
Dirbtinis intelektas
InstructIR: aukštos kokybės vaizdo atkūrimas pagal žmogaus nurodymus

Vaizdas gali perteikti labai daug, tačiau jį taip pat gali pažeisti įvairios problemos, pvz., judesio susiliejimas, migla, triukšmas ir mažas dinaminis diapazonas. Šios problemos, paprastai vadinamos žemo lygio kompiuterinio matymo pablogėjimu, gali kilti dėl sudėtingų aplinkos sąlygų, pvz., karščio ar lietaus, arba dėl pačios fotoaparato apribojimų. Vaizdo atkūrimas yra pagrindinis kompiuterinio regėjimo iššūkis, siekiant atkurti aukštos kokybės, švarų vaizdą iš tokio pablogėjimo. Vaizdo atkūrimas yra sudėtingas, nes gali būti keli sprendimai, kaip atkurti bet kurį vaizdą. Kai kurie metodai yra skirti tam tikram pablogėjimui, pvz., sumažinti triukšmą arba pašalinti neryškumą ar miglą.
Nors šie metodai gali duoti gerų rezultatų sprendžiant konkrečias problemas, jie dažnai stengiasi apibendrinti įvairius degradacijos tipus. Daugelyje sistemų naudojamas bendrasis neuroninis tinklas įvairioms vaizdų atkūrimo užduotims atlikti, tačiau kiekvienas iš šių tinklų apmokomas atskirai. Dėl skirtingų modelių, skirtų kiekvienam degradacijos tipui, šis metodas yra brangus ir reikalaujantis daug laiko, todėl pastaruoju metu dėmesys sutelkiamas į „viskas viename“ atkūrimo modelius. Šie modeliai naudoja vieną, giliai aklų atkūrimo modelį, kuris sprendžia kelis degradacijos lygius ir tipus, dažnai naudojant specifinius degradacijos raginimus arba orientacinius vektorius, kad pagerintų našumą. Nors „viskas viename“ modeliai paprastai rodo daug žadančius rezultatus, jie vis tiek susiduria su iššūkiais, susijusiais su atvirkštinėmis problemomis.
„InstructIR“ yra pirmasis šioje srityje novatoriškas požiūris vaizdo atkūrimas sistema, sukurta vadovautis atkūrimo modeliu pagal žmogaus rašytas instrukcijas. Jis gali apdoroti natūralios kalbos raginimus, kad atkurtų aukštos kokybės vaizdus iš pablogėjusių, atsižvelgiant į įvairius pablogėjimo tipus. „InstructIR“ nustato naują našumo standartą atliekant įvairias vaizdo atkūrimo užduotis, įskaitant vaizdų sumažinimą, triukšmo mažinimą, miglotumą, suliejimą ir gerinimą esant prastam apšvietimui.
Šio straipsnio tikslas yra išsamiai apžvelgti „InstructIR“ sistemą, o mes tyrinėjame mechanizmą, metodiką, sistemos architektūrą ir palyginame ją su naujausiomis vaizdo ir vaizdo įrašų generavimo sistemomis. Taigi pradėkime.
InstructIR: aukštos kokybės vaizdo atkūrimas
Vaizdo atkūrimas yra pagrindinė kompiuterinio regėjimo problema, nes juo siekiama atkurti aukštos kokybės švarų vaizdą iš vaizdo, kuriame rodomas pablogėjimas. Žemo lygio kompiuterinio regėjimo atveju pablogėjimai yra terminas, naudojamas apibūdinti nemalonius vaizde pastebėtus efektus, tokius kaip judesio susiliejimas, migla, triukšmas, mažas dinaminis diapazonas ir kt. Priežastis, kodėl vaizdo atkūrimas yra sudėtingas atvirkštinis iššūkis, yra ta, kad bet kuriam vaizdui atkurti gali būti keli skirtingi sprendimai. Kai kuriose sistemose daugiausia dėmesio skiriama tam tikriems pablogėjimams, pvz., triukšmo mažinimui arba vaizdo triukšmo mažinimui, o kitose gali būti daugiau dėmesio skirta suliejimo ar suliejimo pašalinimui arba miglos ar miglos pašalinimui.
