텍스트 프롬프트에서 3D 디지털 자산을 생성하는 능력은 AI와 컴퓨터 그래픽스에서 가장 흥미로운 최근 개발 중 하나를 대표합니다. 3D 디지털 자산 시장은 2024년에 283억 달러에서 2029년까지 518억 달러로 성장할 것으로 예상됨에 따라 텍스트에서 3D AI 모델은 게임, 영화, 전자 상거래 등 다양한 산업에서 콘텐츠 생성을 혁신하는 데 주요 역할을 할 것입니다. 하지만 이러한 AI 시스템은 정확히 어떻게 작동할까요? 이 기사에서는 텍스트에서 3D 생성의 기술적 세부 사항에 깊이 있는 분석을 제공하겠습니다.
3D 생성의 도전
텍스트에서 3D 자산을 생성하는 것은 2D 이미지 생성보다 훨씬 더 복잡한 작업입니다. 2D 이미지는 본질적으로 픽셀의 격자이지만 3D 자산은 3차원 공간에서 기하학, 텍스처, 재료 및 종종 애니메이션을 나타내야 합니다. 이러한 추가된 차원과 복잡성은 생성 작업을 훨씬 더 어려운 작업으로 만듭니다.
텍스트에서 3D 생성의 일부 주요 도전 과제는:
3D 기하학 및 구조를 나타내는 것
3D 표면에 걸쳐 일관된 텍스처 및 재료를 생성하는 것
다중 관점에서 물리적으로 가능하고 일관된 결과를 보장하는 것
세부 사항과 전역 구조를 동시에 캡처하는 것
렌더링 또는 3D 인쇄할 수 있는 자산을 생성하는 것
이러한 도전 과제를 해결하기 위해 텍스트에서 3D 모델은 여러 핵심 기술 및 기술을 활용합니다.
텍스트에서 3D 시스템의 핵심 구성 요소
대부분의 최첨단 텍스트에서 3D 생성 시스템은 몇 가지 핵심 구성 요소를 공유합니다:
텍스트 인코딩: 입력 텍스트 프롬프트를 수치 표현으로 변환
3D 표현: 3D 기하학 및 외관을 나타내는 방법
생성 모델: 3D 자산을 생성하는 핵심 AI 모델
렌더링: 3D 표현을 2D 이미지로 변환하여 시각화
자세한 내용을 살펴보겠습니다.
텍스트 인코딩
첫 번째 단계는 입력 텍스트 프롬프트를 AI 모델이 작업할 수 있는 수치 표현으로 변환하는 것입니다. 이는 일반적으로 BERT 또는 GPT와 같은 대규모 언어 모델을 사용하여 수행됩니다.
각각은 해상도, 메모리 사용 및 생성 용이성 측면에서 트레이드오프가 있습니다. 최근 모델은 높은 품질의 결과를 합리적인 계산 요구 사항으로 허용하기 때문에 암시적 함수 또는 NeRF를 사용합니다.
예를 들어, 우리는 서명된 거리 함수로 간단한 구를 나타낼 수 있습니다:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
생성 모델
텍스트에서 3D 시스템의 핵심은 3D 자산을 생성하는 핵심 AI 모델입니다. 대부분의 최첨단 모델은 2D 이미지 생성에서 사용되는 것과 유사한 확산 모델의 변형을 사용합니다.
확산 모델은 데이터에 점차적으로 노イズ를 추가한 다음 이过程을 역으로 학습하여 작동합니다. 3D 생성의 경우 이过程는 선택한 3D 표현의 공간에서 발생합니다.
확산 모델의 훈련 단계를 위한 간단한 유사 코드는 다음과 같습니다:
def diffusion_training_step(model, x_0, text_embedding):
# Sample a random timestep
t = torch.randint(0, num_timesteps, (1,))
# Add noise to the input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predict the noise
predicted_noise = model(x_t, t, text_embedding)
# Compute loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Training loop
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
생성 중에 우리는 순수한 노イズ에서 시작하여 반복적으로 노イズ를 제거하고, 텍스트 임베딩을 조건으로 합니다.
렌더링
결과를 시각화하고 훈련 중에 손실을 계산하기 위해 3D 표현을 2D 이미지로 렌더링해야 합니다. 이는 렌더링 과정을 통해 기울기를 전달할 수 있는 차별 가능한 렌더링 기술을 사용하여 수행됩니다.
