
Geriausi
10 geriausių mašininio mokymosi algoritmų
Nors išgyvename nepaprastų GPU pagreitinto mašininio mokymosi naujovių laikotarpį, naujausiuose moksliniuose darbuose dažnai (ir aiškiai) pateikiami dešimtmečius, kai kuriais atvejais 70 metų senumo algoritmai.
Kai kas gali ginčytis, kad daugelis šių senesnių metodų patenka į „statistinės analizės“, o ne mašininio mokymosi stovyklą, ir pageidauja, kad sektorius atsirado tik 1957 m. Perceptrono išradimas.
Atsižvelgiant į tai, kiek šie senesni algoritmai palaiko ir yra įtraukiami į naujausias mašininio mokymosi tendencijas ir antraštes pritraukiančius pokyčius, tai yra ginčijama pozicija. Taigi pažvelkime į kai kuriuos „klasikinius“ blokus, kuriais grindžiamos naujausios naujovės, ir kai kuriuos naujesnius įrašus, kurie anksti pretenduoja į AI šlovės muziejų.
1: Transformeriai
2017 m. „Google Research“ vadovavo bendradarbiavimui mokslinių tyrimų srityje, kurio kulminacija buvo popierius Dėmesio – tai viskas, ko jums reikia. Darbe apibūdinta nauja architektūra, kuri skatino dėmesio mechanizmai nuo „vamzdžių“ kodavimo/dekoderio ir pasikartojančių tinklo modelių iki atskiros centrinės transformacijos technologijos.
Prieiga buvo pavadinta Transformatorius, ir nuo to laiko tapo revoliucine natūralios kalbos apdorojimo (NLP) metodika, kuri, be daugelio kitų pavyzdžių, naudoja autoregresyvų kalbos modelį ir AI plakatą GPT-3.
![]()
Transformatoriai elegantiškai išsprendė problemą sekos transdukcija, dar vadinama „transformacija“, kuri skirta įvesties sekų apdorojimui į išvesties sekas. Transformatorius taip pat gauna ir tvarko duomenis nepertraukiamai, o ne nuosekliai, todėl „atminties išlikimas“, kurio gauti RNN architektūros nėra skirtos. Norėdami gauti išsamesnę transformatorių apžvalgą, žiūrėkite mūsų informacinis straipsnis.
Priešingai nei pasikartojantys neuroniniai tinklai (RNN), kurie pradėjo dominuoti ML tyrimuose CUDA eroje, transformatoriaus architektūra taip pat gali būti lengvai naudojama. lygiagretus, atverdamas kelią produktyviai apdoroti daug didesnį duomenų korpusą nei RNN.
Populiarus naudojimas
2020 m. „Transformeriai“ sužavėjo visuomenės vaizduotę, kai buvo išleistas „OpenAI“ GPT-3, kuris pasižymėjo tuo metu rekordiniu 175 milijardai parametrų. Šį akivaizdžiai stulbinantį pasiekimą galiausiai užgožė vėlesni projektai, tokie kaip 2021 m. išlaisvinti Microsoft Megatron-Turing NLG 530B, kuris (kaip rodo pavadinimas) turi daugiau nei 530 milijardų parametrų.

Hipermastelių transformatoriaus NLP projektų laiko juosta. šaltinis: "Microsoft"
Transformatorių architektūra taip pat perėjo nuo NLP prie kompiuterinės vizijos, tiekdama a nauja karta vaizdų sintezės sistemų, tokių kaip OpenAI CLIP ir DALL-E, kurios naudoja teksto>vaizdo domeno susiejimą, kad užbaigtų neužbaigtus vaizdus ir susintetintų naujus vaizdus iš apmokytų domenų, tarp vis daugiau susijusių programų.

