
Beschte vum
10 Bescht Machine Learning Algorithmen
Och wa mir duerch eng Zäit vun aussergewéinlecher Innovatioun am GPU-beschleunegt Maschinnléiere liewen, hunn déi lescht Fuerschungspabeieren dacks (a prominent) Algorithmen déi Joerzéngte sinn, a bestëmmte Fäll 70 Joer al.
E puer kënne behaapten datt vill vun dësen eelere Methoden an de Camp vun der "statistescher Analyse" falen anstatt Maschinnléieren, a léiwer d'Entstoe vum Secteur eréischt sou wäit wéi 1957 ze datéieren, mat der Erfindung vum Perceptron.
Gitt d'Ausmooss wéi dës eeler Algorithmen ënnerstëtzen a verstoppt sinn an de leschten Trends an Iwwerschrëft-grabbend Entwécklungen am Maschinnléieren, ass et eng contestable Haltung. Also loosst eis e puer vun de "klassesche" Bausteng kucken, déi déi lescht Innovatiounen ënnersträichen, souwéi e puer méi nei Entréen, déi eng fréi Offer fir d'AI Hall of Fame maachen.
1: Transformers
Am Joer 2017 huet Google Fuerschung eng Fuerschungszesummenaarbecht gefouert, déi an der Kulminatioun vum Pabeier Opmierksamkeet ass alles wat Dir braucht. D'Aarbecht huet eng nei Architektur skizzéiert déi gefördert huet Opmierksamkeet Mechanismen Vun 'Piping' an Encoder / Decoder a widderhuelend Netzwierkmodeller bis zu enger zentraler Transformatiounstechnologie an hirem eegene Recht.
D'Approche gouf dubbed Verännerung, an ass zënter enger revolutionärer Methodik an der Natural Language Processing (NLP) ginn, déi, ënner villen anere Beispiller, den autoregressive Sproochmodell an AI Poster-Child GPT-3.
![]()
Transformers elegant geléist de Problem vun Sequenztransduktioun, och 'Transformatioun' genannt, déi mat der Veraarbechtung vun Inputsequenzen an Ausgangssequenzen beschäftegt ass. En Transformator kritt a verwaltet och Daten op eng kontinuéierlech Manéier, anstatt a sequentielle Chargen, wat eng 'Persistenz vun der Erënnerung' erlaabt, déi d'RNN Architekturen net entwéckelt sinn fir ze kréien. Fir eng méi detailléiert Iwwersiicht iwwer Transformatoren, kuckt op eise Referenzartikel.
Am Géigesaz zu de Recurrent Neural Networks (RNNs) déi ugefaang hunn d'ML Fuerschung an der CUDA Ära ze dominéieren, Transformer Architektur kéint och einfach sinn paralleliséiert, de Wee opzemaachen fir produktiv e vill méi grousse Corpus vun Donnéeën ze adresséieren wéi RNNs.
Populär Benotzung
Transformers hunn déi ëffentlech Fantasi am Joer 2020 gefaangen mat der Verëffentlechung vum OpenAI's GPT-3, deen mat engem deemolegen Rekord gebrach huet 175 Milliarden Parameteren. Dës anscheinend iwwerraschend Erreeche gouf schlussendlech duerch spéider Projeten iwwerschësseg, sou wéi den 2021 Fräisetzung vum Microsoft Megatron-Turing NLG 530B, deen (wéi den Numm et scho seet) iwwer 530 Milliarde Parameteren huet.

Eng Timeline vun Hyperscale Transformer NLP Projeten. Source: Microsoft
Transformatorarchitektur ass och vun NLP op Computervisioun iwwergaang, a Kraaft a nei Generatioun vu Bildsynthese Kaderen wéi OpenAI's KLIP an SLAB, déi Text> Image Domain Mapping benotze fir onkomplett Biller ze kompletéieren an nei Biller aus trainéierten Domainen ze synthetiséieren, ënner enger wuessender Zuel vu verbonnen Uwendungen.