메시 기반 표현의 경우 레이스터화 기반 렌더러를 사용할 수 있습니다:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
암시적 표현(예: NeRF)인 경우 일반적으로 렌더링을 위해 레이 마칭 기술을 사용합니다.
모두 함께: 텍스트에서 3D 파이프라인
이제 핵심 구성 요소를 다루었으므로 일반적인 텍스트에서 3D 생성 파이프라인에서 어떻게 함께 작동하는지 살펴보겠습니다:
텍스트 인코딩: 입력 프롬프트는 언어 모델을 사용하여 밀도 벡터 표현으로 인코딩됩니다.
초기 생성: 확산 모델은 텍스트 임베딩을 조건으로하여 초기 3D 표현(예: NeRF 또는 암시적 함수)을 생성합니다.
다중 관점 일관성: 모델은 생성된 3D 자산의 여러 관점을 렌더링하고 관점 간 일관성을 보장합니다.
세부화: 추가 네트워크는 기하학, 텍스처 또는 세부 사항을 향상시킬 수 있습니다.
최종 출력: 3D 표현은 하위 응용 프로그램에서 사용할 수 있도록 원하는 형식(예: 텍스처가 있는 메시)으로 변환됩니다.
이것은 코드에서 다음과 같이 표시될 수 있습니다:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
최상위 텍스트에서 3D 자산 모델
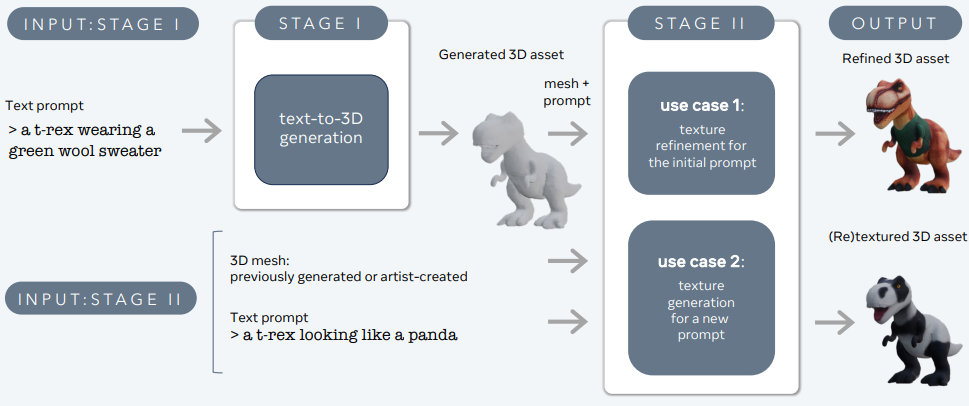
3DGen – Meta
3DGen은 텍스트 설명에서 3D 콘텐츠(예: 캐릭터, 프롭, 장면)를 생성하는 문제를 해결하도록 설계되었습니다.
3DGen은 물리 기반 렌더링(PBR)을 지원하며, 실제 응용 프로그램에서 3D 자산의 재조명을 위한 필수 구성 요소입니다. 또한 이전에 생성되거나 아티스트가 만든 3D 모양에 대한 새로운 텍스트 입력을 사용하여 생성된 또는 아티스트가 만든 3D 모양의 재생성 가능성을 제공합니다. 파이프라인에는 두 가지 핵심 구성 요소가 통합되어 있습니다. Meta 3D AssetGen 및 Meta 3D TextureGen은 각각 텍스트에서 3D 및 텍스트에서 텍스처 생성을 처리합니다.
Meta 3D AssetGen
Meta 3D AssetGen(Siddiqui et al., 2024)은 텍스트 프롬프트에서 3D 자산의 초기 생성을 담당하는 구성 요소입니다. 이 구성 요소는 약 30초 만에 텍스처 및 PBR 재료 맵이 있는 3D 메시를 생성합니다.
Meta 3D TextureGen
Meta 3D TextureGen(Bensadoun et al., 2024)은 AssetGen에서 생성된 텍스처를 세부화합니다. 또한 기존 3D 메시에 대한 새로운 텍스처를 추가 텍스트 설명을 사용하여 생성할 수도 있습니다. 이 단계는 약 20초 정도 소요됩니다.
