
ētika
Pašreizējā AI prakse varētu nodrošināt jaunu autortiesību troļļu paaudzi

Jauna sadarbība starp Huawei un akadēmiskajām aprindām liecina, ka liela daļa no svarīgākajiem pašreizējiem mākslīgā intelekta un mašīnmācības pētījumiem varētu tikt pakļauti tiesvedībai, tiklīdz tie kļūs komerciāli pamanāmi, jo datu kopas, kas padara iespējamus sasniegumus, tiek izplatītas ar nederīgiem. licences, kas neievēro sākotnējos noteikumus publiskajos domēnos, no kuriem tika iegūti dati.
Faktiski tam ir divi gandrīz neizbēgami iespējamie iznākumi: ļoti veiksmīgi, komercializēti mākslīgā intelekta algoritmi, kas, kā zināms, ir izmantojuši šādas datu kopas, kļūs par nākotnes mērķiem oportūnistiskajiem patentu troļļiem, kuru autortiesības netika ievērotas, kad viņu dati tika nokasīti; un ka organizācijas un privātpersonas varēs izmantot šīs pašas juridiskās ievainojamības, lai protestētu pret mašīnmācīšanās tehnoloģiju ieviešanu vai izplatīšanu, kas tām šķiet nevēlamas.
Jūsu darbs IR Klientu apkalpošana papīrs tiek nosaukts Vai varu izmantot šo publiski pieejamo datu kopu, lai izveidotu komerciālu AI programmatūru? Visticamāk, ka nē, un tā ir Huawei Canada un Huawei China sadarbība, kā arī Jorkas Universitāte Apvienotajā Karalistē un Viktorijas Universitāte Kanādā.
Piecas no sešām (populārajām) atvērtā pirmkoda datu kopām, kuras nav likumīgi lietojamas
Pētījuma veikšanai autori lūdza Huawei departamentus atlasīt vēlamākās atvērtā pirmkoda datu kopas, kuras viņi vēlētos izmantot komerciālos projektos, un no atbildēm izvēlējās sešas pieprasītākās datu kopas: CIFAR-10 (apakškopa no 80 miljoni mazu attēlu datu kopa, kopš atsaukts “zeminoši termini” un “aizvainojoši attēli”, lai gan to atvasinājumi vairojas); ImageNet; Pilsētas ainavas (kas satur tikai oriģinālo materiālu); FFHQ; VGGFace2, un MSCOCO.
Lai analizētu, vai atlasītās datu kopas ir piemērotas likumīgai izmantošanai komerciālos projektos, autori izstrādāja jaunu konveijeru, lai izsekotu licenču ķēdei, cik vien tas bija iespējams katrai kopai, lai gan bieži vien viņiem bija jāizmanto tīmekļa arhīvu tveršana. atrast licences no domēniem, kuru derīguma termiņš ir beidzies, un atsevišķos gadījumos nācies "uzminēt" licences statusu no tuvākās pieejamās informācijas.
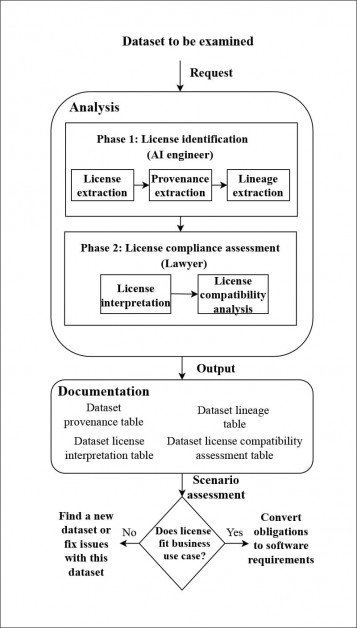
Autoru izstrādātā izcelsmes izsekošanas sistēmas arhitektūra. Avots: https://arxiv.org/pdf/2111.02374.pdf
Autori atklāja, ka licences piecām no sešām datu kopām “ir ietverti riski, kas saistīti ar vismaz vienu komerciālas lietošanas kontekstu”:
“[Mēs] novērojam, ka, izņemot MS COCO, neviena no pētītajām licencēm nedod praktizētājiem tiesības komercializēt mākslīgā intelekta modeli, kas apmācīts, pamatojoties uz apmācītā AI modeļa datiem vai pat izvadi. Šāds rezultāts arī efektīvi neļauj praktiķiem pat izmantot iepriekš apmācītus modeļus, kas apmācīti šajās datu kopās. Ir publiski pieejamas datu kopas un mākslīgā intelekta modeļi, kas ir iepriekš apmācīti plaši izmanto komerciāli.' *
Autori arī atzīmē, ka trīs no sešām pētītajām datu kopām var papildus izraisīt licences pārkāpumus komerciālos produktos, ja datu kopa tiek modificēta, jo to atļauj tikai MS-COCO. Tomēr datu papildināšana un ietekmīgu datu kopu apakškopas un superkopas ir izplatīta prakse.