DALL-E bando užbaigti dalinį Platono biusto vaizdą. Šaltinis: https://openai.com/blog/dall-e/
2: generatyvūs priešpriešiniai tinklai (GAN)
Nors transformatoriai sulaukė ypatingo žiniasklaidos dėmesio, kai buvo išleistas ir priimtas GPT-3, Generacinis prieštaringų tinklas (GAN) tapo atskiru atpažįstamu prekės ženklu ir galiausiai gali prisijungti deepfake kaip veiksmažodis.
Pirmą kartą pasiūlė į 2014 ir pirmiausia naudojamas vaizdo sintezei, generatyviniam priešpriešiniam tinklui architektūra yra sudarytas iš Generatorius ir Diskriminatorius. Generatorius peržiūri tūkstančius vaizdų duomenų rinkinyje, kartodamas bandydamas juos atkurti. Kiekvienam bandymui Diskriminatorius įvertina generatoriaus darbą ir siunčia generatorių atgal, kad jis padarytų geriau, tačiau nesuvokdamas, kaip suklydo ankstesnė rekonstrukcija.

Šaltinis: https://developers.google.com/machine-learning/gan/gan_structure
Tai verčia generatorių tyrinėti daugybę būdų, užuot sekus galimais akligatviais, kurie būtų pasibaigę, jei Diskriminatorius būtų jam pasakęs, kur buvo negerai (žr. #8 žemiau). Pasibaigus mokymui, generatorius turi išsamų ir išsamų ryšių tarp duomenų rinkinio taškų žemėlapį.

Iš popieriaus GAN pusiausvyros gerinimas didinant erdvinį suvokimą: nauja sistema cirkuliuoja per kartais paslaptingą latentinę GAN erdvę, suteikdama reaguojantį įrankį vaizdo sintezės architektūrai. Šaltinis: https://genforce.github.io/eqgan/
Pagal analogiją, tai yra skirtumas tarp mokymosi niūriai važinėti į Londono centrą ar kruopštaus mokymosi Žinios.
Rezultatas – aukšto lygio funkcijų rinkinys treniruoto modelio latentinėje erdvėje. Aukšto lygio ypatybės semantinis rodiklis gali būti „asmuo“, o nusileidimas per specifiškumą, susijusį su savybe, gali atskleisti kitas išmoktas savybes, tokias kaip „vyras“ ir „moteris“. Žemesniuose lygiuose antriniai bruožai gali suskaidyti į „blondinę“, „kaukazietišką“ ir kt.
Susipainiojimas yra pastebimas klausimas latentinėje GAN ir kodavimo/dekodavimo sistemų erdvėje: ar šypsena GAN sukurtoje moters veide yra jos „tapatybės“ latentinėje erdvėje įpainiotas bruožas, ar tai lygiagreti šaka?

GAN sukurtų šio asmens veidų neegzistuoja. Šaltinis: https://this-person-does-not-exist.com/en
Per pastaruosius porą metų atsirado vis daugiau naujų mokslinių tyrimų iniciatyvų šiuo atžvilgiu, galbūt atveriančių kelią funkcijų lygio, Photoshop stiliaus redagavimui latentinėje GAN erdvėje, tačiau šiuo metu daugelis transformacijų yra veiksmingos. viskas arba nieko“ paketai. Pažymėtina, kad 2021 m. pabaigoje išleistas NVIDIA EditGAN leidimas pasiekė a aukštas aiškinamumo lygis latentinėje erdvėje naudojant semantines segmentavimo kaukes.
Populiarus naudojimas
Be jų (iš tikrųjų gana riboto) dalyvavimo populiariuose netikruose vaizdo įrašuose, į vaizdus / vaizdo įrašus orientuotų GAN per pastaruosius ketverius metus išaugo, sužavėdami tyrėjus ir visuomenę. Neatsilikti nuo svaiginančio naujų leidimų greičio ir dažnumo yra iššūkis, nors „GitHub“ saugykla Nuostabios GAN programos siekiama pateikti išsamų sąrašą.
Teoriškai generatyvūs priešpriešiniai tinklai gali turėti savybių iš bet kurio gerai įrėminto domeno, įskaitant tekstą.
3: SVM
Kilęs į 1963, Palaikykite vektorinę mašiną (SVM) yra pagrindinis algoritmas, kuris dažnai pasirodo naujuose tyrimuose. Pagal SVM vektoriai atvaizduoja santykinį duomenų taškų išsidėstymą duomenų rinkinyje, o parama vektoriai nubrėžia ribas tarp skirtingų grupių, požymių ar bruožų.
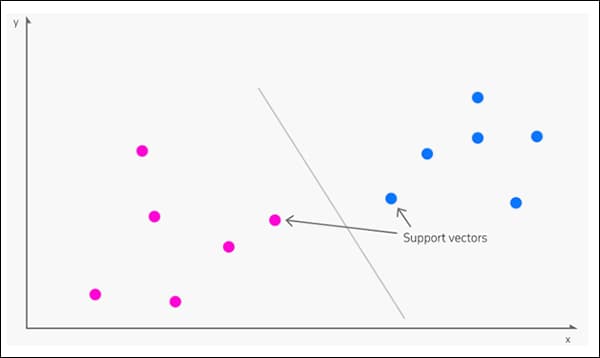
Paramos vektoriai apibrėžia ribas tarp grupių. Šaltinis: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Išvestinė riba vadinama a hiperplokštuma.
Esant žemam funkcijų lygiui, SVM yra dvimatis (vaizdas aukščiau), bet ten, kur yra didesnis atpažįstamas grupių ar tipų skaičius, jis tampa trimatis.