Naujausi gilaus mokymosi metodai parodė stipresnį ir nuoseklesnį našumą, palyginti su tradiciniais vaizdo atkūrimo metodais. Šie gilaus mokymosi vaizdo atkūrimo modeliai siūlo naudoti neuroninius tinklus, pagrįstus transformatoriais ir konvoliuciniais neuroniniais tinklais. Šiuos modelius galima apmokyti savarankiškai atlikti įvairias vaizdo atkūrimo užduotis, be to, jie turi galimybę užfiksuoti vietinę ir pasaulinę funkcijų sąveiką ir jas pagerinti, todėl jų veikimas yra patenkinamas ir nuoseklus. Nors kai kurie iš šių metodų gali tinkamai veikti esant tam tikroms skilimo rūšims, jie paprastai nėra gerai ekstrapoliuojami į skirtingus degradacijos tipus. Be to, nors daugelis esamų sistemų naudoja tą patį neuroninį tinklą daugybei vaizdo atkūrimo užduočių, kiekviena neuroninio tinklo formuluotė apmokoma atskirai. Taigi akivaizdu, kad naudoti atskirą neuroninį modelį kiekvienam galimam degradavimui yra nepraktiška ir atima daug laiko, todėl naujausi vaizdo atkūrimo sistemos buvo sutelktos į „viskas viename“ atkūrimo tarpinius serverius.
Kompiuterinio regėjimo lauke populiarėja „viskas viename“ arba kelių degradacijos ar kelių užduočių vaizdo atkūrimo modeliai, nes jie gali atkurti kelių tipų ir lygių vaizdo pablogėjimą, nereikia atskirai mokyti modelių dėl kiekvieno pablogėjimo. . „Viskas viename“ vaizdo atkūrimo modeliuose naudojamas vienas giliai aklųjų vaizdo atkūrimo modelis, skirtas įvairių tipų ir lygių vaizdo pablogėjimui įveikti. Skirtingi „viskas viename“ modeliai taiko skirtingus metodus, kaip nukreipti akląjį modelį atkurti pablogintą vaizdą, pavyzdžiui, pagalbinį modelį, skirtą pablogėjimui klasifikuoti, arba daugiamačius orientacinius vektorius arba raginimus, padedančius modeliui atkurti skirtingus pablogėjimo tipus. vaizdas.
Tai pasakius, pasiekiame teksto pagrįstą vaizdo manipuliavimą, nes per pastaruosius kelerius metus jis buvo įgyvendintas keliose sistemose, skirtose teksto į vaizdą generavimui ir teksto vaizdo redagavimo užduotims. Šie modeliai dažnai naudoja tekstinius raginimus, kad apibūdintų veiksmus ar vaizdus difuzija pagrįsti modeliai kad sukurtumėte atitinkamus vaizdus. Pagrindinis „InstructIR“ sistemos įkvėpimas yra „InstructPix2Pix“ sistema, leidžianti modeliui redaguoti vaizdą naudojant vartotojo instrukcijas, kurios nurodo modeliui, kokį veiksmą atlikti, o ne įvesties vaizdo tekstines etiketes, aprašymus ar antraštes. Todėl vartotojai gali naudoti natūralius rašytinius tekstus, kad nurodytų modeliui, kokį veiksmą atlikti, nepateikdami pavyzdinių vaizdų ar papildomų vaizdų aprašymų.
