
AI 101
Overfitting çi ye?
Overfitting çi ye?
Dema ku hûn torgilokek neuralî perwerde dikin, pêdivî ye ku hûn ji zêdeperçebûnê dûr bisekinin. Overfitting Pirsgirêkek di nav fêrbûna makîneyê û statîstîkê de ye ku modelek şêwazên databasek perwerdehiyê pir baş fêr dibe, berhevoka daneya perwerdehiyê bi rengek bêkêmasî rave dike lê nekare hêza xweya pêşbîniya xwe bi komek daneyên din re giştî bike.
Ji bo vê yekê bi rengek din, di rewşek modelek zêde-guncan de ew ê pir caran rastiyek pir zêde li ser databasa perwerdehiyê nîşan bide lê rastbûna kêm li ser daneyên berhevkirî û di pêşerojê de bi modelê ve tê meşandin. Ew pênaseyek bilez a zêdebarkirinê ye, lê bila em bi hûrgulî bêtir li ser têgîna zêdebarkirinê biçin. Werin em binihêrin ka zêdeperçebûn çawa çêdibe û meriv çawa dikare jê dûr bixe.
Fêmkirina "Fit" û Underfitting
Arîkar e ku meriv li têgîna bindestkirinê binêre û "bihorîn” bi gelemperî dema ku li ser zêdebarkirinê nîqaş dikin. Dema ku em modelek perwerde dikin, em hewl didin ku çarçoveyek ku bikaribe xweza, an çîna hêmanan di nav databasê de pêşbîn bike, li ser bingeha taybetmendiyên ku wan tiştan vedibêje pêş bixe. Pêdivî ye ku modelek bikaribe nimûneyek di nav databasê de rave bike û çînên xalên daneya pêşerojê li gorî vê şêwazê pêşbîn bike. Model çiqas çêtir têkiliya di navbera taybetmendiyên koma perwerdehiyê de rave dike, modela me ew qas "guncantir" e.
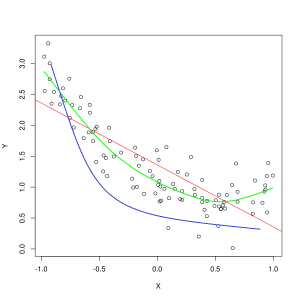
Xeta şîn pêşbîniyên ji hêla modêleka ku kêmasayî ye temsîl dike, dema ku xeta kesk modelek xweştir temsîl dike. Wêne: Pep Roca bi rêya Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Modelek ku têkiliya di navbera taybetmendiyên daneyên perwerdehiyê de kêm rave dike û ji ber vê yekê nekare mînakên daneya pêşerojê rast dabeş bike. bindestkirin daneyên perwerdehiyê. Ger hûn pêwendiya pêşbînkirî ya modelek bikêrhatî li hember hevberdana rastîn a taybetmendî û etîketan grafî bikin, pêşbînî dê ji nîşaneyê dûr bikevin. Ger me grafiyek bi nirxên rastîn ên komek perwerdehiyê ya binavkirî hebe, dê modelek bi tundî kêmasib piraniya xalên daneyê bi tundî winda bike. Modelek bi guncanek çêtir dibe ku rêyek di navenda nuqteyên daneyê de bibire, digel ku xalên daneya kesane tenê piçekî ji nirxên pêşbînîkirî dûr in.
Kêmbûn bi gelemperî dibe ku dema ku daneya têrê nake ku modelek rast biafirîne, an dema ku hewl didin ku modelek xêzik bi daneyên ne-xêzik re sêwiran bikin. Zêdetir daneyên perwerdehiyê an bêtir taybetmendiyên pir caran dê alîkariya kêmkirina kêmkirina kêmasiyan bikin.
Ji ber vê yekê çima em ê ne tenê modelek çêbikin ku her xalek di daneyên perwerdehiyê de bêkêmasî rave dike? Bê guman rastbûna bêkêmasî tê xwestin? Afirandina modelek ku qalibên daneyên perwerdehiyê pir baş fêr bûye ew e ku dibe sedema zêdeperçebûnê. Daneyên perwerdehiyê û daneyên din ên paşerojê yên ku hûn di modelê de dimeşînin dê tam ne yek bin. Ew ê di gelek waran de pir dişibin hev, lê ew ê di awayên sereke de jî cûda bin. Ji ber vê yekê, sêwirana modelek ku databasa perwerdehiyê bi rengek bêkêmasî rave dike tê vê wateyê ku hûn di derbarê têkiliya di navbera taybetmendiyan de teoriyek ku baş ji berhevokên daneya din re baş nayê gelemperî kirin bi dawî bikin.
