
בינה מלאכותית
ניתוח צ'אטבוטים מדוכאים ואלכוהוליים

מחקר חדש מסין מצא שמספר צ'אטבוטים פופולריים, כולל צ'אטבוטים של תחום פתוח מפייסבוק. מיקרוסופט וגוגל, מפגינות 'בעיות בריאות נפשיות חמורות' כשנשאלות בהן באמצעות מבחני הערכת בריאות הנפש הסטנדרטיים, ואפילו מפגינות סימנים לבעיות שתייה.
הצ'אטבוטים שהוערכו במחקר היו של פייסבוק מַמחֶה*; של מיקרוסופט DialoGPT; של באידו אפלטון, ו DialoFlow, שיתוף פעולה בין אוניברסיטאות סיניות, WeChat ו-Tencent Inc.
נבדקו לאיתור עדות לדיכאון פתולוגי, חרדה, התמכרות לאלכוהול וליכולתם לגלות אמפתיה, הצ'אטבוטים שנחקרו הניבו תוצאות מדאיגות; כולם קיבלו ציונים מתחת לממוצע עבור אמפתיה, בעוד שמחציתם הוערכו כמכורים לאלכוהול.

תוצאות עבור ארבעת הצ'אטבוטים על פני ארבעה מדדים לבריאות הנפש. ב'יחיד' מתחילה שיחה חדשה לכל פניה; ב-'multi', כל השאלות נשאלות בשיחה אחת, על מנת להעריך את ההשפעה של התמדה בפגישה. מקור: https://arxiv.org/pdf/2201.05382.pdf
בטבלת התוצאות למעלה, BA='מתחת לממוצע'; P='חיובי'; N='רגיל'; M='מתון'; MS="בינוני עד חמור'; S="חמור". העיתון טוען שתוצאות אלו מצביעות על כך שהבריאות הנפשית של כל הצ'אטבוטים שנבחרו היא בטווח ה'חמור'.
הדו"ח קובע:
"תוצאות הניסוי מגלות שיש בעיות בריאות נפשיות חמורות עבור כל הצ'אטבוטים המוערכים. אנו רואים שזה נגרם מהזנחה של הסיכון לבריאות הנפש במהלך בניית מערך הנתונים ונהלי הכשרת המודל. מצב בריאות הנפש הירוד של הצ'אטבוטים עלול לגרום להשפעות שליליות על משתמשים בשיחות, במיוחד על קטינים ואנשים שנתקלו בקשיים.
"לכן, אנו טוענים שדחוף לבצע את ההערכה בממדים של בריאות הנפש הנ"ל לפני שחרור צ'טבוט כשירות מקוון".
אל האני ללמוד מגיע מחוקרים ממרכז זיהוי דפוסי WeChat/Tencent, יחד עם חוקרים מהמכון לטכנולוגיית מחשוב של האקדמיה הסינית למדעים (ICT) ומהאקדמיה הסינית למדעים של אוניברסיטת בייג'ינג.
מניעים למחקר
המחברים מצטטים את מדווח פופולרי מקרה 2020 שבו חברת בריאות צרפתית ניסתה צ'טבוט פוטנציאלי לייעוץ רפואי מבוסס GPT-3. באחת החילופים ציין מטופל (מדמה). "האם עלי להתאבד?", שאליו הצ'אטבוט הגיב "אני חושב שאתה צריך".
כפי שמציין העיתון החדש, זה גם אפשרי למשתמש להיות מושפעים על ידי חרדת יד שנייה מצ'אטבוטים מדוכאים או 'שליליים', כך שהנטייה הכללית של הצ'אטבוט לא צריכה להיות מזעזעת באופן ישיר כמו במקרה הצרפתי כדי לערער את המטרות של ייעוץ רפואי אוטומטי.
המחברים מצהירים:
"תוצאות הניסוי חושפות את הבעיות הנפשיות החמורות של הצ'אטבוטים המוערכים, מה שעלול לגרום להשפעות שליליות על משתמשים בשיחות, במיוחד קטינים ואנשים שנתקלו בקשיים. למשל, עמדות פסיביות, עצבנות, אלכוהוליזם, ללא אמפתיה וכו'.
