
AI 101
Wat ass Dimensiounsreduktioun?
Wat ass Dimensiounsreduktioun?
Dimensiounsreduktioun ass e Prozess dee benotzt gëtt fir d'Dimensionalitéit vun engem Dataset ze reduzéieren, vill Features ze huelen an se als manner Features ze representéieren. Zum Beispill, Dimensiounsreduktioun kéint benotzt ginn fir en Dataset vun zwanzeg Features op nëmmen e puer Features ze reduzéieren. Dimensiounsreduktioun gëtt allgemeng benotzt an net iwwerwaacht Léieren Aufgaben fir automatesch Klassen aus ville Funktiounen ze kreéieren. Fir besser ze verstoen firwat a wéi Dimensiounsreduktioun benotzt gëtt, Mir wäerten e Bléck op d'Problemer verbonne mat héich Dimensiounsdaten an de beléifsten Methode vun Dimensioun reduzéieren.
Méi Dimensiounen féiert zu Iwwerfitting
Dimensionalitéit bezitt sech op d'Zuel vun de Featuren / Kolonnen an engem Dataset.
Et gëtt dacks ugeholl datt am Maschinnléiere méi Feature besser sinn, well et e méi genaue Modell erstellt. Wéi och ëmmer, méi Features iwwersetzen net onbedéngt op e bessere Modell.
D'Features vun engem Dataset kënne wäit variéieren a punkto wéi nëtzlech se fir de Modell sinn, mat ville Feature vu wéineg Wichtegkeet. Zousätzlech, wat méi Features d'Dateset enthält, wat méi Proben gebraucht ginn fir sécherzestellen datt déi verschidde Kombinatioune vu Features gutt an den Daten vertruede sinn. Dofir erhéicht d'Zuel vun de Proben am Verhältnis mat der Unzuel vun de Funktiounen. Méi Echantillon a méi Fonctiounen bedeit datt de Modell méi komplex muss sinn, a wéi d'Modeller méi komplex ginn, gi se méi empfindlech op Iwwerfitting. De Modell léiert d'Musteren an den Trainingsdaten ze gutt an et fält net op aus Proufdaten ze generaliséieren.
D'Reduktioun vun der Dimensioun vun engem Dataset huet verschidde Virdeeler. Wéi scho gesot, méi einfach Modeller si manner ufälleg fir ze iwwerpassen, well de Modell manner Viraussetzunge muss maachen iwwer wéi d'Features matenee verbonne sinn. Zousätzlech bedeite manner Dimensiounen datt manner Rechenkraaft erfuerderlech ass fir d'Algorithmen ze trainéieren. Ähnlech ass manner Späicherplatz gebraucht fir eng Dataset déi méi kleng Dimensioun huet. D'Reduktioun vun der Dimensioun vun engem Dataset kann Iech och Algorithmen benotzen déi net gëeegent sinn fir Datesets mat ville Funktiounen.
Gemeinsam Dimensionalitéit Reduktioun Methoden
Dimensiounsreduktioun kann duerch Feature Selektioun oder Feature Engineering sinn. Feature Selektioun ass wou den Ingenieur déi relevantst Feature vum Dataset identifizéiert, wärend Fonktioun Engineering ass de Prozess fir nei Features ze kreéieren andeems Dir aner Features kombinéiert oder transforméiert.
Feature Auswiel an Ingenieur kënnen programmatesch oder manuell gemaach ginn. Wann Dir manuell Auswiel an Ingenieursfeatures wielt, ass d'Visualiséierung vun den Daten fir Korrelatiounen tëscht Featuren a Klassen ze entdecken typesch. Dimensiounsreduktioun op dës Manéier auszeféieren kann zimmlech Zäitintensiv sinn an dofir e puer vun den allgemengste Weeër fir d'Dimensionalitéit ze reduzéieren involvéiert d'Benotzung vun Algorithmen verfügbar a Bibliothéiken wéi Scikit-learn for Python. Dës gemeinsam Dimensiounsreduktiounsalgorithmen enthalen: Haaptkomponentanalyse (PCA), Singular Value Decomposition (SVD), a Linear Diskriminant Analyse (LDA).