Têgihiştina Overfitting
Zêdebûn çêdibe dema ku modelek hûrguliyên di nav databasa perwerdehiyê de pir baş fêr dibe, dibe sedem ku model zirarê bibîne dema ku pêşbîniyên li ser daneyên derveyî têne çêkirin. Ev dibe ku dema ku model ne tenê taybetmendiyên databasê fêr bibe, ew di heman demê de guheztinên rasthatî jî fêr bibe an jî deng di nav databasê de, girîngiyê dide van bûyerên rasthatî/ne girîng.
Dema ku modelên nehêl têne bikar anîn zêde guncan çêdibe, ji ber ku dema fêrbûna taybetmendiyên daneyê ew maqûltir in. Algorîtmayên fêrbûna makîneya neparametrîk bi gelemperî xwedan parametre û teknîkên cihêreng in ku dikarin werin sepandin da ku hestiyariya modelê ya li ser daneyan sînordar bikin û bi vî rengî zêdeperçebûnê kêm bikin. Wek mînak, modelên dara biryarê ji zêdebarkirinê re pir hesas in, lê teknîkek bi navê perçiqandinê dikare were bikar anîn da ku bi rengekî rasthatî hin hûrguliyên ku modelê fêr bûye jêbirin.
Ger we pêşbîniyên modelê li ser axên X û Y xêz bike, we dê rêzek pêşbîniyê hebe ku zigzag ber bi paş û paş ve diçe, ku vê rastiyê nîşan dide ku modelê pir hewil daye ku hemî xalên di databasê de bi cih bike. ravekirina wê.
Kontrolkirina Overfitting
Dema ku em modelek perwerde dikin, em bi îdeal dixwazin ku model xeletî neke. Dema ku performansa modelê ber bi çêkirina pêşbîniyên rast ve li ser hemî xalên daneyê yên di berhevoka perwerdehiyê de digihîje hev, guncan çêtir dibe. Modelek bi guncanek baş dikare hema hema hemî berhevoka perwerdehiyê bêyî zêdekirina rave bike.
Wekî ku modelek perwerde dike performansa wê bi demê re çêtir dibe. Rêjeya xeletiya modelê dê her ku dema perwerdehiyê derbas dibe kêm bibe, lê ew tenê heya xalek diyar kêm dibe. Xala ku tê de performansa modelê li ser ceribandina ceribandinê dîsa dest pê dike, bi gelemperî ew xala ku tê de zêdebûn çêdibe ye. Ji bo ku em ji modelekê re guncana çêtirîn bistînin, em dixwazin perwerdehiya modelê li xala windabûna herî kêm a li ser koma perwerdehiyê rawestînin, berî ku xeletî dîsa dest pê bike. Xala rawestanê ya çêtirîn dikare bi grafîkirina performansa modelê li seranserê dema perwerdehiyê û rawestandina perwerdehiyê dema ku winda herî hindik be were destnîşankirin. Lêbelê, xeterek bi vê rêbazê ya kontrolkirina zêdepergalê ev e ku destnîşankirina xala dawiya perwerdehiyê ya li ser bingeha performansa ceribandinê tê vê wateyê ku daneyên testê hinekî di prosedûra perwerdehiyê de dibe, û ew statûya xwe wekî daneyên safî "nedesthilatdar" winda dike.
Çend awayên cuda hene ku meriv dikare li dijî zêdeperçebûnê şer bike. Rêbazek kêmkirina zêdebarkirinê ev e ku meriv taktîkek ji nûve nimûnekirinê bikar bîne, ku bi texmînkirina rastbûna modelê tevdigere. Her weha hûn dikarin a bikar bînin çiraxî daneheva ji bilî koma testê û li şûna berhevoka testê rastbûna perwerdehiyê li hember berhevoka pejirandinê xêz bike. Ev daneyên testa we nayê dîtin. Rêbazek nûvekirinê ya populer pejirandina xaça K-folds e. Vê teknîkî dihêle hûn daneyên xwe li binkomên ku model li ser têne perwerde kirin dabeş bikin, û dûv re performansa modelê li ser binekomeyan tê analîz kirin da ku texmîn bike ka dê model li ser daneyên derveyî çawa pêk bîne.
Bikaranîna pejirandî ya xaçerê yek ji awayên çêtirîn e ku meriv rastbûna modelek li ser daneyên nedîtî texmîn bike, û dema ku bi danehevek rastdêrê re were hev kirin, pir caran dikare bi kêmanî were girtin.