DALL-E Versich engem deelweis Bild vun engem Bust vun Platon komplett. Source: https://openai.com/blog/dall-e/
2: Generative Adversarial Networks (GANs)
Och wann Transformatoren aussergewéinlech Medienofdeckung gewonnen hunn duerch d'Verëffentlechung an d'Adoptioun vum GPT-3, den Generative Géigner Netzwierk (GAN) ass eng erkennbar Mark a sech selwer ginn, a kann schlussendlech matmaachen Deepfake als Verb.
Éischt proposéiert zu 2014 a haaptsächlech fir Bildsynthese benotzt, e Generative Adversarial Network Architektur besteet aus engem Generator an engem Diskriminator. De Generator zyklen duerch Dausende vu Biller an engem Datesaz, probéiert iterativ se ze rekonstruéieren. Fir all Versuch klasséiert den Diskriminator d'Aarbecht vum Generator, a schéckt den Generator zréck fir besser ze maachen, awer ouni Abléck an de Wee wéi déi viregt Rekonstruktioun falsch ass.

Quell: https://developers.google.com/machine-learning/gan/gan_structure
Dëst forcéiert den Generator eng Villfalt vun Avenuen ze entdecken, anstatt déi potenziell blann Gassen ze verfollegen, déi entstoen hätt wann den Diskriminator et gesot hätt, wou et falsch geet (kuckt #8 hei ënnen). No der Zäit wou d'Formatioun eriwwer ass, huet de Generator eng detailléiert an ëmfaassend Kaart vu Bezéiungen tëscht Punkten an der Datesaz.

Aus dem Pabeier GAN Gläichgewiicht verbesseren andeems d'Ratial Sensibiliséierung erhéicht gëtt: e Roman Kader Zyklen duerch déi heiansdo mysteriéis latente Raum vun engem GAN, déi reaktiounsfäeger Instrumentalitéit fir eng Bild Synthes Architektur. Source: https://genforce.github.io/eqgan/
Analogie ass dëst den Ënnerscheed tëscht engem eenzegen Humdrum Pendel an Mëtt London ze léieren, oder ustrengend ze kréien D'Wëssen.
D'Resultat ass eng héich-Niveau Sammlung vun Fonctiounen am latente Raum vun der trainéiert Modell. De semantesche Indikator fir eng Feature op héijen Niveau kéint 'Persoun' sinn, wärend en Ofstamung duerch Spezifizitéit am Zesummenhang mat der Feature kann aner geléiert Charakteristiken opdecken, sou wéi 'männlech' a 'weiblech'. Op méi nidderegen Niveauen kënnen d'Ënnerfeatures opbriechen op, 'blond', 'Caucasian', et al.
Entanglement ass en Notabele Problem am latente Raum vu GANs an Encoder / Decoder Kaderen: ass de Laachen op engem GAN-generéierte weibleche Gesiicht eng verwéckelt Feature vun hirer 'Identitéit' am latente Raum, oder ass et eng parallel Branche?

