
Dirbtinis intelektas
Kompiuterinio matymo modelių mokymas naudojant atsitiktinį triukšmą, o ne tikrus vaizdus

Tyrėjai iš MIT kompiuterių mokslo ir dirbtinio intelekto laboratorijos (CSAIL) eksperimentavo su atsitiktinio triukšmo vaizdų naudojimu kompiuterinės regos duomenų rinkiniuose, kad mokytų kompiuterinio matymo modelius, ir nustatė, kad užuot gaminęs šiukšles, šis metodas yra stebėtinai efektyvus:

Generatyvieji modeliai iš eksperimento, surūšiuoti pagal našumą. Šaltinis: https://openreview.net/pdf?id=RQUl8gZnN7O
Akivaizdžios „vaizdinės šiukšlės“ įtraukimas į populiarias kompiuterinės vizijos architektūras neturėtų sukelti tokio našumo. Aukščiau esančio vaizdo dešinėje pusėje juodi stulpeliai rodo tikslumo balus (įjungta Imagenet-100) keturiems „tikriesiems“ duomenų rinkiniams. Nors prieš jį esantys „atsitiktinio triukšmo“ duomenų rinkiniai (pavaizduoti įvairiomis spalvomis, žr. rodyklę viršuje kairėje) to negali atitikti, dėl tikslumo jie beveik visi yra gerbiamose viršutinėse ir apatinėse ribose (raudonos punktyrinės linijos).
Šia prasme „tikslumas“ nereiškia, kad rezultatas būtinai atrodo kaip a padaryti, bažnyčia, pica, arba bet kurį kitą konkretų domeną, kuriam jums gali būti įdomu sukurti vaizdo sintezė sistema, pvz., generacinis priešpriešinis tinklas arba kodavimo / dekodavimo sistema.
Atvirkščiai, tai reiškia, kad CSAIL modeliai iš vaizdų duomenų išvedė plačiai taikomas pagrindines „tiesas“, kurios, matyt, yra nestruktūruotos, kad neturėtų būti pajėgios jų pateikti.
Įvairovė vs. Natūralizmas
