atgādina grupas konvolūcijas ideju. Modelis apmāca dažādus samazināto modeļu aspektus, kuros ir modificēti MHSA slāņi.
Parametru efektivitāte
Vidējie ViT modeļi pārmanto savas dizaina stratēģijas, piemēram, līdzvērtīga platuma izmantošanu projekcijām, izplešanās koeficienta iestatīšanu uz 4 FFN un pakāpju augstuma palielināšanu no NLP transformatoriem. Šo komponentu konfigurācijas ir rūpīgi jāpārveido vieglajiem moduļiem. EfficientViT modelī tiek izmantota Taylor strukturētā atzarošana, lai automātiski atrastu būtiskos komponentus Swim-T un DeiT-T slāņos, un tālāk tiek pētīti pamatā esošie parametru piešķiršanas principi. Pie noteiktiem resursu ierobežojumiem atzarošanas metodes noņem nesvarīgos kanālus un saglabā kritiskos kanālus, lai nodrošinātu visaugstāko iespējamo precizitāti. Tālāk esošajā attēlā ir salīdzināta kanālu attiecība pret ievades iegulšanu pirms un pēc atzarošanas Swin-T sistēmā. Tika novērots, ka: Bāzes precizitāte: 79.1%; apcirpšanas precizitāte: 76.5%.

Iepriekš redzamais attēls norāda, ka pirmie divi ietvara posmi saglabā vairāk izmēru, bet pēdējie divi posmi saglabā daudz mazāk izmēru. Tas varētu nozīmēt, ka tipiska kanāla konfigurācija, kas divkāršo kanālu pēc katra posma vai izmanto līdzvērtīgus kanālus visiem blokiem, var izraisīt ievērojamu dublēšanu dažos pēdējos blokos.
Efektīvs redzes transformators: arhitektūra
Pamatojoties uz iepriekšminētajā analīzē iegūtajām atziņām, izstrādātāji strādāja pie jauna hierarhiska modeļa izveides, kas piedāvā ātrus traucējumus. EfficientViT modelis. Detalizēti apskatīsim EfficientViT ietvara struktūru. Zemāk redzamais attēls sniedz vispārīgu priekšstatu par EfficientViT sistēmu.
EfficientViT pamatelementi
Efektīvāka redzes transformatoru tīkla pamatelements ir parādīts zemāk esošajā attēlā.

Ietvars sastāv no kaskādes grupas uzmanības moduļa, atmiņu efektīva sviestmaižu izkārtojuma un parametru pārdales stratēģijas, kas vērsta uz modeļa efektivitātes uzlabošanu attiecīgi aprēķinu, atmiņas un parametru ziņā. Parunāsim par tiem sīkāk.
Sviestmaižu izkārtojums
Modelis izmanto jaunu sviestmaižu izkārtojumu, lai izveidotu efektīvāku un efektīvāku ietvara atmiņas bloku. Sviestmaižu izkārtojums izmanto mazāk ar atmiņu saistītu pašapziņas slāņu un kanālu saziņai izmanto atmiņu efektīvākus pārsūtīšanas tīklus. Precīzāk sakot, modelis telpiskajai sajaukšanai izmanto vienu pašapziņas slāni, kas ir iestiprināts starp FFN slāņiem. Dizains ne tikai palīdz samazināt atmiņas laika patēriņu, jo tiek izmantoti pašizvērības slāņi, bet arī nodrošina efektīvu saziņu starp dažādiem kanāliem tīklā, pateicoties FFN slāņu izmantošanai. Modelis izmanto arī papildu mijiedarbības marķiera slāni pirms katra padeves tīkla slāņa, izmantojot DWConv vai maldinošu konvolūciju, un uzlabo modeļa kapacitāti, ieviešot vietējās strukturālās informācijas induktīvo novirzi.
Kaskādes grupas uzmanība
Viena no galvenajām problēmām ar MHSA slāņiem ir uzmanības galviņu dublēšana, kas padara aprēķinus neefektīvākus. Lai atrisinātu problēmu, modelis piedāvā CGA vai Cascaded Group Attention redzes transformatoriem — jaunu uzmanības moduli, kas smeļas iedvesmu no grupu konvolucijām efektīvos CNN. Šajā pieejā modelis padod atsevišķas galviņas ar pilnu funkciju sadalījumu, un tāpēc uzmanības aprēķins tiek skaidri sadalīts pa galvām. Funkciju sadalīšana, nevis pilnas funkcijas ievadīšana katrai galvai, ietaupa aprēķinus un padara procesu efektīvāku, un modelis turpina strādāt, lai vēl vairāk uzlabotu precizitāti un tā kapacitāti, mudinot slāņus mācīties projekcijas par līdzekļiem, kuriem ir bagātāka informācija.