GAN-generéiert Gesiichter vun dëser Persoun existéieren net. Quell: https://this-person-does-not-exist.com/en
Déi lescht puer Joer hunn eng wuessend Unzuel vun neie Fuerschungsinitiativen an dësem Respekt bruecht, vläicht de Wee fir Feature-Niveau, Photoshop-Stil Redaktioun fir de latente Raum vun engem GAN, awer am Moment sinn vill Transformatiounen effektiv ' alles oder näischt' Packagen. Notamment, dem NVIDIA seng EditGAN Verëffentlechung vum spéiden 2021 erreecht eng héije Niveau vun Interpretabilitéit am latente Raum andeems se semantesch Segmentatiounsmasken benotzt.
Populär Benotzung
Nieft hirer (tatsächlech zimlech limitéiert) Bedeelegung u populäre Deepfake Videoen, hunn d'Bild / Video-centric GANs an de leschte véier Joer verbreet, d'Fuerscher an de Public begeeschtert. Mat dem schwindelegen Taux an der Frequenz vun neie Verëffentlechungen ze halen ass eng Erausfuerderung, obwuel de GitHub Repository Fantastesch GAN Uwendungen zielt eng ëmfaassend Lëscht ze bidden.
Generativ Adversarial Netzwierker kënnen an der Theorie Features aus all gutt-cadréiert Domain ofleeden, dorënner Text.
3: SVM
Entstanen zu 1963, Ënnerstëtzung Vector Machine (SVM) ass e Käralgorithmus deen dacks an nei Fuerschung optrieden. Ënner SVM kartéieren Vecteure déi relativ Dispositioun vun Datenpunkten an engem Dataset, wärend Ënnerstëtzung Vektoren delineéieren d'Grenzen tëscht verschiddene Gruppen, Features oder Charakteren.
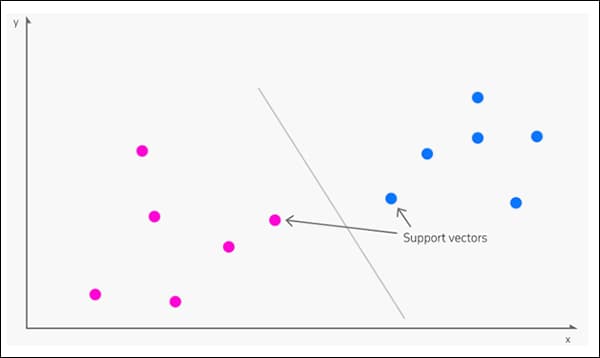
Ënnerstëtzungsvektoren definéieren d'Grenze tëscht Gruppen. Quell: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Déi ofgeleet Grenz gëtt a genannt hyperplane.
Op niddereg Feature Niveauen ass de SVM zweedimensional (Bild uewen), awer wou et eng méi héich unerkannt Zuel vu Gruppen oder Typen gëtt, gëtt et dreidimensional ass.

Eng méi déif Gamme vu Punkten a Gruppen erfuerdert en dreidimensionalen SVM. Source: https://cml.rhul.ac.uk/svm.html
Populär Benotzung
Zënter Ënnerstëtzung Vector Machines kënnen effektiv an agnostesch héichdimensional Daten vu villen Aarte adresséieren, erschéngen se wäit iwwer eng Vielfalt vu Maschinnléiere Secteuren, inklusiv Deepfake Detektioun, Bild Klassifikatioun, Haass Ried Klassifikatioun, DNA Analyse an Bevëlkerungsstruktur Prognose, ënner villen aneren.
4: K-Mëtt Clustering
Clustering am Allgemengen ass eng net iwwerwaacht Léieren Approche déi versicht daten Punkten duerch ze kategoriséieren Dicht Schätzung, eng Kaart vun der Verdeelung vun den studéierten Donnéeën erstellen.

K-Bedeit clustering göttlech Segmenter, Gruppen a Communautéiten an Daten. Quell: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Mëtt Clustering ass déi populärste Ëmsetzung vun dëser Approche ginn, Schäferdaten Punkten an ënnerscheedleche 'K Groups', déi demographesch Secteuren, Online Gemeinschaften oder all aner méiglech geheim Aggregatioun kënne weisen, déi waarden op entdecken a rau statisteschen Donnéeën.

Cluster bilden an der K-Means Analyse. Quell: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
De K-Wäert selwer ass den determinante Faktor an der Utilitéit vum Prozess, a fir en optimale Wäert fir e Stärekoup opzebauen. Am Ufank gëtt de K Wäert zoufälleg zougewisen, a seng Fonctiounen a Vecteure Charakteristiken am Verglach zu sengen Noperen. Déi Noperen, déi am meeschte gläichen den Datepunkt mam zoufälleg zougewisenen Wäert, ginn iterativ u säi Cluster zougewisen, bis d'Donnéeën all d'Gruppéierungen erginn hunn, déi de Prozess erlaabt.
De Komplott fir de Quadratfehler, oder 'Käschte' vun ënnerschiddleche Wäerter tëscht de Cluster wäerten en Ielebou Punkt fir Daten:

Den 'Illbogenpunkt' an engem Cluster Grafik. Source: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Den Ieleboupunkt ass am Konzept ähnlech wéi de Wee wéi de Verloscht ofplatt op d'Verréngerung vun der Rendement um Enn vun enger Trainingssitzung fir en Dataset. Et stellt de Punkt duer, op deem keng weider Ënnerscheeder tëscht Gruppen offensichtlech ginn, wat de Moment uginn fir op déi spéider Phasen an der Datepipeline weiderzekommen, oder soss Erkenntnisser ze berichten.
Populär Benotzung
K-Means Clustering, aus offensichtleche Grënn, ass eng primär Technologie an der Clientsanalyse, well et eng kloer an erklärbar Methodik bitt fir grouss Quantitéite vu kommerziellen Opzeechnungen an demographesch Abléck an 'Leads' ze iwwersetzen.
Ausserhalb vun dëser Applikatioun ass K-Means Clustering och agestallt fir Äerdrutsch Prognose, medezinesch Bild Segmentatioun, Bildsynthese mat GANs, Dokument Klassifikatioun, an Stadsplanung, ënner villen anere potenziellen an aktuellen Gebrauch.
5: Zoufall Bësch
Zoufälleg Bësch ass eng Ensemble Léieren Method, déi d'Resultat aus enger Rei vu Moyenne moosst Entscheedung Beem eng allgemeng Prognose fir d'Resultat opzebauen.

Quell: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Wann Dir et och esou wéineg recherchéiert wéi de kucken Back to the Future Trilogie, en Decisiounsbam selwer ass zimlech einfach ze Konzeptualiséieren: eng Rei vu Weeër leien virun Iech, an all Wee branchéiert sech op en neit Resultat, deen dann och weider méiglech Weeër enthält.
In Verstäerkung ze léieren, Dir kënnt vun engem Wee zréckzéien an erëm vun enger fréierer Haltung ufänken, wärend Entscheedungsbeem sech fir hir Reesen engagéieren.
Also de Random Forest Algorithmus ass wesentlech verbreet Wetten fir Entscheedungen. Den Algorithmus gëtt 'zoufälleg' genannt well et mécht ad hoc Selektiounen an Observatioune fir ze verstoen de Median Zomm vun de Resultater vun der Decisioun Bam Array.
Well et eng Villfalt vu Faktoren berücksichtegt, kann eng Random Forest Approche méi schwéier sinn a sënnvoll Grafike ëmzewandelen wéi en Entscheedungsbam, awer ass wahrscheinlech notamment méi produktiv.
Decisioun Beem ënnerleien zu overfitting, wou d'Resultater kritt sinn daten spezifesch an net wahrscheinlech ze generaliséieren. Random Forest arbiträr Auswiel vun Daten Punkten bekämpft dëser Tendenz, Bueraarbechten duerch ze sënnvoll an nëtzlech representativ Trends an der Donnéeën.

Decisioun Bam Réckgang. Source: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populär Benotzung
Wéi mat ville vun den Algorithmen an dëser Lëscht funktionnéiert Random Forest typesch als 'fréi' Sorter a Filter vun Daten, an als solch konsequent an nei Fuerschungspabeieren op. E puer Beispiller vu Random Forest Notzung enthalen Magnéitesch Resonanz Bild Synthese, Prognosen fir Bitcoin, Vollekszielung Segmentatioun, Text Klassifikatioun an Kreditkaart Bedruch Detektioun.
Zënter Random Forest e Low-Level Algorithmus a Maschinnléierarchitekturen ass, kann et och zur Leeschtung vun anere Low-Level Methoden bäidroen, souwéi Visualiséierungsalgorithmen, inklusiv Induktiv Clustering, Fonktioun Transformatiounen, Klassifikatioun vun Textdokumenter benotzt spatzen Fonctiounen, an weist Pipelines.
6: Naiv Bayes
Gekoppelt mat Dichtschätzung (kuckt 4, uewen), a naiv Bayes Klassifizéierer ass e mächtegen awer relativ liichte Algorithmus kapabel Wahrscheinlechkeeten ze schätzen baséiert op de berechent Feature vun Daten.