Dėl gilesnio taškų ir grupių masyvo reikalingas trimatis SVM. Šaltinis: https://cml.rhul.ac.uk/svm.html
Populiarus naudojimas
Kadangi vektorinių mašinų palaikymas gali veiksmingai ir agnostiškai apdoroti įvairių rūšių didelio masto duomenis, jie plačiai paplitę įvairiuose mašininio mokymosi sektoriuose, įskaitant gilus klastotės aptikimas, vaizdo klasifikacija, neapykantos kalbos klasifikacija, DNR analizė ir gyventojų struktūros prognozė, tarp daugelio kitų.
4: K-Means Clustering
Klasterizavimas apskritai yra neprižiūrimas mokymasis metodas, kuriuo siekiama suskirstyti duomenų taškus į kategorijas tankio įvertinimas, sukuriant tiriamų duomenų pasiskirstymo žemėlapį.

K-Means sujungia dieviškus segmentus, grupes ir bendruomenes į duomenis. Šaltinis: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
„K“ reiškia grupavimą tapo populiariausiu šio metodo įgyvendinimu, suskirstant duomenų taškus į išskirtines „K grupes“, kurios gali nurodyti demografinius sektorius, internetines bendruomenes ar bet kokią kitą galimą slaptą agregaciją, laukiančią, kol bus aptikta neapdorotuose statistiniuose duomenyse.

Klasteriai susidaro atliekant K-Means analizę. Šaltinis: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Pati K vertė yra lemiamas veiksnys, lemiantis proceso naudingumą ir nustatant optimalią klasterio vertę. Iš pradžių atsitiktinai priskiriama K reikšmė, o jos savybės ir vektoriaus charakteristikos palyginamos su kaimynais. Tie kaimynai, kurie labiausiai primena duomenų tašką su atsitiktinai priskirta reikšme, priskiriami jo klasteriui pakartotinai, kol duomenys pateikia visas grupes, kurias leidžia procesas.
Klaidos kvadrato grafikas arba skirtingų grupių verčių „kaina“ parodys an alkūnės taškas dėl duomenų:

„Alkūnės taškas“ klasterinėje diagramoje. Šaltinis: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Alkūnės taškas savo koncepcija yra panašus į tai, kad duomenų rinkinio treniruotės pabaigoje nuostoliai išlyginami iki mažėjančios grąžos. Tai rodo tašką, kai nebebus akivaizdžių grupių skirtumų, nurodant momentą, kai reikia pereiti prie tolesnių duomenų perdavimo etapų arba pranešti apie išvadas.
Populiarus naudojimas
Dėl akivaizdžių priežasčių „K-Means Clustering“ yra pagrindinė klientų analizės technologija, nes ji siūlo aiškią ir paaiškinamą metodiką dideliems komercinių įrašų kiekiams paversti demografinėmis įžvalgomis ir potencialiais klientais.
Be šios programos, K-Means Clustering taip pat naudojamas nuošliaužos prognozė, medicininio vaizdo segmentavimas, vaizdo sintezė su GAN, dokumentų klasifikacijair miesto planavimas, be daugelio kitų galimų ir faktinių naudojimo būdų.
5: Atsitiktinis miškas
Atsitiktinis miškas yra ansamblinis mokymasis metodas, kuris apskaičiuoja rezultatą iš masyvo sprendimų medžiai sudaryti bendrą rezultato prognozę.

Šaltinis: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Jei jį tyrinėjote net tiek mažai, kiek žiūrėjote Atgal į ateitį trilogijoje, patį sprendimų medį gana lengva konceptualizuoti: prieš jus yra daugybė kelių, ir kiekvienas kelias išsišakoja į naują rezultatą, kuris savo ruožtu apima tolesnius galimus kelius.
In stiprinimas, galite pasitraukti iš kelio ir vėl pradėti nuo ankstesnės pozicijos, o sprendimų medžiai įsipareigoja savo kelionėms.
Taigi Random Forest algoritmas iš esmės yra lažybų už sprendimus. Algoritmas vadinamas „atsitiktiniu“, nes jis sukuria ad hoc atrankos ir stebėjimai, siekiant suprasti mediana sprendimų medžio masyvo rezultatų suma.
Atsižvelgdama į daugybę veiksnių, atsitiktinio miško metodą gali būti sunkiau konvertuoti į reikšmingus grafikus nei sprendimų medį, tačiau jis greičiausiai bus žymiai produktyvesnis.
Sprendimų medžiai per daug derinami, kai gauti rezultatai yra konkretūs ir nėra tikėtina, kad jie bus apibendrinti. „Random Forest“ savavališkas duomenų taškų parinkimas kovoja su šia tendencija, gręždamasis į reikšmingas ir naudingas reprezentatyvias duomenų tendencijas.

Sprendimų medžio regresija. Šaltinis: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populiarus naudojimas
Kaip ir daugelis šiame sąraše pateiktų algoritmų, „Random Forest“ paprastai veikia kaip „ankstyvas“ duomenų rūšiuotojas ir filtras, todėl nuosekliai naudojamas naujuose moksliniuose darbuose. Kai kurie atsitiktinio miško naudojimo pavyzdžiai apima Magnetinio rezonanso vaizdo sintezė, Bitcoin kainos prognozavimas, surašymo segmentavimas, teksto klasifikacija ir kredito kortelės sukčiavimo aptikimas.
Kadangi Random Forest yra žemo lygio algoritmas mašininio mokymosi architektūrose, jis taip pat gali prisidėti prie kitų žemo lygio metodų, taip pat vizualizacijos algoritmų, įskaitant Indukcinis klasterizavimas, Funkcijų transformacijos, tekstinių dokumentų klasifikacija naudojant negausias funkcijasir rodomi vamzdynai.
6: Naivus Bayesas
Kartu su tankio įvertinimu (žr 4, aukščiau), a naivus Bayesas klasifikatorius yra galingas, bet gana lengvas algoritmas, galintis įvertinti tikimybes pagal apskaičiuotas duomenų savybes.