Parametru pārdalīšana
Lai uzlabotu parametru efektivitāti, modelis pārdala parametrus tīklā, paplašinot kritisko moduļu kanāla platumu, vienlaikus samazinot ne tik svarīgu moduļu kanāla platumu. Pamatojoties uz Teilora analīzi, modelis vai nu nosaka mazus kanāla izmērus projekcijām katrā galviņā katrā posmā, vai arī modelis ļauj projekcijām būt tādām pašām dimensijām kā ievadei. Arī padeves tīkla paplašināšanas koeficients ir samazināts līdz 2 no 4, lai palīdzētu samazināt tā parametru dublēšanu. Ierosinātā pārdales stratēģija, ko ievieš EfficientViT ietvars, piešķir vairāk kanālu svarīgiem moduļiem, lai tie varētu labāk apgūt attēlojumus augstas dimensijas telpā, tādējādi samazinot funkciju informācijas zudumu. Turklāt, lai paātrinātu traucējumu procesu un vēl vairāk uzlabotu modeļa efektivitāti, modelis automātiski noņem liekos parametrus nesvarīgos moduļos.

Pārskatu par EfficientViT ietvaru var izskaidrot iepriekš redzamajā attēlā, kur ir redzamas daļas,
- EfficientViT arhitektūra,
- Sviestmaižu izkārtojuma bloks,
- Kaskādes grupas uzmanība.
EfficientViT: tīkla arhitektūras

Iepriekš redzamajā attēlā ir apkopota EfficientViT ietvara tīkla arhitektūra. Modelis ievieš pārklājošu ielāpu iegulšanu [20,80], kas iestrādā 16 × 16 ielāpus C1 dimensijas marķieros, kas uzlabo modeļa spēju labāk darboties zema līmeņa vizuālās reprezentācijas mācībās. Modeļa arhitektūra sastāv no trim posmiem, kur katrā posmā tiek sakrauti piedāvātie EfficientViT struktūras bloki, un marķieru skaits katrā apakšiztveršanas slānī (2x izšķirtspējas apakšiztveršana) tiek samazināts par 4X. Lai padarītu apakšizlases ņemšanu efektīvāku, modelis piedāvā apakšizlases bloku, kurā ir arī piedāvātais sviestmaižu izkārtojums, izņemot to, ka apgriezts atlikušais bloks aizstāj uzmanības slāni, lai samazinātu informācijas zudumu paraugu ņemšanas laikā. Turklāt parastā LayerNorm(LN) vietā modelī tiek izmantota BatchNorm(BN), jo BN var salocīt iepriekšējos lineārajos vai konvolucionālajos slāņos, kas tam nodrošina izpildlaika priekšrocības salīdzinājumā ar LN.
EfficientViT modeļu saime
EfficientViT modeļu saime sastāv no 6 modeļiem ar dažādām dziļuma un platuma skalām, un katram posmam ir atvēlēts noteikts galvu skaits. Modeļi sākumposmā izmanto mazāk bloku, salīdzinot ar beigu posmiem, kas ir līdzīgs tam, kam seko MobileNetV3 ietvars, jo sākotnējās stadijas apstrādes process ar lielāku izšķirtspēju ir laikietilpīgs. Platums tiek palielināts pa posmiem ar nelielu koeficientu, lai vēlākos posmos samazinātu dublēšanu. Tālāk pievienotajā tabulā ir sniegta EfficientViT modeļu saimes arhitektūras informācija, kur C, L un H attiecas uz platumu, dziļumu un galvu skaitu konkrētajā posmā.