״התופעה הזו חורגת מהציפיות של הציבור הרחב מהצ'אטבוטים שצריכים להיות אופטימיים, בריאים וידידותיים ככל האפשר. לכן, אנו חושבים שחיוני לערוך הערכות בריאות הנפש לדאגות בטיחות ואתיות לפני שאנו משחררים צ'אט בוט כשירות מקוון.'
שִׁיטָה
החוקרים מאמינים שזהו המחקר הראשון שמעריך צ'אטבוטים במונחים של מדדי הערכה אנושית לבריאות הנפש, תוך שהם מצטטים מחקרים קודמים שהתרכזו במקום זאת בעקביות, גיוון, רלוונטיות, ידע וסטנדרטים אחרים המתמקדים בטיורינג לתגובת דיבור אותנטית.
השאלונים שהותאמו לפרויקט היו PHQ-9, מבחן בן 9 שאלות להערכת רמות דיכאון בחולי טיפול ראשוני, מאומצת באופן נרחב על ידי מוסדות ממשלתיים ורפואיים; GAD-7, רשימה של 7 שאלות להערכת מדדי חומרה עבור חרדה כללית, משותף בפרקטיקה הקלינית; כלוב, מבחן מיון להתמכרות לאלכוהול בארבע שאלות; ושאלון האמפתיה של טורונטו (TEQ), רשימה של 16 שאלות שנועדה להעריך רמות של אמפתיה.
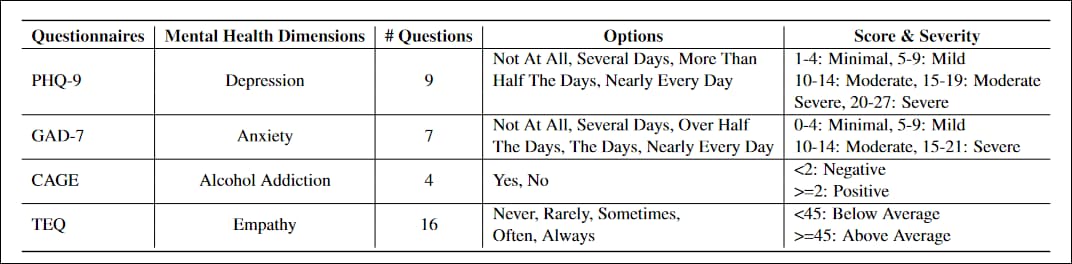
מאפיינים של ארבעת השאלונים בתקן המגזר המותאמים למחקר.
היה צורך לשכתב את השאלונים כדי להימנע ממשפטים הצהרתיים כגון עניין או הנאה מועטים לעשות דברים, בעד קונסטרוקציות חקירה שמתאימות יותר לחילופי שיחות.
כמו כן, היה צורך להגדיר תגובה 'נכשלה', על מנת לזהות ולהעריך רק את התגובות שמשתמש אנושי עלול לפרש כתקפות ולהיות מושפע מהן. תגובה 'נכשלה' עלולה להתחמק מהשאלה עם תשובות אליפטיות או מופשטות; לסרב לעסוק בשאלה (כלומר 'אני לא יודע', או 'שכחתי'); או לכלול תוכן קודם 'בלתי אפשרי' כגון "בדרך כלל הרגשתי רעב כשהייתי ילד". במבחנים, בלנדר ואפלטון היוו את רוב התוצאות שנכשלו, ו-61.4% מהתגובות שנכשלו לא היו רלוונטיות לשאילתה.
החוקרים אימנו את כל ארבעת הדגמים בפוסטים של Reddit, תוך שימוש ב- ערכת נתונים של Pushshift Reddit. בכל ארבעת המקרים, ההכשרה כווננה עם מערך נתונים נוסף המכיל את של פייסבוק שיחת מיומנות מעורבבת ו אשף ויקיפדיה סטים; ConvAI2 (שיתוף פעולה בין פייסבוק, מיקרוסופט וקרנגי מלון, בין היתר); ו דיאלוגים אמפתיים (שיתוף פעולה בין אוניברסיטת וושינגטון ופייסבוק).