Funkcijų santykiai naiviame Bayes klasifikatoriuje. Šaltinis: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Sąvoka „naivus“ reiškia prielaidą Bayeso teorema kad funkcijos yra nesusijusios, žinomos kaip sąlyginė nepriklausomybė. Jei laikysitės šio požiūrio, vaikščiojimo ir kalbėjimo kaip antis neužtenka, kad įsitikintumėte, jog turime reikalą su antimi, ir per anksti nepriimama jokių „akivaizdžių“ prielaidų.
Toks akademinio ir tiriamojo griežtumo lygis būtų perteklinis, kai pasiekiamas „sveikas protas“, tačiau tai yra vertingas standartas sprendžiant daugybę neaiškumų ir galimai nesusijusių koreliacijų, kurios gali egzistuoti mašininio mokymosi duomenų rinkinyje.
Originaliame Bajeso tinkle funkcijoms taikomos balų skaičiavimo funkcijos, įskaitant minimalų aprašo ilgį ir Bajeso įvarčiai, kuris gali nustatyti duomenų apribojimus, atsižvelgiant į apskaičiuotus ryšius tarp duomenų taškų ir kryptį, kuria šie ryšiai vyksta.
Naivus Bayes klasifikatorius, atvirkščiai, veikia darydamas prielaidą, kad tam tikro objekto ypatybės yra nepriklausomos, o vėliau naudodamas Bayes teoremą tam tikro objekto tikimybei apskaičiuoti, remiantis jo savybėmis.
Populiarus naudojimas
Naive Bayes filtrai yra gerai atstovaujami ligos prognozavimas ir dokumentų skirstymas į kategorijas, šlamšto filtravimas, sentimentų klasifikacija, rekomendacinės sistemosir sukčiavimo aptikimas, be kitų programų.
7: K – artimiausi kaimynai (KNN)
Pirmą kartą pasiūlė JAV oro pajėgų aviacijos medicinos mokykla į 1951, ir turi prisitaikyti prie naujausios XX amžiaus vidurio kompiuterinės įrangos, K-Artimiausi kaimynai (KNN) yra liesas algoritmas, kuris vis dar yra ryškus akademiniuose straipsniuose ir privataus sektoriaus mašininio mokymosi tyrimų iniciatyvose.
KNN buvo vadinamas „tingiu besimokančiuoju“, nes jis išsamiai nuskaito duomenų rinkinį, kad įvertintų ryšius tarp duomenų taškų, o ne reikalautų visaverčio mašininio mokymosi modelio.

KNN grupė. Šaltinis: https://scikit-learn.org/stable/modules/neighbors.html
Nors KNN yra architektūriškai plonas, jo sisteminis požiūris kelia didelį poreikį skaitymo / rašymo operacijoms, o jo naudojimas labai dideliuose duomenų rinkiniuose gali būti problemiškas be papildomų technologijų, tokių kaip pagrindinių komponentų analizė (PCA), galinti pakeisti sudėtingus ir didelės apimties duomenų rinkinius. į reprezentacinės grupės kad KNN gali įveikti mažiau pastangų.
A Neseniai atliktas tyrimas įvertino daugelio algoritmų, kurių užduotis buvo numatyti, ar darbuotojas paliks įmonę, efektyvumą ir ekonomiškumą, nustatęs, kad septynmetis KNN tikslumu ir prognozuojamu efektyvumu išliko pranašesnis už modernesnius varžovus.
Populiarus naudojimas
Nepaisant populiaraus koncepcijos ir vykdymo paprastumo, KNN nėra įstrigęs šeštajame dešimtmetyje – jis buvo pritaikytas labiau į DNN orientuotą požiūrį Pensilvanijos valstijos universiteto 2018 m. pasiūlyme ir išlieka pagrindiniu ankstyvosios stadijos procesu (arba analitinės analizės įrankiu po apdorojimo) daugelyje kur kas sudėtingesnių mašininio mokymosi sistemų.
Įvairiose konfigūracijose KNN buvo naudojamas arba skirtas internetinis parašo patikrinimas, vaizdo klasifikacija, teksto gavyba, pasėlių prognozavimasir veido atpažinimo, be kitų programų ir įtraukimų.

KNN pagrįsta veido atpažinimo sistema mokymuose. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markovo sprendimų procesas (MDP)
Matematinė sistema, kurią pristatė amerikiečių matematikas Richardas Bellmanas į 1957, Markovo sprendimų procesas (MDP) yra vienas iš pagrindinių blokų stiprinimas architektūros. Pats konceptualus algoritmas buvo pritaikytas daugeliui kitų algoritmų ir dažnai kartojamas dabartiniuose AI/ML tyrimuose.
MDP tyrinėja duomenų aplinką, naudodamas jos dabartinės būsenos įvertinimą (ty „kur jis yra duomenyse“), kad nuspręstų, kurį duomenų mazgą tirti toliau.