Remiantis šiais pagrindais, InstructIR sistema yra pirmasis kompiuterinio matymo modelis, kuriame naudojamos žmogaus parašytos instrukcijos, kad būtų galima atkurti vaizdą ir išspręsti atvirkštines problemas. Natūralios kalbos raginimų atveju InstructIR modelis gali atkurti aukštos kokybės vaizdus iš pablogėjusių analogų ir taip pat atsižvelgia į kelis pablogėjimo tipus. „InstructIR“ sistema gali užtikrinti pažangiausią našumą atliekant įvairias vaizdo atkūrimo užduotis, įskaitant vaizdo sugadinimą, triukšmo mažinimą, miglotumą, suliejimą ir vaizdo pagerinimą esant prastam apšvietimui. Skirtingai nuo esamų darbų, kuriuose vaizdas atkuriamas naudojant išmoktus orientacinius vektorius arba raginimus įterpti, InstructIR sistemoje naudojami neapdoroti vartotojo raginimai teksto forma. „InstructIR“ sistema gali apibendrinti vaizdų atkūrimą naudojant žmogaus rašytines instrukcijas, o „InstructIR“ įdiegtas vienas „viskas viename“ modelis apima daugiau atkūrimo užduočių nei ankstesni modeliai. Toliau pateiktame paveikslėlyje pavaizduoti įvairūs InstructIR sistemos atkūrimo pavyzdžiai.

InstructIR: metodas ir architektūra
Iš esmės „InstructIR“ sistemą sudaro teksto koduotuvas ir vaizdo modelis. Modelis naudoja NAFNet sistemą – efektyvų vaizdo atkūrimo modelį, kuris kaip vaizdo modelis atitinka U-Net architektūrą. Be to, modelis įgyvendina užduočių nukreipimo metodus, kad sėkmingai išmoktų kelias užduotis naudojant vieną modelį. Toliau pateiktame paveikslėlyje parodytas „InstructIR“ sistemos mokymo ir vertinimo metodas.

Semdamasi įkvėpimo iš InstructPix2Pix modelio, InstructIR sistema kaip valdymo mechanizmą priima žmogaus rašytines instrukcijas, nes vartotojui nereikia teikti papildomos informacijos. Šios instrukcijos siūlo išraiškingą ir aiškų sąveikos būdą, leidžiantį naudotojams nurodyti tikslią vaizdo pablogėjimo vietą ir tipą. Be to, naudojant vartotojo raginimus vietoj fiksuotų pablogėjimo konkrečių raginimų, modelio patogumas ir pritaikymas pagerėja, nes juo taip pat gali naudotis vartotojai, neturintys reikiamos srities patirties. Kad InstructIR sistema galėtų suprasti įvairius raginimus, modelis naudoja GPT-4 – didelį kalbos modelį, skirtą įvairioms užklausoms kurti, o dviprasmiški ir neaiškūs raginimai pašalinami po filtravimo proceso.
Teksto kodavimo priemonė
Teksto koduotuvas naudojamas kalbų modeliuose, siekiant susieti vartotojo raginimus su teksto įterpimu arba fiksuoto dydžio vektoriniu vaizdu. Tradiciškai teksto kodavimo priemonė a CLIP modelis yra gyvybiškai svarbus teksto vaizdų generavimo ir teksto pagrįstų vaizdo manipuliavimo modelių komponentas, skirtas koduoti vartotojo raginimus, nes CLIP sistema puikiai tinka vaizdiniams raginimams. Tačiau dažniausiai vartotojo raginimai pabloginti vaizdinį turinį yra mažai arba visai nėra, todėl dideli CLIP koduotuvai tampa nenaudingi tokioms užduotims atlikti, nes tai labai sumažins efektyvumą. Kad išspręstų šią problemą, InstructIR sistema pasirenka tekstinį sakinių kodavimo įrenginį, kuris yra išmokytas koduoti sakinius prasmingoje įterpimo erdvėje. Sakinių kodavimo įrenginiai yra iš anksto parengti remiantis milijonais pavyzdžių, tačiau yra kompaktiški ir veiksmingi, palyginti su tradiciniais CLIP pagrįstais teksto kodavimo įrenginiais, tuo pačiu galintys užkoduoti įvairių vartotojų raginimų semantiką.