CIFAR-10 gadījumā sākotnējie kompilatori vispār neizveidoja nekādu parasto licences veidu, tikai prasīja, lai projektos, kuros izmanto datu kopu, būtu iekļauta atsauce uz sākotnējo dokumentu, kas pievienots datu kopas izlaišanai, radot papildu šķēršļus datu kopas izveidei. datu juridiskais statuss.
Turklāt tikai CityScapes datu kopā ir materiāls, ko ģenerē tikai datu kopas veidotāji, nevis tiek “kurēts” (nokopēts) no tīkla avotiem, CIFAR-10 un ImageNet izmantojot vairākus avotus, no kuriem katrs būtu jāizpēta. un izsekot, lai izveidotu jebkāda veida autortiesību mehānismu (vai pat jēgpilnu atrunu).
Nav izeja
Šķiet, ka komerciālie mākslīgā intelekta uzņēmumi paļaujas uz trim faktoriem, lai pasargātu tos no tiesvedības saistībā ar produktiem, kuros AI algoritmu apmācībai brīvi un bez atļaujas ir izmantots ar autortiesībām aizsargāts datu kopu saturs. Neviens no tiem nesniedz lielu (vai nekādu) uzticamu ilgtermiņa aizsardzību:
1: Laissez Faire nacionālie likumi
Lai gan valdības visā pasaulē ir spiestas mīkstināt likumus par datu skrāpēšanu, cenšoties neatkāpties sacīkstēs par veiktspējīgu AI (kas balstās uz lielu reālās pasaules datu apjomu, kam regulāra autortiesību ievērošana un licencēšana būtu nereāla), tikai ASV šajā ziņā piedāvā pilnvērtīgu imunitāti saskaņā ar Godīgas lietošanas doktrīna – politika, kas tika ratificēta 2015. gadā ar secinājums Autoru ģilde pret Google, Inc., kas apstiprināja, ka meklēšanas gigants var brīvi pārņemt ar autortiesībām aizsargātu materiālu savam Google grāmatu projektam, neapsūdzot pārkāpumā.
Ja godīgas izmantošanas doktrīnas politika kādreiz mainīsies (ti, reaģējot uz citu nozīmīgu gadījumu, kurā iesaistītas pietiekami spēcīgas organizācijas vai korporācijas), tas, visticamāk, tiks uzskatīts par priori valsts attiecībā uz pašreizējo autortiesības pārkāpjošo datubāzu izmantošanu, aizsargājot agrāko izmantošanu; bet ne nepārtraukts tādu sistēmu izmantošana un izstrāde, kuras tika iespējotas, izmantojot ar autortiesībām aizsargātu materiālu bez vienošanās.
Tādējādi pašreizējā godīgas izmantošanas doktrīnas aizsardzība ir ļoti provizoriska, un, iespējams, tādā gadījumā varētu būt nepieciešams, lai izveidotu, komercializētu mašīnmācīšanās algoritmu darbība tiktu pārtraukta gadījumos, kad to izcelsme tika nodrošināta ar autortiesībām aizsargātu materiālu, pat gadījumos, kad modeļa svari tagad nodarbojas tikai ar atļauto saturu, bet tika apmācīti par nelikumīgi kopētu saturu (un padarīti noderīgi).
Ārpus ASV, kā autori atzīmē jaunajā dokumentā, politika parasti ir mazāk saudzējoša. Apvienotā Karaliste un Kanāda atlīdzina tikai ar autortiesībām aizsargātu datu izmantošanu nekomerciālos nolūkos, savukārt ES Teksta un datu ieguves likums (kuru nav pilnībā ignorējis jaunākie priekšlikumi formālākam AI regulējumam) arī izslēdz komerciālu izmantošanu AI sistēmām, kas neatbilst sākotnējo datu autortiesību prasībām.
Šie pēdējie pasākumi nozīmē, ka organizācija var sasniegt lielus panākumus ar citu cilvēku datiem, līdz, bet neņemot vērā, ka ar tiem var nopelnīt. Šajā posmā produkts vai nu tiktu likumīgi atklāts, vai arī būtu jāsastāda vienošanās ar miljoniem autortiesību īpašnieku, no kuriem daudzi tagad nav izsekojami interneta mainīgā rakstura dēļ — neiespējama un nepieņemama izredze.