Šaltinis: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Pagrindiniame Markovo sprendimų procese pirmenybė bus teikiama trumpalaikiam pranašumui, o ne labiau pageidaujamiems ilgalaikiams tikslams. Dėl šios priežasties jis paprastai įtraukiamas į išsamesnę mokymosi stiprinimo politikos architektūros kontekstą ir dažnai priklauso nuo ribojančių veiksnių, pvz. diskontuotas atlygisir kitus modifikuojančius aplinkos kintamuosius, kurie neleis jam skubėti siekti tiesioginio tikslo neatsižvelgiant į platesnį pageidaujamą rezultatą.
Populiarus naudojimas
MDP žemo lygio koncepcija plačiai paplitusi tiek atliekant tyrimus, tiek aktyviai diegiant mašininį mokymąsi. Jis buvo pasiūlytas IoT saugumo gynybos sistemos, žuvies rinkimasir rinkos prognozavimas.
Be jo akivaizdus pritaikymas šachmatai ir kiti griežtai nuoseklūs žaidimai, MDP taip pat yra natūralus varžovas procedūrinis robotikos sistemų mokymas, kaip matome toliau pateiktame vaizdo įraše.

9: termino dažnis – atvirkštinis dokumento dažnis
Termino dažnis (TF) padalija žodžių skaičių dokumente iš bendro žodžių skaičiaus tame dokumente. Taigi žodis užplombuoti pasirodžiusi vieną kartą tūkstančio žodžių straipsnyje, terminų dažnis yra 0.001. Savaime TF iš esmės nenaudingas kaip termino svarbos indikatorius, nes beprasmiai straipsniai (pvz. a, ir, Asir it) vyrauja.
Kad gautų prasmingą termino reikšmę, atvirkštinis dokumentų dažnis (IDF) apskaičiuoja žodžio TF keliuose duomenų rinkinio dokumentuose, priskirdamas žemą įvertinimą labai aukštam dažniui. stabdymo žodžiai, pavyzdžiui, straipsniai. Gauti ypatybių vektoriai normalizuojami į visas vertes, kiekvienam žodžiui priskiriant atitinkamą svorį.

TF-IDF įvertina terminų svarbą pagal dažnumą daugelyje dokumentų, o retesnis atvejis yra reikšmingumo rodiklis. Šaltinis: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Nors šis metodas neleidžia semantiškai svarbiems žodžiams prarasti kaip pašaliniai, dažnio svorio apvertimas automatiškai nereiškia, kad žemo dažnio terminas yra ne išskirtinis, nes kai kurie dalykai yra reti ir bevertis. Todėl žemo dažnio terminas turės įrodyti savo vertę platesniame architektūriniame kontekste, įtraukiant jį (net ir retai vienam dokumentui) daugelyje duomenų rinkinio dokumentų.
Nepaisant to amžiusTF-IDF yra galingas ir populiarus pradinio filtravimo būdas natūralios kalbos apdorojimo sistemose.
Populiarus naudojimas
Kadangi TF-IDF per pastaruosius dvidešimt metų bent dalį vaidino kuriant okultinį Google PageRank algoritmą, jis tapo labai plačiai priimtas kaip manipuliacinė SEO taktika, nepaisant Johno Muellerio 2019 m išsižadėjimas apie jo svarbą paieškos rezultatams.
Dėl PageRank paslapties nėra aiškių įrodymų, kad TF-IDF yra ne šiuo metu efektyvi taktika kilti Google reitinguose. Padegamoji diskusija IT specialistų pastaruoju metu rodo populiarų supratimą, teisingą ar ne, kad piktnaudžiavimas terminu vis tiek gali pagerinti SEO paskirties vietą (nors ir kaltinimai piktnaudžiavimu monopolija ir per didelė reklama sulieja šios teorijos ribas).
10: Stochastinis gradiento nusileidimas
Stochastinis gradiento nusileidimas (SGD) yra vis populiaresnis mašininio mokymosi modelių mokymo optimizavimo metodas.
Pats gradiento nusileidimas yra metodas, leidžiantis optimizuoti ir kiekybiškai įvertinti modelio tobulėjimą treniruočių metu.
Šia prasme „gradientas“ reiškia nuolydį žemyn (o ne spalvomis pagrįstą gradaciją, žr. paveikslėlį žemiau), kur aukščiausias „kalvos“ taškas, esantis kairėje, reiškia mokymo proceso pradžią. Šiame etape modelis dar net vieną kartą nematė visų duomenų ir nepakankamai sužinojo apie ryšius tarp duomenų, kad būtų galima atlikti veiksmingas transformacijas.