D'Algorithmen, déi an der Dimensiounsreduktioun fir net iwwerwaacht Léieraufgaben benotzt ginn, sinn typesch PCA a SVD, während déi, déi fir iwwerwaacht Léierdimensionalitéitsreduktioun geliwwert ginn, typesch LDA a PCA sinn. Am Fall vun iwwerwaachte Léiermodeller ginn déi nei generéiert Feature just an de Maschinnléierklassifizéierer gefüttert. Notéiert datt d'Uwendungen, déi hei beschriwwe sinn, just allgemeng Benotzungsfäll sinn an net déi eenzeg Konditiounen, déi dës Technike kënne benotzt ginn. D'Dimensiounsreduktiounsalgorithmen, déi uewen beschriwwe sinn, sinn einfach statistesch Methoden a si ginn ausserhalb vu Maschinnléieremodeller benotzt.
Haaptkomponent Analyse

Foto: Matrix mat Haaptkomponenten identifizéiert
Haaptkomponentanalyse (PCA) ass eng statistesch Method déi d'Charakteristiken / Features vun engem Dataset analyséiert an d'Features resüméiert déi am meeschte beaflosst sinn. D'Features vun der Dataset ginn zesummen a Representatioune kombinéiert, déi déi meescht vun de Charakteristike vun den Donnéeën erhalen, awer iwwer manner Dimensiounen verdeelt sinn. Dir kënnt un dëst denken als "squishing" d'Donnéeën erof vun enger méi héijer Dimensioun Representatioun op eng mat just e puer Dimensiounen.
Als e Beispill vun enger Situatioun wou PCA kéint nëtzlech sinn, denkt un déi verschidde Weeër wéi ee Wäin beschreiwen kann. Och wann et méiglech ass Wäin ze beschreiwen mat villen héich spezifesche Featuren wéi CO2 Niveauen, Belëftungsniveauen, etc., kënnen esou spezifesch Features relativ nëtzlos sinn wann Dir probéiert eng spezifesch Aart vu Wäin z'identifizéieren. Amplaz wier et méi virsiichteg d'Typ z'identifizéieren baséiert op méi allgemeng Features wéi Geschmaach, Faarf an Alter. PCA ka benotzt ginn fir méi spezifesch Features ze kombinéieren an Features ze kreéieren déi méi allgemeng, nëtzlech a manner wahrscheinlech Iwwerfitting verursaachen.
PCA gëtt duerchgefouert andeems Dir feststellt wéi d'Inputfeatures vun der Moyenne matenee variéieren, a bestëmmt ob Relatiounen tëscht de Funktiounen existéieren. Fir dëst ze maachen, gëtt eng kovariant Matrix erstallt, eng Matrix opzebauen, déi aus de Kovarianzen mat Respekt zu de méigleche Pairen vun den Datasetfeatures besteet. Dëst gëtt benotzt fir Korrelatiounen tëscht de Variabelen ze bestëmmen, mat enger negativer Kovarianz déi eng invers Korrelatioun beweist an eng positiv Korrelatioun déi eng positiv Korrelatioun ugeet.
Déi wichtegst (beaflosst) Komponente vum Dataset ginn erstallt andeems linear Kombinatioune vun den initialen Variablen erstallt ginn, wat mat der Hëllef vu linearen Algebra Konzepter gemaach gëtt, genannt eegenwäerter an eegene Vektoren. D'Kombinatioune ginn erstallt sou datt d'Haaptkomponenten net matenee korreléiert sinn. Déi meescht vun der Informatioun, déi an den initialen Variabelen enthale sinn, ass an déi éischt puer Haaptkomponenten kompriméiert, dat heescht datt nei Features (d'Haaptkomponenten) erstallt goufen, déi d'Informatioun aus dem ursprénglechen Dataset an engem méi klengen Dimensiounsraum enthalen.