Point-E (OpenAI)
Point-E, OpenAI에서 개발한 또 다른 주목할 만한 텍스트에서 3D 생성 모델입니다. DreamFusion과 달리 NeRF 표현을 생성하는 대신 Point-E는 3D 점 클라우드를 생성합니다.
Point-E의 주요 기능:
a) 2단계 파이프라인: Point-E는 먼저 텍스트에서 이미지 확산 모델을 사용하여 합성 2D 보기를 생성한 다음 이 이미지를 사용하여 3D 점 클라우드를 생성하는 두 번째 확산 모델을 조건으로 합니다.
b) 효율성: Point-E는 단일 GPU에서 몇 초 안에 3D 점 클라우드를 생성하도록 설계되어 계산적으로 효율적입니다.
c) 색상 정보: 모델은 기하학 및 외관 정보를 모두 보존하는 색상이 있는 점 클라우드를 생성할 수 있습니다.
제한:
메시 또는 NeRF 기반 접근 방식에 비해 낮은忠実도
많은 하위 응용 프로그램에서 추가 처리가 필요한 점 클라우드
Shap-E (OpenAI):
Point-E를 기반으로 OpenAI는 Shap-E를 도입했습니다. 이는 3D 메시를 생성하는 대신 점 클라우드를 생성합니다. 이는 Point-E의 일부 제한 사항을 해결하면서 계산 효율성을 유지합니다.
Shap-E의 주요 기능:
a) 암시적 표현: Shap-E는 3D 객체의 암시적 표현(서명된 거리 함수)을 학습하여 생성합니다.
b) 메시 추출: 모델은 암시적 표현을 다중체 알고리즘의 차별 가능한 구현을 사용하여 폴리곤 메시로 변환합니다.
c) 텍스처 생성: Shap-E는 3D 메시에 대한 텍스처도 생성할 수 있으며, 결과적으로 더 시각적으로 매력적인 출력이 생성됩니다.
이점:
빠른 생성 시간(초에서 분까지)
렌더링 및 하위 응용 프로그램에 적합한 직접 메시 출력
기하학 및 텍스처를 모두 생성할 수 있는 기능
GET3D (NVIDIA):
GET3D, NVIDIA 연구원에 의해 개발되었습니다. 이는 높은 품질의 텍스처가 있는 3D 메시를 생성하는 또 다른 강력한 텍스트에서 3D 생성 모델입니다.
GET3D의 주요 기능:
a) 명시적 표면 표현: DreamFusion 또는 Shap-E와 달리 GET3D는 중간 암시적 표현 없이 명시적 표면 표현(메시)을 직접 생성합니다.
b) 텍스처 생성: 모델에는 높은 품질의 텍스처를 학습하고 3D 메시에 대한 텍스처를 생성하기 위한 차별 가능한 렌더링 기술이 포함되어 있습니다.
c) GAN 기반 아키텍처: GET3D는 훈련 후 빠른 생성을 허용하는 생성적 적대적 네트워크(GAN) 접근 방식을 사용합니다.
이점:
높은 품질의 기하학 및 텍스처
빠른 추론 시간
3D 렌더링 엔진과의 직접 통합
제한:
일부 객체 범주에 대한 3D 훈련 데이터가 부족할 수 있음
결론
텍스트에서 3D AI 생성은 3D 콘텐츠를 생성하고 상호 작용하는 방식에 대한 근본적인 변화를 나타냅니다. 고급 딥 러닝 기술을 활용하여 이러한 모델은 간단한 텍스트 설명에서 복잡하고 높은 품질의 3D 자산을 생성할 수 있습니다. 기술이 계속 발전함에 따라 게임, 영화, 제품 디자인 및 건축과 같은 산업을 혁신할越来越 tinh vi하고 능력있는 텍스트에서 3D 시스템을 기대할 수 있습니다.
지난 5년 동안私は Machine Learning과 Deep Learning의 매력적인 세계에 몰두해 왔습니다.私の情熱と専門知識は、AI/ML에 중점을 둔 50개 이상의 다양한 소프트웨어 엔지니어링 프로젝트에 기여했습니다.私の継続的な 호기심은 또한 자연어 처리 분야로私の 관심을 끌었고, 더 깊이 탐구하고 싶은 분야입니다.