
בינה מלאכותית
גוגל צופה מערכת שאילתות דמוית GPT-3, ללא תוצאות חיפוש

מאמר חדש של ארבעה חוקרים של גוגל מציע מערכת 'מומחה' המסוגלת לענות באופן סמכותי על שאלות המשתמשים מבלי להציג רשימה של תוצאות חיפוש אפשריות, בדומה לפרדיגמת השאלות והתשובות שהגיעה לידיעת הציבור בעקבות הופעתו של GPT-3 בעבר שָׁנָה.
השמיים מאמר, זכאי חשיבה מחודשת על חיפוש: להוציא מומחים מדילטנטים, מציע שהסטנדרט הנוכחי של הצגת רשימת תוצאות חיפוש למשתמש בתגובה לשאילתה הוא 'נטל קוגניטיבי', ומציע שיפורים ביכולתה של מערכת עיבוד שפה טבעית (NLP) לספק תגובה סמכותית ומוחלטת. .
לפי המודל המוצע של 'מומחה', אורקל חוצה-דומיינים, אלפי מקורות תוצאות החיפוש האפשריים יהיו אפויים במודל שפה במקום להיות זמין במפורש כמשאב חקרני למשתמשים להעריך ולנווט בעצמם. מקור: https://arxiv.org/pdf/2105.02274.pdf
המאמר, בהובלת דונלד מצלר ב-Google Research, מציע שיפורים בסוג תגובות האורקל מרובי-דומיינים שניתן להשיג כיום ממודלים של שפה אוטורגרסיבית של למידה עמוקה כמו GPT-3. השיפורים העיקריים הצפויים הם א) שהמודל יהיה מסוגל לצטט במדויק את המקורות שהודיעו לתגובה, וב) שהמודל יהיה מנוע מ'הוזה' תגובות או המצאת חומר מקור לא קיים, וזה כרגע בעיה בארכיטקטורות כאלה.
הדרכה ויכולות ריבוי דומיינים
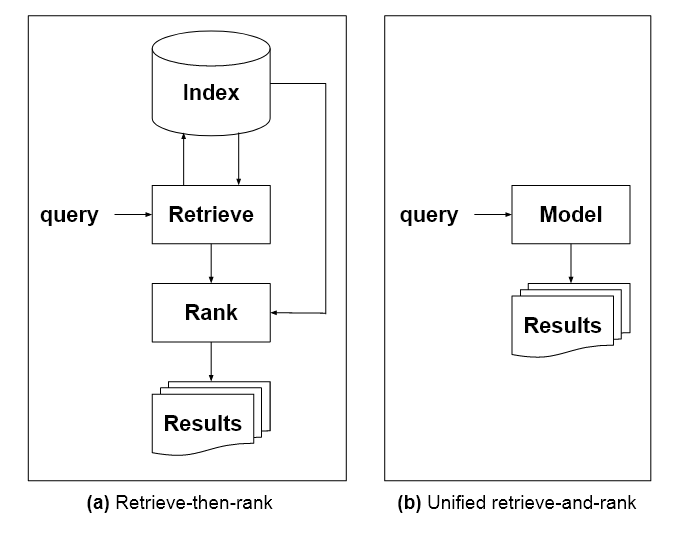
בנוסף, מודל השפה המוצע, המאופיין במאמר כ'מודל יחיד לכל משימות אחזור המידע', יוכשר במגוון תחומים, כולל תמונות וטקסט. זה יצטרך גם הבנה לגבי מקור הידע, שחסר בארכיטקטורות בסגנון GPT-3.
"כדי להחליף אינדקסים במודל אחד ומאוחד, חייב להיות למודל עצמו ידע על היקום של מזהי מסמכים, באותו אופן שבו יש לאינדקסים מסורתיים. אחת הדרכים להשיג זאת היא להתרחק מ-LMs מסורתיים לכיוון מודלים של קורפוס המדגימים במשותף יחסי מונח-מונח, מונח-מסמך ומסמך-מסמך.'