Teksto vadovas
Pagrindinis InstructIR sistemos aspektas yra užkoduotos instrukcijos kaip vaizdo modelio valdymo mechanizmo įgyvendinimas. Remiantis tuo ir įkvėpta užduočių nukreipimo daugeliui užduočių mokymosi metu, InstructIR sistema siūlo instrukcijų kūrimo bloką arba ICB, kad būtų galima atlikti konkrečias užduotis modelio transformacijas. Įprastas užduočių nukreipimas kanalo funkcijoms taiko konkrečiai užduočių dvejetaines kaukes. Tačiau kadangi „InstructIR“ sistema nežino degradacijos, ši technika nėra tiesiogiai įgyvendinama. Be to, vaizdo funkcijoms ir koduotoms instrukcijoms „InstructIR“ sistema taiko užduočių maršrutą ir sukuria kaukę naudodama linijinį sluoksnį, suaktyvintą naudojant „Sigmoid“ funkciją, kad būtų sukurtas svorių rinkinys, atsižvelgiant į teksto įterpimus, ir taip gaunamas c matmuo. kanalo dvejetainė kaukė. Modelis dar labiau patobulina kondicionuotas funkcijas, naudodamas NAFBlock, ir naudoja NAFBlock ir Instruction Conditioned Block, kad nustatytų funkcijas tiek kodavimo bloke, tiek dekoderio bloke.
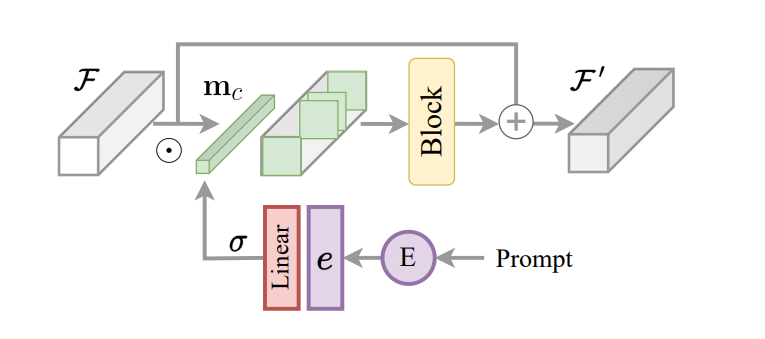
Nors „InstructIR“ sistema aiškiai nenustato neuroninių tinklų filtrų, kaukė palengvina modelį, leidžiantį pasirinkti tinkamiausius kanalus, remiantis vaizdo instrukcijomis ir informacija.
InstructIR: įgyvendinimas ir rezultatai
„InstructIR“ modelis yra apmokomas nuo galo iki galo, o vaizdo modeliui nereikia išankstinio mokymo. Išmokyti reikia tik teksto įterpimo projekcijas ir klasifikavimo galvutę. Teksto kodavimo priemonė inicijuojama naudojant BGE koduotuvą, į BERT panašų kodavimo įrenginį, kuris yra iš anksto paruoštas didžiuliam prižiūrimų ir neprižiūrimų duomenų kiekiui, kad būtų galima koduoti sakinius. InstructIR sistema naudoja NAFNet modelį kaip vaizdo modelį, o NAFNet architektūrą sudaro 4 lygių kodavimo dekoderis su skirtingu blokų skaičiumi kiekviename lygyje. Modelis taip pat prideda 4 vidurinius blokus tarp kodavimo įrenginio ir dekoderio, kad dar labiau pagerintų funkcijas. Be to, užuot sujungęs praleidimo jungtis, dekoderis įgyvendina pridėjimą, o „InstructIR“ modelis įgyvendina tik ICB arba instrukcijų sąlyginį bloką užduočių nukreipimui tik koduotoje ir dekoderyje. Toliau „InstructIR“ modelis optimizuojamas naudojant nuostolius tarp atkurto vaizdo ir švaraus pagrindinio vaizdo, o kryžminės entropijos praradimas naudojamas teksto kodavimo įrenginio ketinimų klasifikavimo galvutei. „InstructIR“ modelyje naudojamas „AdamW“ optimizatorius, kurio partijos dydis yra 32, o mokymosi greitis yra 5e–4 beveik 500 epochų, taip pat įgyvendinamas kosinuso atkaitinimo mokymosi greičio mažėjimas. Kadangi vaizdo modelis InstructIR sistemoje apima tik 16 milijonų parametrų, o išmoktų teksto projekcijos parametrų yra tik 100 tūkstančių, InstructIR karkasą galima lengvai apmokyti naudojant standartinius GPU, taip sumažinant skaičiavimo išlaidas ir padidinant pritaikomumą.