Eenzege Wäert Zersetzung
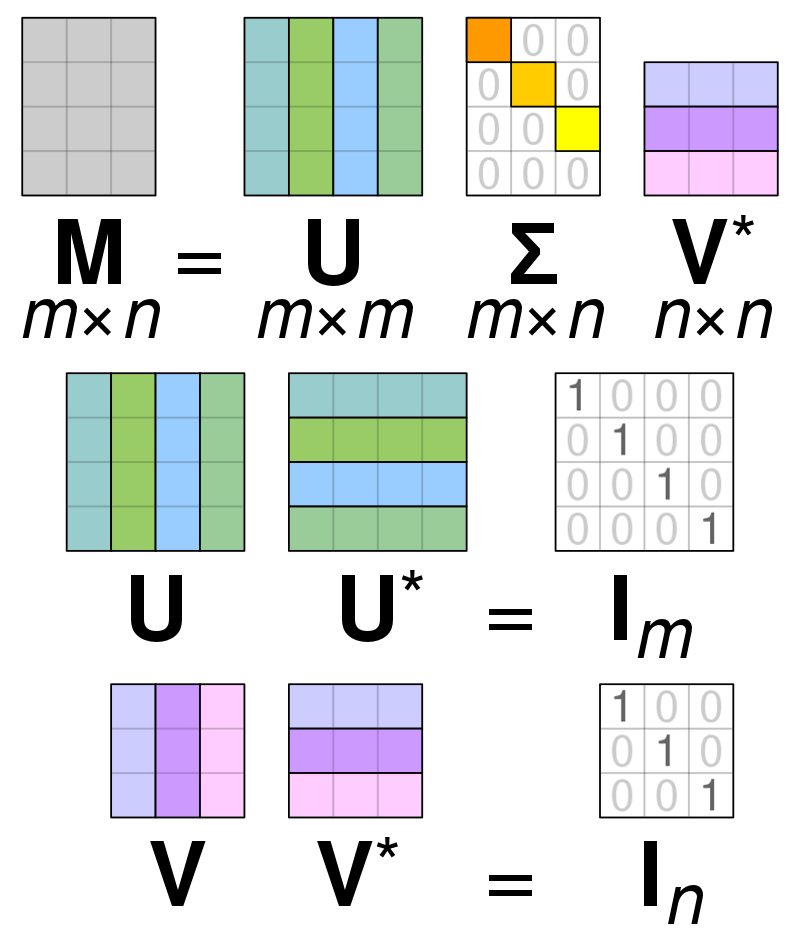
Foto: Vum Cmglee - Eegent Wierk, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Singular Value Decomposition (SVD) is benotzt fir d'Wäerter an enger Matrix ze vereinfachen, reduzéiert d'Matrix op seng Bestanddeeler a mécht d'Berechnunge mat där Matrix méi einfach. SVD ka souwuel fir real-Wäert a komplex Matrixentgas benotzt ginn, awer fir d'Ziler vun dëser Erklärung wäert ënnersichen wéi een eng Matrix vun echte Wäerter ofbaut.
Gitt un datt mir eng Matrix hunn, déi aus Real-Wäertdaten komponéiert ass an eist Zil ass d'Zuel vu Spalten / Features bannent der Matrix ze reduzéieren, ähnlech wéi d'Zil vum PCA. Wéi PCA wäert SVD d'Dimensionalitéit vun der Matrix kompriméieren, wärend sou vill vun der Verännerlechkeet vun der Matrix wéi méiglech behalen. Wa mir op Matrix A operéiere wëllen, kënne mir Matrix A als dräi aner Matrizen representéieren genannt U, D, & V. Matrix A besteet aus den ursprénglechen x * y Elementer, während d'Matrix U aus Elementer X * X (et ass) eng orthogonal Matrix). Matrix V ass eng aner orthogonal Matrix déi y * y Elementer enthält. Matrix D enthält d'Elementer x * y an et ass eng diagonal Matrix.