Šių rezultatų taip pat negalima priskirti per daug tinka: gyvas diskusija „Open Review“ autoriai ir recenzentai atskleidžia, kad skirtingo turinio iš vizualiai skirtingų duomenų rinkinių (tokių kaip „negyvi lapai“, „fraktalai“ ir „procedūrinis triukšmas“ – žr. paveikslėlį žemiau) maišymas į mokymo duomenų rinkinį. tikrai pagerina tikslumas šiuose eksperimentuose.
Tai rodo (ir tai yra šiek tiek revoliucinga) naujo tipo „nepakankamo pritaikymo“, kai „įvairovė“ pranoksta „natūralumą“.
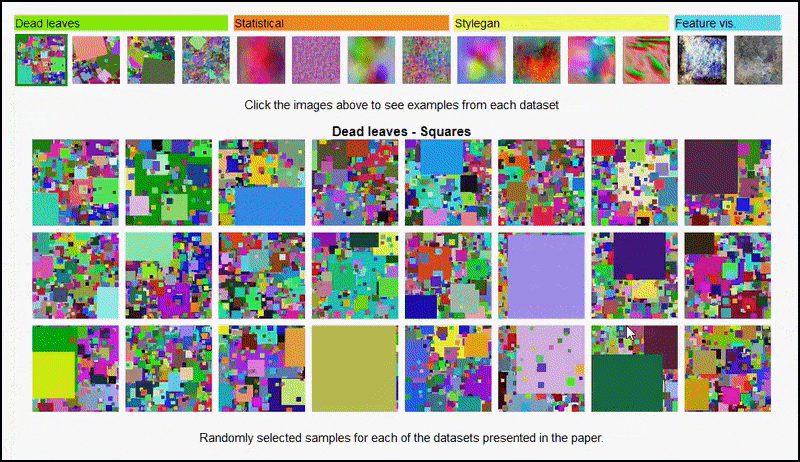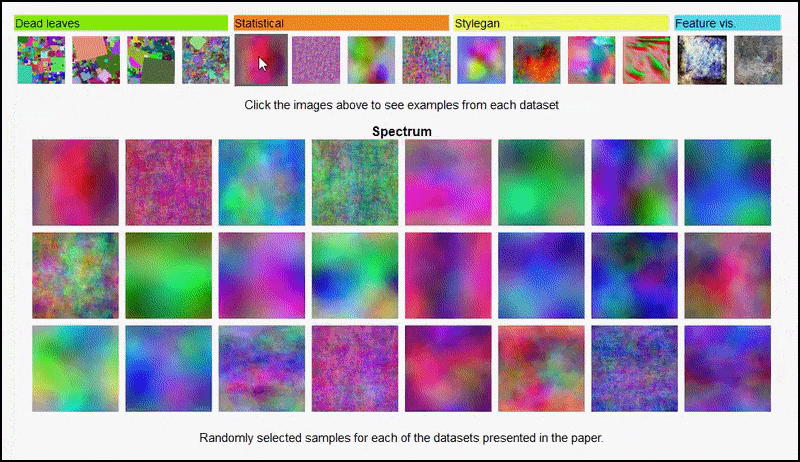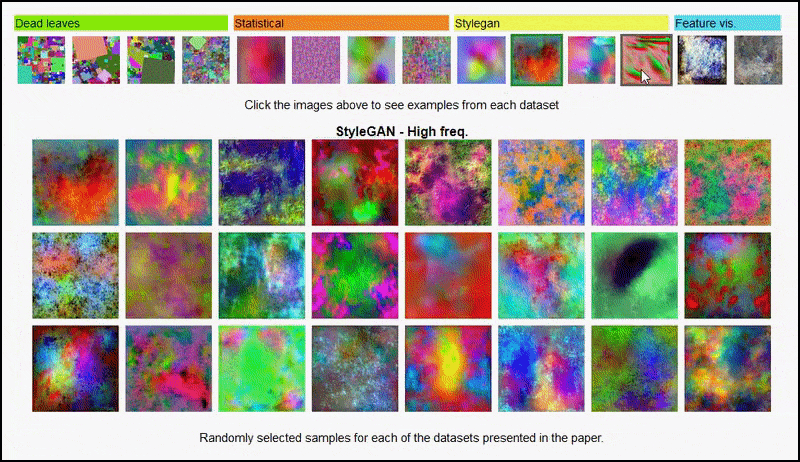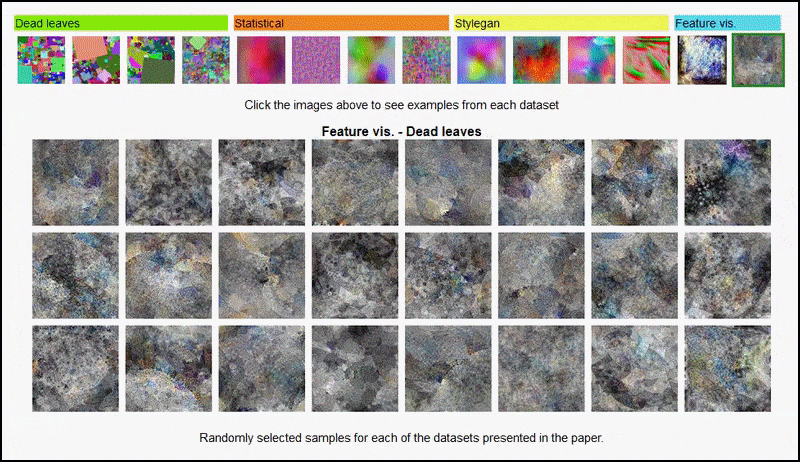
Šios Projekto puslapis Iniciatyva leidžia interaktyviai peržiūrėti įvairių tipų atsitiktinių vaizdų duomenų rinkinius, naudojamus eksperimente. Šaltinis: https://mbaradad.github.io/learning_with_noise/
Mokslininkų gauti rezultatai verčia suabejoti pamatiniu ryšiu tarp vaizdais pagrįstų neuroninių tinklų ir „realaus pasaulio“ vaizdų, kurie jiems kelia nerimą. didesni kiekiai kiekvienais metais ir reiškia, kad reikia gauti, kuruoti ir kitaip ginčytis hiperskalės vaizdų duomenų rinkiniai ilgainiui gali tapti nereikalingas. Autoriai teigia:
„Dabartinės regėjimo sistemos yra apmokytos naudojant didžiulius duomenų rinkinius, o šie duomenų rinkiniai kainuoja: tvarkymas yra brangus, jie paveldi žmogaus šališkumą ir yra susirūpinimas dėl privatumo ir naudojimo teisių. Siekiant sumažinti šias išlaidas, išaugo susidomėjimas mokytis iš pigesnių duomenų šaltinių, pavyzdžiui, nepažymėtų vaizdų.