Feature Bezéiungen an engem naiven Bayes Klassifizéierer. Quell: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
De Begrëff "naiv" bezitt sech op d'Annahme an Bayes' Theorem datt d'Features net verbonne sinn, bekannt als bedingt Onofhängegkeet. Wann Dir dëse Standpunkt adoptéiert, geet et net duer ze goen a wéi eng Int ze schwätzen, fir festzestellen, datt mir mat enger Int ze dinn hunn, a keng "evident" Viraussetzunge ginn ze fréi ugeholl.
Dësen Niveau vun der akademescher an investigativer Rigoritéit wier iwwerkillt wou 'gesonde Verstand' verfügbar ass, awer ass e wäertvolle Standard wann Dir déi vill Ambiguititéiten a potenziell onrelatéierte Korrelatiounen duerchkreest, déi an engem Maschinnléier-Dataset existéieren.
An engem original Bayesian Reseau, Fonctiounen ënnerleien Punktzuel Funktiounen, dorënner minimal Beschreiwung Längt an Bayesian Score, déi Restriktiounen op d'Daten opzeleeën wat d'geschätzte Verbindungen tëscht den Datepunkte fonnt hunn an d'Richtung an där dës Verbindunge fléissen.
En naiven Bayes Klassifizéierer, am Géigendeel, funktionnéiert andeems se ugeholl datt d'Features vun engem bestëmmten Objet onofhängeg sinn, duerno benotzt de Bayes'Theorem fir d'Wahrscheinlechkeet vun engem bestëmmten Objet ze berechnen, baséiert op seng Features.
Populär Benotzung
Naiv Bayes Filtere si gutt vertrueden Krankheet Prévisioun an Dokument Kategoriséierung, Spamfilter, Gefill Klassifikatioun, recommandéiert Systemer, an Bedruch Detectioun, ënner anerem Uwendungen.
7: K- Nearest Neighbors (KNN)
Éischt proposéiert vun der US Air Force School of Aviation Medicine zu 1951, a musse sech un de modernste vun der Mëtt vum 20. K-Noosten Noperen (KNN) ass e schlanke Algorithmus deen nach ëmmer prominent iwwer akademesch Pabeieren a private Secteur Maschinnléiere Fuerschungsinitiativen huet.
KNN gouf "de faulen Léierner" genannt, well et ustrengend en Dataset scannt fir d'Relatiounen tëscht Datenpunkten ze evaluéieren, anstatt d'Ausbildung vun engem vollwäertege Maschinnléiermodell ze erfuerderen.

Eng KNN Gruppéierung. Quell: https://scikit-learn.org/stable/modules/neighbors.html
Och wann KNN architektonesch schlank ass, stellt seng systematesch Approche eng bemierkenswäert Nofro un Lies-/Schreifoperatioune, a seng Notzung a ganz groussen Datesätz kann problematesch sinn ouni Zousaztechnologien wéi Principal Component Analysis (PCA), déi komplex an héich Volumen Datesätz transforméiere kënnen. an representativ Gruppéierungen datt de KNN mat manner Effort ka verwandelen.
A rezent Etude evaluéiert d'Effizienz an d'Wirtschaft vun enger Zuel vun Algorithmen, déi d'Aufgab hunn virauszesoen, ob en Employé eng Firma wäert verloossen, a feststellen datt de septuagenarian KNN méi modern Konkurrenten iwwer d'Genauegkeet an d'predictive Effizienz bleift.
Populär Benotzung
Fir all seng populär Einfachheet vu Konzept an Ausféierung ass de KNN net an den 1950er festgehalen - et ass adaptéiert an eng méi DNN-konzentréiert Approche an engem 2018 Propositioun vun Pennsylvania State University, a bleift en zentrale fréi-Etapp Prozess (oder Post-Veraarbechtung analytesch Outil) a ville wäit méi komplex Maschinn Léieren Kaderen.
A verschiddene Konfiguratiounen gouf KNN benotzt oder fir Online Ënnerschrëft Verifizéierung, Bild Klassifikatioun, Text Minière, Ernteprevisioun, an Gesiicht Unerkennung, Nieft aner Uwendungen an Inkorporatiounen.

E KNN-baséiert Gesiichtserkennungssystem am Training. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markov Entscheedungsprozess (MDP)
E mathematesche Kader agefouert vum amerikanesche Mathematiker Richard Bellman zu 1957, De Markov Decision Process (MDP) ass ee vun de meescht Basisblocken vun Verstäerkung ze léieren Architekturen. E konzeptuellen Algorithmus a sech selwer, et gouf an eng grouss Zuel vun aneren Algorithmen ugepasst, a widderhëlt dacks an der aktueller Ernte vun der AI / ML Fuerschung.
MDP exploréiert en Datenëmfeld andeems se seng Evaluatioun vu sengem aktuellen Zoustand benotzt (dh 'wou' et an den Donnéeën ass) fir ze entscheeden wéi en Node vun den Daten als nächst ze entdecken.

