인공지능
Enfabrica, Ethernet 기반 메모리 패브릭 공개… 대규모 AI 추론 재정의 가능
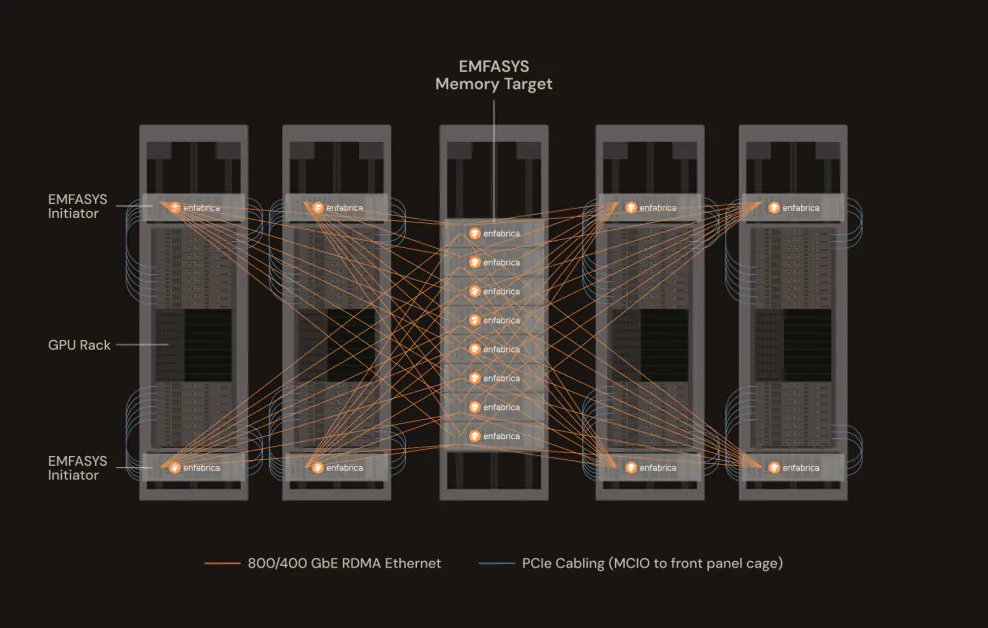
Enfabrica, Nvidia가 지원하는 실리콘밸리 기반 스타트업은 대규모 AI 워크로드가 배포되고 확장되는 방식을 크게 바꿀 수 있는 획기적인 제품을 공개했습니다. 회사의 새로운 Elastic Memory Fabric System (EMFASYS)은 생성적 AI 추론의 핵심 병목 현상을 해결하기 위해 설계된 최초의 상용 Ethernet 기반 메모리 패브릭입니다. 메모리 액세스.
AI 모델이 더 복잡하고 상황 인식 및 지속성이 높아지면서 사용자 세션당大量의 메모리가 필요한 시점에 EMFASYS는 메모리를 계산에서 분리하는 새로운 접근 방식을 제공하여 AI 데이터 센터가 성능을 크게 개선하고 비용을 절감하며 가장 비싼 자원인 GPU의 활용도를 높일 수 있습니다.
메모리 패브릭이란 무엇이며 왜 중요할까요?
전통적으로 데이터 센터 내의 메모리는 서버 또는 노드에紧密하게 결합되어 있습니다. 각 GPU 또는 CPU에는 직접 연결된 고대역폭 메모리(HBM для GPU 또는 DRAM для CPU)만 액세스할 수 있습니다. 이 아키텍처는 워크로드가 작고 예측 가능할 때 잘 작동합니다. 그러나 생성적 AI는 게임을 변경했습니다. LLM은 대형 컨텍스트 창, 사용자 기록 및 멀티 에이전트 메모리에 액세스해야 하며 모두 지연 없이 빠르게 처리되어야 합니다. 이러한 메모리 요구는 종종 로컬 메모리의 사용 가능한 용량을 초과하여 GPU 코어가 중단되고 인프라 비용이 증가하는 병목 현상을 생성합니다.
메모리 패브릭은 메모리를 공유, 분산 리소스로 변환하여 클러스터의 모든 GPU 또는 CPU에서 액세스할 수 있는 네트워크 연결 메모리 풀을 제공함으로써 이를 해결합니다. 데이터 센터 랙 내에 “메모리 클라우드”를 생성하는 것으로 생각할 수 있습니다. 서버 간에 메모리를 복제하거나 비싼 HBM을 과부화시키지 않고 메모리 패브릭을 사용하면 메모리를 집계, 분리 및 수요에 따라 고속 네트워크를 통해 액세스할 수 있습니다. 이는 AI 추론 워크로드가 단일 노드의 물리적 메모리 제한에 구속되지 않고 더 효율적으로 확장할 수 있도록 합니다.