EfficientViT: modeļa ieviešana un rezultāti
EfficientViT modeļa kopējais partijas lielums ir 2,048, tas ir izveidots, izmantojot Timm & PyTorch, ir apmācīts no nulles 300 laikus, izmantojot 8 Nvidia V100 GPU, izmanto kosinusa mācīšanās ātruma plānotāju, AdamW optimizētāju un veic attēlu klasifikācijas eksperimentu pakalpojumā ImageNet. -1 tūkst. Ievades attēli tiek nejauši apgriezti un mainīti uz izšķirtspēju 224 × 224. Eksperimentiem, kas ietver pakārtoto attēlu klasifikāciju, EfficientViT ietvars precīzi noregulē modeli 300 laikmetiem un izmanto AdamW optimizētāju ar partijas lielumu 256. Modelis izmanto RetineNet objektu noteikšanai COCO un turpina apmācīt modeļus vēl 12 laikiem. laikmeti ar identiskiem iestatījumiem.
Rezultāti vietnē ImageNet
Lai analizētu EfficientViT veiktspēju, tas tiek salīdzināts ar pašreizējiem ViT un CNN modeļiem ImageNet datu kopā. Salīdzinājuma rezultāti ir parādīti nākamajā attēlā. Kā redzams, EfficientViT modeļu saime vairumā gadījumu pārspēj pašreizējos ietvarus un spēj panākt ideālu kompromisu starp ātrumu un precizitāti.

Salīdzinājums ar efektīviem CNN un efektīviem ViT
Modelis vispirms salīdzina tā veiktspēju ar efektīviem CNN, piemēram, EfficientNet, un vaniļas CNN ietvariem, piemēram, MobileNets. Kā redzams, salīdzinot ar MobileNet ietvariem, EfficientViT modeļi iegūst labāku precizitātes rādītāju augstākajā līmenī, savukārt Intel CPU un V1 GPU darbojas attiecīgi 3.0X un 2.5X ātrāk.
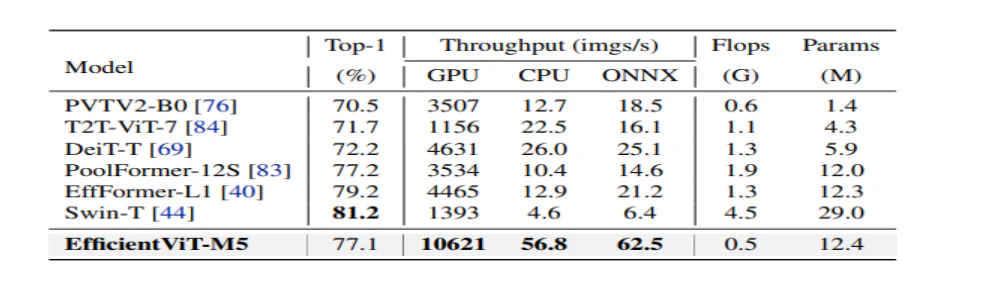
Iepriekš redzamajā attēlā ir salīdzināta EfficientViT modeļa veiktspēja ar vismodernākajiem liela mēroga ViT modeļiem, kas darbojas ImageNet-1K datu kopā.
Pakārtotā attēla klasifikācija
EfficientViT modelis tiek pielietots dažādiem pakārtotiem uzdevumiem, lai pētītu modeļa pārneses mācīšanās spējas, un zemāk esošajā attēlā ir apkopoti eksperimenta rezultāti. Kā redzams, EfficientViT-M5 modelim izdodas sasniegt labākus vai līdzīgus rezultātus visās datu kopās, vienlaikus saglabājot daudz lielāku caurlaidspēju. Vienīgais izņēmums ir Cars datu kopa, kurā EfficientViT modelis nespēj nodrošināt precizitāti.

Objektu noteikšana
Lai analizētu EfficientViT spēju noteikt objektus, tas tiek salīdzināts ar efektīviem modeļiem COCO objektu noteikšanas uzdevumā, un zemāk esošajā attēlā ir apkopoti salīdzināšanas rezultāti.

Final Domas
Šajā rakstā mēs runājām par EfficientViT — ātrās redzamības transformatoru modeļu saimi, kas izmanto kaskādes grupas uzmanību un nodrošina atmiņu efektīvas darbības. Plašie eksperimenti, kas veikti, lai analizētu EfficientViT veiktspēju, ir parādījuši daudzsološus rezultātus, jo EfficientViT modelis vairumā gadījumu pārspēj pašreizējos CNN un redzes transformatoru modeļus. Mēs esam arī mēģinājuši sniegt analīzi par faktoriem, kuriem ir nozīme redzes transformatoru traucējumu ātruma ietekmēšanā.















