Artificial Intelligence
Gemma 2 の完全ガイド: Google の新しいオープン大規模言語モデル

ジェマ2 Gemma 2は、前モデルをベースに、性能と効率性の向上に加え、研究用途と実用用途の両方で特に魅力的な革新的な機能群を備えています。Gemma XNUMXの特徴は、はるかに大型の専用モデルに匹敵する性能を、より幅広いユーザーアクセスと、より小規模なハードウェア構成での使用を想定して設計されている点です。
Gemma 2 の技術仕様とアーキテクチャを詳しく調べていくうちに、その設計の独創性にますます感銘を受けました。このモデルには、新しい注意メカニズムや安定性を訓練するための革新的なアプローチなど、いくつかの高度な技術が組み込まれており、それがその驚くべき機能に貢献しています。

Google オープンソース LLM Gemma
この包括的なガイドでは、Gemma 2のアーキテクチャ、主要機能、そして実用的なアプリケーションを詳細に解説します。AIの経験豊富な実践者から、この分野に熱心な初心者まで、この記事はGemma 2の仕組みと、そのパワーを自身のプロジェクトでどのように活用できるかについて、貴重な洞察を提供することを目的としています。
Gemma 2とは何ですか?
Gemma 2は、Googleの最新のオープンソース大規模言語モデルです。軽量でありながらパワフルに設計されています。GoogleのGeminiモデルの開発に使用されたのと同じ研究と技術に基づいて構築されており、最先端のパフォーマンスをより手頃な価格で提供します。Gemma 2にはXNUMXつのサイズがあります。
ジェマ2 9B: 9億のパラメータモデル
ジェマ2 27B: 27億のパラメータを持つより大規模なモデル
各サイズには 2 つのバリエーションがあります。
ベースモデル: 膨大なテキストデータコーパスで事前トレーニング済み
命令調整(IT)モデル: 特定のタスクでのパフォーマンス向上のために微調整されています
Google AI Studioのモデルにアクセスする: Google AI スタジオ – ジェマ 2
ここで論文を読む: ジェマ 2 技術レポート
主な機能と改善点
Gemma 2 では、前モデルに比べていくつかの重要な進歩がもたらされています。
1. トレーニングデータの増加
モデルは大幅に多くのデータでトレーニングされています。
ジェマ2 27B: 13兆トークンでトレーニング
ジェマ2 9B: 8兆トークンでトレーニング
この拡張データセットは、主に Web データ (ほとんどが英語)、コード、数学で構成されており、モデルのパフォーマンスと汎用性の向上に貢献します。
2. スライディングウィンドウの注意
Gemma 2 は、注目メカニズムに対する新しいアプローチを実装しています。
他のすべてのレイヤーは、4096トークンのローカルコンテキストを持つスライディングウィンドウアテンションを使用します。
交互レイヤーは、8192トークンのコンテキスト全体にわたって完全な二次グローバルアテンションを採用します。
このハイブリッド アプローチは、効率性と入力内の長距離依存関係をキャプチャする機能のバランスをとることを目的としています。
3. ソフトキャッピング
トレーニングの安定性とパフォーマンスを向上させるために、Gemma 2 ではソフト キャップ メカニズムが導入されています。
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
この手法により、ハード トランケーションを行わずにロジットが過度に大きくなるのを防ぎ、トレーニング プロセスを安定させながらより多くの情報を維持できます。
- ジェマ2 9B: 9億のパラメータモデル
- ジェマ2 27B: 27億のパラメータを持つより大規模なモデル
各サイズには 2 つのバリエーションがあります。
- 基本モデル: 膨大なテキストデータコーパスで事前トレーニング済み
- 命令調整(IT)モデル:特定のタスクでのパフォーマンス向上のために微調整されています
4. 知識の蒸留
9B モデルの場合、Gemma 2 は知識蒸留技術を採用しています。
- 事前トレーニング: 9Bモデルは、初期トレーニング中に大規模な教師モデルから学習します。
- トレーニング後: 9Bモデルと27Bモデルは両方とも、ポリシー蒸留を使用してパフォーマンスを改善します。
このプロセスにより、より小さなモデルでより大きなモデルの機能をより効果的に取り込むことができます。
5. モデルのマージ
Gemma 2 は、Warp と呼ばれる新しいモデル結合技術を利用しており、複数のモデルを XNUMX つの段階で結合します。
- 強化学習の微調整中の指数移動平均(EMA)