Source: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
E Basis Markov Entscheedungsprozess prioritär kuerzfristeg Virdeel iwwer méi wënschenswäert laangfristeg Ziler. Aus dësem Grond ass et normalerweis an de Kontext vun enger méi ëmfaassender Politikarchitektur am Verstäerkungsléieren agebaut, an ass dacks ënnerleien vu limitéierende Faktoren wéi z. discounted Belounung, an aner verännerend Ëmweltvariablen, déi verhënneren datt et op en direkten Zil rennt ouni de méi breet gewënschte Resultat ze berücksichtegen.
Populär Benotzung
Dem MDP säi Low-Level Konzept ass verbreet a béid Fuerschung an aktiv Deployment vu Maschinnléieren. Et ass proposéiert fir IoT Sécherheet Verteidegung Systemer, Fësch Recolte, an Maart Prognosen.
Nieft sengem offensichtlech Applikatioun zu Schach an aner strikt sequentiell Spiller, MDP ass och en natierleche Kandidat fir de prozedural Ausbildung vu Robotersystemer, wéi mir am Video hei ënnen gesinn.

9: Begrëff Frequenz-Inverse Dokument Frequenz
Begrëff Frequenz (TF) deelt d'Zuel vun de Mol e Wuert an engem Dokument mat der Gesamtzuel vun de Wierder an deem Dokument. Also d'Wuert versigelt eemol an engem dausend-Wuert Artikel erschéngen huet eng Begrëff Frequenz vun 0.001. U sech selwer ass TF gréisstendeels nëtzlos als Indikator vu Begrëff Wichtegkeet, wéinst der Tatsaach datt sënnlos Artikelen (wéi z. a, an, der, an it) dominéieren.
Fir e sënnvolle Wäert fir e Begrëff ze kréien, berechent Inverse Document Frequency (IDF) den TF vun engem Wuert iwwer verschidde Dokumenter an engem Datesaz, zougewisen niddereg Bewäertung op ganz héich Frequenz Stoppwierder, wéi Artikelen. Déi resultéierend Featurevektore ginn op ganz Wäerter normaliséiert, mat all Wuert e passende Gewiicht zougewisen.

TF-IDF weegt d'Relevanz vu Begrëffer op Basis vun der Frequenz iwwer eng Zuel vun Dokumenter, mat méi rarer Optriede en Indikator vu Salience. Quell: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Och wann dës Approche verhënnert datt semantesch wichteg Wierder verluer gi wéi Auslänner, Invertéiere vun der Frequenzgewicht heescht net automatesch datt e Low-Frequenz Begrëff ass net en Outlier, well e puer Saache sinn seelen an wäertlos. Dofir muss e Low-Frequenz Begrëff säi Wäert am méi breeden architektonesche Kontext beweisen andeems se (souguer bei enger niddereger Frequenz pro Dokument) an enger Zuel vun Dokumenter am Datasetze presentéieren.
Trotz senger Alter, TF-IDF ass eng mächteg a populär Method fir initial Filterpassë an Natural Language Processing Kaderen.
Populär Benotzung
Well TF-IDF op d'mannst en Deel an der Entwécklung vum Google säi gréisstendeels okkulte PageRank Algorithmus an de leschten zwanzeg Joer gespillt huet, ass et ginn ganz wäit ugeholl als manipulativ SEO Taktik, trotz dem John Mueller sengem 2019 Oflehnung vu senger Wichtegkeet fir d'Sichresultater.
Wéinst dem Geheimnis ronderëm PageRank gëtt et keng kloer Beweiser datt TF-IDF ass net momentan eng effektiv Taktik fir an de Google Ranking eropzeklammen. Brennend Diskussioun Ënner IT Professionnelen weist viru kuerzem e populär Verständnis un, richteg oder net, datt Begrëffsmëssbrauch nach ëmmer zu enger verbesserter SEO Placement resultéiere kann (obwuel zousätzlech Uklo vu Monopolmëssbrauch an exzessiv Reklammen d'Grenz vun dëser Theorie verschwannen).
10: Stochastic Gradient Ofstamung
Stochastic Gradient Ofstamung (SGD) ass eng ëmmer méi populär Method fir d'Ausbildung vu Maschinnléiermodeller ze optimiséieren.
Gradient Descent selwer ass eng Method fir d'Verbesserung ze optimiséieren an duerno ze quantifizéieren déi e Modell während Training mécht.
An dësem Sënn weist 'gradient' en Hang no ënnen un (anstatt eng Faarf-baséiert Gradatioun, kuckt d'Bild hei ënnen), wou den héchste Punkt vum 'Hiwwel', lénks, den Ufank vum Trainingsprozess duerstellt. Op dëser Etapp huet de Modell nach net d'Gesamtheet vun den Donnéeën och eemol gesinn, an huet net genuch iwwer d'Relatiounen tëscht den Daten geléiert fir effektiv Transformatiounen ze produzéieren.