Keli degradacijos rezultatai
Daugkartinio pablogėjimo ir kelių užduočių atkūrimo atveju InstructIR sistema apibrėžia dvi pradines sąrankas:
- 3D, skirtas trijų degradacijų modeliams, kad būtų išspręstos degradacijos problemos, pvz., gesinimas, triukšmo slopinimas ir žeminimas.
- 5D, skirtas penkiems blogėjimo modeliams, kad būtų išspręstos blogėjimo problemos, pvz., vaizdo triukšmo mažinimas, prasto apšvietimo patobulinimai, triukšmo mažinimas, triukšmo slopinimas ir nualinimas.
5D modelių veikimas parodytas šioje lentelėje ir lyginamas su naujausiais vaizdo atkūrimo ir „viskas viename“ modeliais.

Kaip galima pastebėti, InstructIR sistema su paprastu vaizdo modeliu ir tik 16 milijonų parametrų gali sėkmingai atlikti penkias skirtingas vaizdo atkūrimo užduotis dėl instrukcijomis pagrįstų nurodymų ir duoda konkurencingų rezultatų. Toliau pateiktoje lentelėje parodytas sistemos veikimas 3D modeliuose, o rezultatai yra palyginami su aukščiau pateiktais rezultatais.

Pagrindinis „InstructIR“ sistemos akcentas yra instrukcijomis pagrįstas vaizdo atkūrimas, o toliau pateiktame paveikslėlyje pavaizduoti neįtikėtini „InstructIR“ modelio gebėjimai suprasti įvairias tam tikros užduoties instrukcijas. Be to, priešpriešinio nurodymo atveju InstructIR modelis atlieka tapatybę, kuri nėra priverstinė.

Baigiamosios mintys
Vaizdo atkūrimas yra pagrindinė kompiuterinio regėjimo problema, nes juo siekiama atkurti aukštos kokybės švarų vaizdą iš vaizdo, kuriame rodomas pablogėjimas. Žemo lygio kompiuterinio regėjimo atveju pablogėjimai yra terminas, naudojamas apibūdinti nemalonius vaizde pastebėtus efektus, tokius kaip judesio susiliejimas, migla, triukšmas, mažas dinaminis diapazonas ir kt. Šiame straipsnyje kalbėjome apie „InstructIR“ – pirmąją pasaulyje vaizdo atkūrimo sistemą, kurios tikslas – vadovautis vaizdo atkūrimo modeliu naudojant žmogaus rašytas instrukcijas. Natūralios kalbos raginimų atveju InstructIR modelis gali atkurti aukštos kokybės vaizdus iš pablogėjusių analogų ir taip pat atsižvelgia į kelis pablogėjimo tipus. „InstructIR“ sistema gali užtikrinti pažangiausią našumą atliekant įvairias vaizdo atkūrimo užduotis, įskaitant vaizdo sugadinimą, triukšmo mažinimą, miglotumą, suliejimą ir vaizdo pagerinimą esant prastam apšvietimui.