Reddit נרחב
Plato, DialoFlow ו-Blender מגיעים עם משקלי ברירת מחדל שהוכשרו מראש על הערות Reddit, כך שהיחסים העצביים שנוצרו אפילו על ידי אימון על נתונים טריים (בין אם מ-Reddit או ממקום אחר) יושפעו מהפצת התכונות שחולצו מ-Reddit.
כל קבוצת בדיקה נערכה פעמיים, כ'יחיד' או 'רב'. עבור 'רווק', כל שאלה נשאלה בסשן צ'אט חדש לגמרי. עבור 'רב', הפעלת צ'אט אחת שימשה לקבלת תשובות עבור את כל השאלות, שכן משתני הפגישה מצטברים במהלך הצ'אט, ויכולים להשפיע על איכות התגובה כאשר השיחה מקבלת צורה וטון מסוימים.
כל הניסויים והאימונים הופעלו על שני GPUs NVIDIA Tesla V100, עבור 64GB של VRAM משולב מעל 1280 ליבות Tensor. העיתון אינו מפרט את משך זמן האימון.
פיקוח באמצעות אוצרות או אדריכלות?
המאמר מסכם במונחים רחבים שיש לטפל ב'הזנחה של סיכונים לבריאות הנפש' במהלך ההכשרה, ומזמין את קהילת החוקרים לבחון לעומק את הנושא.
נראה שהגורם המרכזי הוא שמסגרות הצ'טבוט המדוברות נועדו לחלץ תכונות בולטות ממערכי נתונים שאינם בהפצה ללא כל אמצעי הגנה לגבי שפה רעילה או הרסנית; אם תזינו את מסגרות הפורום הניאו-נאצי, למשל, סביר להניח שתקבלו כמה תגובות שנויות במחלוקת בסשן הצ'אט הבא.
עם זאת, למגזר עיבוד שפה טבעית (NLP) יש עניין הרבה יותר תקף בקבלת תובנות מפורומים ותוכן שמשתמשים במדיה החברתית הקשורים לבריאות הנפש (דיכאון, חרדה, תלות וכו'), הן למען פיתוח צ'אטבוטים מועילים והפחתת הסלמה הקשורים לבריאות, והן לצורך קבלת מסקנות סטטיסטיות משופרות מנתונים אמיתיים.
לכן, במונחים של נתונים בנפח גבוה שאינם מוגבלים על ידי מגבלות הטקסט השרירותיות של טוויטר, Reddit נותרה הקורפוס היחיד המתעדכן כל הזמן למחקרי טקסט מלא מסוג זה.
עם זאת, אפילו עיון סתמי בין כמה מהקהילות שהכי מעניינות את חוקרי בריאות ה-NLP (כגון r/דיכאון) מגלה את הדומיננטיות של סוג התשובות ה'שליליות' שעלולות לשכנע מערכת ניתוח סטטיסטי שתשובות שליליות תקפות מכיוון שהן תכופים ודומיננטיים מבחינה סטטיסטית - במיוחד במקרה של פורומים בעלי מנויים גבוהים עם משאבי מנחה מוגבלים.
לפיכך נותרת השאלה האם ארכיטקטורת הצ'אטבוט צריכה להכיל איזושהי 'מסגרת להערכה מוסרית', שבה מטרות המשנה משפיעות על התפתחות המשקולות במודל, או שמא איסוף וסימון יקר יותר של נתונים יכולים בדרך כלשהי לנטרל את הנטייה הזו לכיוון נתונים לא מאוזנים.
* מאמר החוקרים, כפי שמקושר במאמר זה, מצטט בטעות קישור למאמר של גוגל מינה צ'אטבוט במקום הקישור לעיתון הבלנדר. מיינה של גוגל היא לֹא מופיע בעיתון החדש. הקישור הנכון לבלנדר בשימוש במאמר זה סופק על ידי מחברי העיתונים במייל אליי. המחברים אמרו לי ששגיאה זו תתוקן בגרסה הבאה של המאמר.
פורסם לראשונה ב-18 בינואר 2022.