Nusileidimas gradientu per „FaceSwap“ treniruotę. Matome, kad antroje pusėje treniruotės kurį laiką sustojo, bet galiausiai atsigavo nuo gradiento link priimtinos konvergencijos.
Žemiausias taškas, esantis dešinėje, reiškia konvergenciją (tašką, kai modelis yra toks pat veiksmingas, koks jis kada nors pasieks pagal taikomus apribojimus ir nustatymus).
Gradientas veikia kaip įrašas ir numatytojas skirtumui tarp klaidų dažnio (kaip tiksliai modelis šiuo metu susiejo duomenų ryšius) ir svorių (nustatymų, turinčių įtakos modelio mokymosi būdui).
Šis pažangos įrašas gali būti naudojamas informuoti a mokymosi tempų grafikas, automatinis procesas, kuris nurodo architektūrai tapti smulkesnė ir tikslesnė, kai ankstyvos neaiškios detalės virsta aiškiais ryšiais ir atvaizdais. Tiesą sakant, gradiento praradimas suteikia tinkamu laiku žemėlapį, kur mokymas turėtų vykti toliau ir kaip jis turėtų vykti.
Stochastic Gradient Descent naujovė yra ta, kad ji atnaujina modelio parametrus kiekviename mokymo pavyzdyje per iteraciją, o tai paprastai pagreitina kelionę į konvergenciją. Dėl pastaraisiais metais atsiradusių hiperskalių duomenų rinkinių SGD pastaruoju metu išpopuliarėjo kaip vienas iš galimų būdų išspręsti kylančias logistikos problemas.
Kita vertus, SGD turi neigiamas pasekmes ypatybių mastelio keitimui ir gali prireikti daugiau iteracijų, kad būtų pasiektas tas pats rezultatas, todėl reikia papildomo planavimo ir papildomų parametrų, palyginti su įprastu gradiento nusileidimu.
Populiarus naudojimas
Dėl savo konfigūravimo ir nepaisant trūkumų, SGD tapo populiariausiu neuroninių tinklų pritaikymo optimizavimo algoritmu. Viena SGD konfigūracijų, kuri tampa dominuojančia naujuose AI/ML tyrimų straipsniuose, yra adaptyvaus momento įvertinimo (ADAM, pristatytas) pasirinkimas. į 2015) optimizatorius.
ADAM dinamiškai pritaiko mokymosi greitį kiekvienam parametrui ("adaptyviojo mokymosi greitis"), taip pat įtraukia ankstesnių atnaujinimų rezultatus į tolesnę konfigūraciją ("momentum"). Be to, jis gali būti sukonfigūruotas naudoti vėlesnes naujoves, pvz Nesterovo impulsas.
Tačiau kai kurie teigia, kad impulso naudojimas taip pat gali pagreitinti ADAM (ir panašius algoritmus) iki a neoptimali išvada. Kaip ir didžioji dalis mašininio mokymosi tyrimų sektoriaus pražūtingo krašto, SGD yra nebaigtas darbas.
Pirmą kartą paskelbta 10 m. vasario 2022 d. Pakeista vasario 10 d. 20.05 EET – formatavimas.