Enfabrica의 접근 방식: Ethernet와 CXL, 함께 작동
EMFASYS는 RDMA over Ethernet와 Compute Express Link (CXL)라는 두 가지 강력한 기술을 결합하여 랙 규모의 메모리 아키텍처를 달성합니다. 전자는 표준 Ethernet 네트워크에서 초저지연, 고처리량 데이터 전송을 가능하게 합니다. 후자는 메모리가 CPU 및 GPU에서 분리되어 공유 리소스로 풀링되어 고속 CXL 링크를 통해 액세스할 수 있습니다.
EMFASYS의 핵심은 Enfabrica의 ACF-S 칩, 즉 3.2 테라비트당 초(Tbps) “SuperNIC”로, 네트워킹 및 메모리 제어를 단일 장치로 결합합니다. 이 칩은 서버가 랙 전체에 분산된大量의 저렴한 DRAM(노드당 최대 18테라바이트)에 인터페이스할 수 있도록 합니다. 중요한 것은 표준 Ethernet 포트를 사용하여 이를 수행한다는 것입니다. 이는 운영자가专有 인터커넥트에 투자하지 않고 기존 데이터 센터 인프라를 활용할 수 있도록 합니다.
EMFASYS가 특히 매력적인 이유는 비용이 많이 드는 GPU 연결 HBM에서 메모리 제한 워크로드를 동적으로 오프로드하여 훨씬 더 저렴한 DRAM으로 옮길 수 있는 기능입니다. 이는 마이크로초 수준의 액세스 지연을 유지하는 동시에 수행됩니다. EMFASYS의 소프트웨어 스택에는 지연을 숨기고 시스템에서 실행 중인 LLM에 투명한 방식으로 메모리 이동을 오케스트레이팅하는 지능형 캐싱 및 부하 분산 메커니즘이 포함되어 있습니다.
AI 산업에 대한 영향
이는 단순히巧妙한 하드웨어 솔루션이 아니라 AI 인프라가 구축되고 확장되는 방식에 대한 철학적 전환을 나타냅니다. 생성적 AI가 새로운 기능에서 필수 기능으로 전환함에 따라 일일로 처리되는 사용자 쿼리가 수십억 개가 되면서 이러한 모델을 제공하는 비용은 많은 회사에서 지속할 수 없게 되었습니다. GPU는 컴퓨팅이 부족해서가 아니라 메모리를 기다리면서 종종 활용되지 않습니다. EMFASYS는 이러한 불균형을 직접 해결합니다.
Enfabrica는 Ethernet을 통해 액세스할 수 있는 풀링된, 패브릭 연결 메모리를 제공하여 데이터 센터 운영자는 계속해서 더 많은 GPU 또는 HBM을 구매하는 대신 모듈식으로 메모리 용량을 증가시킬 수 있습니다. 이는 저렴한 DRAM과 지능형 네트워킹을 사용하여 전체 풋프린트를 줄이고 AI 추론의 경제성을 개선합니다.
影响은 즉각적인 비용 절감을 넘어섭니다. 이러한 종류의 분산 아키텍처는 메모리 서비스 모델을 위한 길을 열어줍니다. 여기서 컨텍스트, 기록 및 에이전트 상태는 단일 세션 또는 서버를 넘어 지속할 수 있으며 더 지능적이고 개인화된 AI 시스템으로의 길을 열어줍니다. 또한 메모리 제한 없이 워크로드를 랙 또는 전체 데이터 센터에 탄력적으로 분산할 수 있는 더 강력한 AI 클라우드를 위한 무대를 마련합니다.
미래를 향해
Enfabrica의 EMFASYS는 현재 선택된 고객과 샘플링되고 있으며 회사가 이러한 파트너가 누구인지 공개하지는 않았지만 로이터 통신에 따르면 주요 AI 클라우드 제공업체가 이미 시스템을 테스트 중이라고 보고합니다. 이는 Enfabrica를 단순한 구성 요소 공급자로 пози션하는 것이 아니라 차세대 AI 인프라의 핵심 활성화자로 만듭니다.
메모리를 계산에서 분리하고 고속, 저렴한 Ethernet 네트워크를 통해 제공함으로써 Enfabrica는 추론을妥協 없이 확장할 수 있는 새로운 AI 아키텍처의 기초를 마련하고 있습니다. 여기서 리소스가 더 이상 중단되지 않고 대형 언어 모델을 배포하는 경제성이终于 의미가 있습니다.
컨텍스트가 풍부한 멀티 에이전트 AI 시스템으로 정의되는 세계에서 메모리는 더 이상 보조 역할이 아닙니다. 그것은舞台입니다. Enfabrica는 최고의舞台를 구축하는 사람이 향후 수년간 AI의 성능을 정의할 것이라고 베팅합니다.