2: brīdinājums Emptor
Gadījumos, kad pārkāpējas organizācijas cer atlikt vainu, jaunajā dokumentā arī norādīts, ka daudzas populārāko atvērtā pirmkoda datu kopu licences automātiski kompensē sevi pret jebkādām pretenzijām par autortiesību pārkāpumu:
“Piemēram, ImageNet licence skaidri nosaka, ka praktiķiem ir jāatlīdzina ImageNet komandai jebkādas prasības, kas izriet no datu kopas izmantošanas. FFHQ, VGGFace2 un MS COCO datu kopām datu kopa, ja tā tiek izplatīta vai modificēta, ir jāuzrāda saskaņā ar vienu un to pašu licenci.
Faktiski tas liek tiem, kas izmanto FOSS datu kopas, uzņemties vainu par ar autortiesībām aizsargāta materiāla izmantošanu, saskaroties ar iespējamu tiesvedību (lai gan tas ne vienmēr aizsargā sākotnējos kompilatorus gadījumā, ja pastāv pašreizējais "drošības zonas" klimats).
3: Atlīdzība neskaidrības dēļ
Mašīnmācīšanās kopienas sadarbības raksturs apgrūtina korporatīvā okultisma izmantošanu, lai slēptu tādu algoritmu klātbūtni, kas ir guvuši labumu no autortiesības pārkāpjošām datu kopām. Ilgtermiņa komerciālie projekti bieži sākas atvērtās FOSS vidēs, kur datu kopu izmantošana ir reģistrēta, GitHub un citos publiski pieejamos forumos vai kur projekta izcelsme ir publicēta iepriekš izdrukātos vai recenzētos dokumentos.
Pat ja tas tā nav, modeļa inversija is arvien spējīgāks datu kopu tipisko īpašību atklāšana (vai pat skaidri izvadot daži no izejmateriāliem), vai nu sniedz pierādījumus par sevi, vai arī pietiekamas aizdomas par pārkāpumu, lai nodrošinātu ar tiesas rīkojumu piekļuvi algoritma izstrādes vēsturei un detalizētai informācijai par šajā izstrādē izmantotajām datu kopām.
Secinājumi
Rakstā ir attēlota bez atļaujas iegūta ar autortiesībām aizsargāta materiāla haotiska un ad hoc izmantošana, kā arī virkne licenču ķēžu, kam, loģiski sekojot līdz pat datu sākotnējai iegūšanai, būtu nepieciešamas sarunas ar tūkstošiem autortiesību īpašnieku, kuru darbs tika prezentēts. tādu vietņu aizgādībā, kurās ir daudz dažādu licencēšanas nosacījumu, daudzi izslēdzot atvasinātus komerciālus darbus.
Autori secina:
"Publiski pieejamas datu kopas tiek plaši izmantotas, lai izveidotu komerciālu AI programmatūru. To var izdarīt, ja [un] tikai tad, ja ar publiski pieejamo datu kopu saistītā licence nodrošina tiesības to darīt. Tomēr nav viegli pārbaudīt tiesības un pienākumus, kas paredzēti licencē, kas saistīta ar publiski pieejamām datu kopām. Jo dažreiz licence ir neskaidra vai potenciāli nederīga.
Vēl viens jauns darbs ar nosaukumu Juridisko datu kopu veidošana2. novembrī publicētais Singapūras Menedžmenta universitātes Aprēķinu tiesību centrs, arī uzsver, ka datu zinātniekiem ir jāatzīst, ka ad hoc datu vākšanas “mežonīgo rietumu” laikmets tuvojas noslēgumam, un atspoguļo Huawei ieteikumus. papīrs pieņemt stingrākus ieradumus un metodoloģijas, lai nodrošinātu, ka datu kopas izmantošana nepakļauj projektu juridiskām sekām, jo kultūra laika gaitā mainās un tā kā pašreizējā globālā akadēmiskā darbība mašīnmācīšanās sektorā cenšas komerciāli atpelnīt no gadu ieguldījumiem. . Autors atzīmē*:
“Tiesību aktu kopums, kas ietekmē ML datu kopas, palielināsies, ņemot vērā bažas, ka pašreizējie likumi piedāvā nepietiekama aizsardzības pasākumi. AIA projekts [ES Mākslīgā intelekta likums], ja un kad tas tiks pieņemts, tas būtiski mainītu mākslīgā intelekta un datu pārvaldības ainavu; citas jurisdikcijas var sekot līdzi saviem tiesību aktiem. '
* Mana iekļauto citātu pārvēršana par hipersaitēm