E Gradient Ofstamung op enger FaceSwap Trainingssitzung. Mir kënne gesinn datt den Training fir eng Zäit an der zweeter Halschent plateau ass, awer schlussendlech de Wee erof an de Gradient op eng akzeptabel Konvergenz erholl huet.
Den ënneschten Punkt, op der rietser Säit, representéiert d'Konvergenz (de Punkt op deem de Modell esou effektiv ass wéi et jeemools ënner de imposéierten Aschränkungen an Astellunge wäert kommen).
De Gradient handelt als Rekord a Prädiktor fir d'Differenz tëscht dem Fehlerquote (wéi präzis de Modell de Moment d'Dateverhältnisser kartéiert huet) an d'Gewichte (d'Astellungen déi d'Aart a Weis beaflossen wéi de Modell léiert).
Dëse Rekord vum Fortschrëtt ka benotzt ginn fir eng z'informéieren Léieren Taux Zäitplang, en automateschen Prozess, deen d'Architektur erzielt fir méi granulär a präzis ze ginn, wéi déi fréi vague Detailer sech a kloer Bezéiungen a Mappings transforméieren. Tatsächlech bitt Gradientverloscht eng just-in-time Kaart vu wou d'Ausbildung nächst soll goen, a wéi et soll weidergoen.
D'Innovatioun vum Stochastic Gradient Descent ass datt et d'Parameteren vum Modell op all Trainingsbeispill pro Iteratioun aktualiséiert, wat allgemeng d'Rees zur Konvergenz beschleunegt. Wéinst dem Advent vun hyperscale Datesätz an de leschte Joeren ass SGD zënter kuerzem an der Popularitéit gewuess als eng méiglech Method fir déi folgend logistesch Themen unzegoen.
Op der anerer Säit huet SGD negativ Implikatioune fir Feature Skaléieren, a kënne méi Iteratiounen erfuerderen fir datselwecht Resultat z'erreechen, déi zousätzlech Planung an zousätzlech Parameteren erfuerderen, am Verglach zum reguläre Gradient Descent.
Populär Benotzung
Wéinst senger Konfiguratioun, an trotz senge Mängel, ass SGD de beléifsten Optimisatiounsalgorithmus ginn fir neural Netzwierker ze passen. Eng Konfiguratioun vu SGD déi dominant gëtt an neien AI / ML Fuerschungspabeieren ass d'Wiel vun der Adaptive Moment Estimation (ADAM, agefouert) zu 2015) Optimizer.
ADAM passt de Léierrate fir all Parameter dynamesch un ('adaptive Léierrate'), sou wéi d'Resultater vu fréiere Updates an déi spéider Konfiguratioun ('Momentum') integréiert. Zousätzlech kann et konfiguréiert ginn fir spéider Innovatiounen ze benotzen, wéi z Nesterov Momentum.
Wéi och ëmmer, e puer behaapten datt d'Benotzung vum Dréimoment och ADAM (an ähnlech Algorithmen) zu engem beschleunegen kann suboptimal Conclusioun. Wéi mat de meeschte bluddege Rand vum Maschinnléierefuerschungssektor, ass SGD eng Aarbecht amgaang.
Éischt publizéiert 10. Februar 2022. Amendéiert 10. Februar 20.05 EET - Formatéierung.