Fir d'Wäerter vun der Matrix A ze dekomponéieren, musse mir déi ursprénglech Singular Matrixwäerter an d'diagonal Wäerter konvertéieren, déi an enger neier Matrix fonnt goufen. Wann Dir mat orthogonalen Matrizen schafft, änneren hir Eegeschafte net wa se mat aneren Zuelen multiplizéiert ginn. Dofir kënne mir d'Matrix A unschätzen andeems Dir vun dëser Immobilie profitéiert. Wa mir déi orthogonal Matrizen zesumme mat enger Transpose vun der Matrix V multiplizéieren, ass d'Resultat eng gläichwäerteg Matrix zu eiser ursprénglecher A.
Wann d'Matrix a an d'Matrixen U, D a V ofgebaut gëtt, enthalen se d'Donnéeën, déi an der Matrix A fonnt goufen. Wéi och ëmmer, déi lénks Kolonnen vun de Matrixen halen d'Majoritéit vun den Donnéeën. Mir kënne just dës éischt puer Kolonnen huelen an eng Duerstellung vun der Matrix A hunn déi vill manner Dimensiounen huet an déi meescht vun den Donnéeën bannent A.
Linear Diskriminatioun Analyse

Lénks: Matrix virum LDA, Riets: Achs no LDA, elo trennbar
Linear Diskriminatioun Analyse (LDA) ass e Prozess deen Daten aus enger multidimensionaler Grafik hëlt an reprojectéiert et op eng linear Grafik. Dir kënnt dëst virstellen andeems Dir un eng zweedimensional Grafik denkt, gefëllt mat Datepunkte, déi zu zwou verschiddene Klassen gehéieren. Dovun ausgoen, datt d'Punkten ronderëm verspreet sinn, sou datt keng Linn kann gezunn ginn, datt déi zwou verschidde Klassen ordentlech trennen. Fir dës Situatioun ze handhaben, kënnen d'Punkten, déi an der 2D Grafik fonnt ginn, op eng 1D Grafik (eng Linn) reduzéiert ginn. Dës Linn wäert all d'Datepunkte verdeelt hunn an et kann hoffentlech an zwou Sektiounen opgedeelt ginn, déi déi bescht méiglech Trennung vun den Daten duerstellen.
Wann Dir LDA ausféiert, ginn et zwee primär Ziler. Dat éischt Zil ass d'Varianz fir d'Klassen ze minimiséieren, während dat zweet Zil ass d'Distanz tëscht de Mëttelen vun den zwou Klassen ze maximéieren. Dës Ziler ginn erreecht andeems Dir eng nei Achs kreéiert déi an der 2D Grafik existéiert. Déi nei erstallt Achs handelt fir déi zwou Klassen ze trennen op Basis vun den Ziler déi virdru beschriwwe ginn. Nodeems d'Achs erstallt gouf, ginn d'Punkten an der 2D Grafik laanscht d'Achs plazéiert.
Et ginn dräi Schrëtt néideg fir d'Original Punkten op eng nei Positioun laanscht déi nei Achs ze plënneren. Am éischte Schrëtt gëtt d'Distanz tëscht den eenzelne Klassen heescht (d'Tëscht-Klass Varianz) benotzt fir d'Trennbarkeet vun de Klassen ze berechnen. Am zweete Schrëtt gëtt d'Varianz bannent de verschiddene Klassen berechent, duerch Bestëmmung vun der Distanz tëscht der Probe an der Moyenne fir déi betreffend Klass. Am leschte Schrëtt gëtt de méi nidderegen Dimensiounsraum erstallt, deen d'Varianz tëscht Klassen maximéiert.
D'LDA Technik erreecht déi bescht Resultater wann d'Moyene fir d'Zilklassen wäit vuneneen ausenee sinn. LDA kann d'Klassen net effektiv mat enger linearer Achs trennen wann d'Moyene fir d'Verdeelungen iwwerlappt.