„Šiame dokumente žengiame dar vieną žingsnį ir klausiame, ar galime visiškai atsisakyti tikrų vaizdo duomenų rinkinių, mokydamiesi iš procedūrinių triukšmo procesų.
Tyrėjai teigia, kad dabartinis mašininio mokymosi architektūrų derinys iš vaizdų gali daryti išvadą apie ką nors daug svarbesnio (arba bent jau netikėto), nei manyta anksčiau, ir kad „nesąmoningi“ vaizdai gali suteikti daug daugiau šių žinių. pigiai, net naudojant ad hoc sintetinius duomenis, naudojant duomenų rinkinio generavimo architektūras, kurios treniruočių metu generuoja atsitiktinius vaizdus:
"Mes nustatome dvi pagrindines savybes, kurios leidžia gauti gerus sintetinius duomenis regėjimo sistemoms lavinti: 1) natūralumą, 2) įvairovę. Įdomu tai, kad natūralistiškiausi duomenys ne visada yra geriausi, nes natūralizmas gali kainuoti įvairovę.
„Faktas, kad natūralistiniai duomenys padeda, gali nestebinti, ir tai rodo, kad iš tikrųjų didelės apimties realūs duomenys turi vertę. Tačiau mes pastebime, kad svarbiausia ne tai, kad duomenys būtų tikras bet kad taip būtų natūralistinisty turi užfiksuoti tam tikras realių duomenų struktūrines savybes.
„Daugelį šių savybių galima užfiksuoti paprastuose triukšmo modeliuose.

Funkcijų vizualizacijos, gautos naudojant AlexNet gautą koduotuvą kai kuriuose iš įvairių autorių naudojamų „atsitiktinių vaizdų“ duomenų rinkinių, apimančių 3 ir 5 (paskutinį) konvoliucijos sluoksnius. Čia naudojama metodika yra tokia, kaip nurodyta Google AI tyrimai nuo 2017 m.
Šios popierius, pristatytas 35-ojoje neuroninių informacijos apdorojimo sistemų konferencijoje (NeurIPS 2021) Sidnėjuje, pavadintas Mokymasis matyti žiūrint į triukšmą, ir yra iš šešių CSAIL mokslininkų, kurių indėlis yra vienodas.
Darbas buvo rekomenduojama bendru sutarimu dėl NeurIPS 2021 atrankos dėmesio centre, o kolegos komentatoriai apibūdino straipsnį kaip „mokslinį proveržį“, atveriantį „didelę studijų sritį“, net jei kyla tiek klausimų, kiek atsakymų.
Straipsnyje autoriai daro išvadas:
„Mes parodėme, kad sukūrus naudojant ankstesnių natūralių vaizdų statistikos tyrimų rezultatus, šie duomenų rinkiniai gali sėkmingai parengti vizualinius vaizdus. Tikimės, kad šis dokumentas paskatins tirti naujus generatyvius modelius, galinčius sukurti struktūrinį triukšmą ir pasiekti dar didesnį našumą atliekant įvairias vizualines užduotis.
„Ar būtų įmanoma suderinti našumą, gautą naudojant „ImageNet“ išankstinį mokymą? Galbūt, jei nėra didelio tam tikrai užduočiai skirto mokymo rinkinio, geriausias išankstinis mokymas gali būti ne naudojant standartinį tikrą duomenų rinkinį, pvz., „ImageNet“.