- 複数のポリシーを微調整した後の球面線形補間(SLERP)
- 最終ステップとしての初期化に向けた線形補間(LITI)
このアプローチは、より堅牢で高性能な最終モデルを作成することを目的としています。
パフォーマンスベンチマーク
Gemma 2 は、さまざまなベンチマークで優れたパフォーマンスを発揮します。
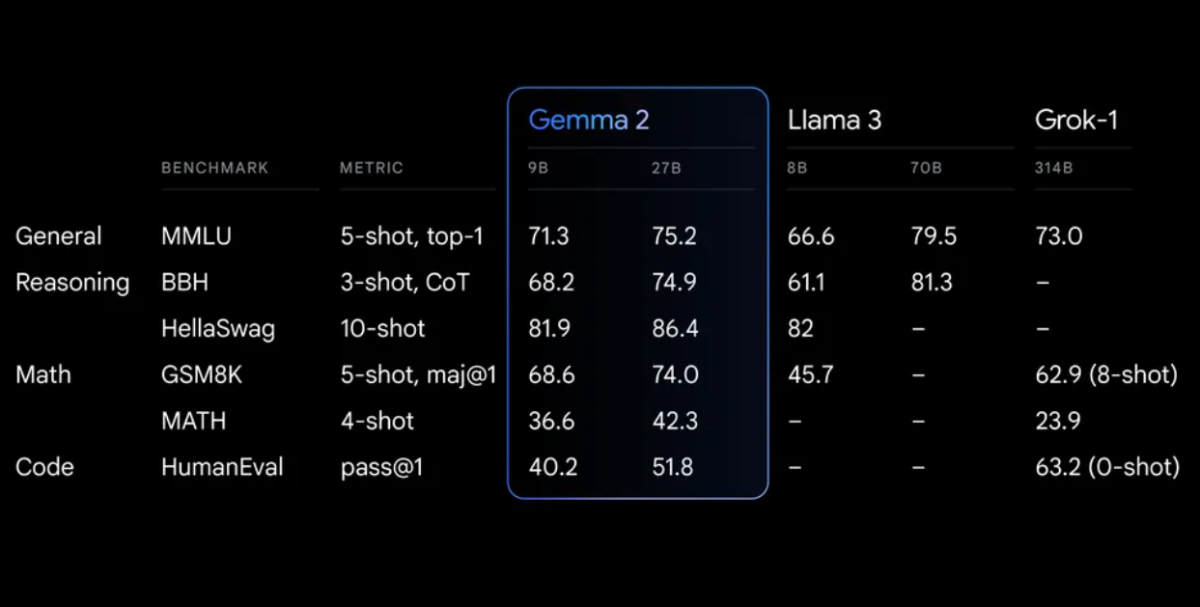
Gemma 2は、優れたパフォーマンスと推論効率の両方を実現するように設計された再設計されたアーキテクチャを採用しています。
Gemma 2 を使い始める
プロジェクトで Gemma 2 を使い始めるには、いくつかのオプションがあります。
1. Google AIスタジオ
ハードウェアを必要とせずに簡単に実験したい場合は、Gemma 2にアクセスできます。 Google AIスタジオ.
2.ハグフェイストランスフォーマー
Gemma 2は人気の ハグ顔 トランスフォーマーライブラリ。使い方は次のとおりです。
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
TensorFlow ユーザーの場合、Gemma 2 は Keras を通じて利用できます。
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
高度な使用法: Gemma 2 を使用したローカル RAG システムの構築
Gemma 2の強力な応用例の一つは、検索拡張生成(RAG)システムの構築です。Gemma 2とNomic埋め込みを用いて、シンプルで完全にローカルなRAGシステムを構築してみましょう。
ステップ 1: 環境のセットアップ
まず、必要なライブラリがインストールされていることを確認します。
pip install langchain ollama nomic chromadb
ステップ2: ドキュメントのインデックス作成
ドキュメントを処理するためのインデクサーを作成します。
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
ステップ3: RAGシステムのセットアップ
それでは、Gemma 2 を使用して RAG システムを作成しましょう。
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
この RAG システムは、言語モデルに Gemma 2 から Ollama を使用し、ドキュメント検索に Nomic 埋め込みを使用します。インデックス付けされたドキュメントに基づいて質問することができ、関連するソースからのコンテキストを含む回答が提供されます。
ジェマ2の微調整
特定のタスクやドメインでは、Gemma 2 を微調整する必要がある場合があります。以下は、Hugging Face Transformers ライブラリを使用した基本的な例です。
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
特定の要件と計算リソースに基づいてトレーニング パラメータを調整することを忘れないでください。
倫理的考慮事項と制限
Gemma 2 は優れた機能を提供しますが、その限界と倫理的な考慮事項を認識することが重要です。
- バイアス: すべての言語モデルと同様に、Gemma 2 はトレーニング データに存在するバイアスを反映する可能性があります。常に出力を批判的に評価してください。
- 事実の正確さ: Gemma 2 は非常に優秀ですが、不正確な情報や矛盾した情報を生成する場合があります。信頼できる情報源から重要な事実を確認してください。
- コンテキストの長さ: Gemma 2 のコンテキストの長さは 8192 トークンです。長いドキュメントや会話の場合は、コンテキストを効果的に管理するための戦略を実装する必要がある場合があります。
- 計算リソース特に 27B モデルの場合、効率的な推論と微調整には多大な計算リソースが必要になる可能性があります。
- 責任ある使用: Google の責任ある AI の実践を遵守し、Gemma 2 の使用が倫理的な AI 原則に準拠していることを確認してください。
結論
Gemma 2 は、スライディング ウィンドウ アテンション、ソフト キャップ、新しいモデル マージ テクニックなどの高度な機能を備えており、幅広い自然言語処理タスクに対応する強力なツールとなっています。
単純な推論、複雑な RAG システム、または特定のドメイン向けに微調整されたモデルなど、プロジェクトで Gemma 2 を活用することで、データとプロセスに対する制御を維持しながら、SOTA AI のパワーを活用できます。