בתמונה למעלה, מתוך המאמר, שלוש גישות בתגובה לפניית משתמש: משמאל, מודלי השפה הגלומים בתוצאות החיפוש האלגוריתמיות של גוגל בחרו ותעדפו את 'התשובה הטובה ביותר', אך השאירו אותה כתוצאה העליונה מבין רבים. מרכז, תגובה שיחה בסגנון GPT-3, שמדברת בסמכות, אך אינה מצדיקה את טענותיה או מצטטת מקורות. נכון, מערכת המומחים המוצעת משלבת את 'התגובה הטובה ביותר' מתוצאות החיפוש המדורגות ישירות לתשובה דידקטית, עם ציטוטים של הערות שוליים בסגנון אקדמי (לא מתוארים בתמונה המקורית) המציינים את המקורות המודיעים על התגובה.
הסרת תוצאות רעילות ולא מדויקות
החוקרים מציינים כי האופי הדינמי והמעודכן כל הזמן של אינדקסי חיפוש הם אתגר לשכפול מלא במודל למידת מכונה מסוג זה. לדוגמה, כאשר מקור שפעם היה מהימן הוכשר ישירות להבנת העולם של המודל, הסרת השפעתו (לדוגמה, לאחר הכפשתו) עשויה להיות קשה יותר מסתם הסרת כתובת URL מ-SERPs, שכן מושגי נתונים יכולים להפוך מופשט ומיוצג באופן נרחב במהלך הטמעה באימונים.
בנוסף, מודל כזה יצטרך לעבור הכשרה מתמשכת על מנת לספק את אותה רמת היענות למאמרים ולפרסומים חדשים כפי שמסופקת כעת על ידי העכביש המתמיד של גוגל במקורות. למעשה משמעות הדבר היא השקה מתמשכת ואוטומטית, בניגוד למשטר הנוכחי, שבו מתבצעים שינויים קלים במשקלים ובהגדרות של אלגוריתם החיפוש החופשי, אך האלגוריתם עצמו מתעדכן בדרך כלל רק לעתים רחוקות.
משטחי תקיפה עבור אורקל מומחה מרכזי
מודל ריכוזי שמטמיע ומכליל נתונים חדשים ללא הרף יכול לשנות את משטח ההתקפה עבור פניות חיפוש.
נכון לעכשיו, תוקף יכול להשיג תועלת על ידי השגת דירוג גבוה עבור דומיינים או דפים המכילים מידע שגוי או קוד זדוני. בחסות אורקל 'מומחה' אטום יותר, ההזדמנות להפנות משתמשים לדומיינים תוקפים פוחתת מאוד, אך האפשרות להחדיר מתקפות נתונים רעילות גדלה מאוד.
הסיבה לכך היא שהמערכת המוצעת אינה מבטלת את אלגוריתם דירוג החיפוש, אלא מסתירה אותו מהמשתמש, למעשה אוטומאת את העדיפות של התוצאות המובילות, ואופה אותה (או אותן) לכדי אמירה דידקטית. משתמשים זדוניים כבר מזמן הצליחו לתזמן התקפות נגד אלגוריתם החיפוש של גוגל, כדי למכור מוצרים מזויפים, משתמשים ישירים לדומיינים המפיצים תוכנות זדוניות, או למטרות של מניפולציה פוליטית, בין מקרי שימוש רבים אחרים.
לא AGI
החוקרים מדגישים כי לא סביר שמערכת כזו תעמוד בדרישות של בינה כללית מלאכותית (AGI), ותציב את הסיכוי למגיב מומחה אוניברסלי בהקשר של עיבוד שפה טבעית, בכפוף לכל האתגרים שעמם מתמודדים מודלים כאלה כיום.
המאמר מתאר חמש דרישות לתגובה 'איכות גבוהה':
1: סמכות
כמו באלגוריתמי דירוג נוכחיים, נראה ש'סמכות' נגזרת מציטוט מתחומים באיכות גבוהה הנחשבים סמכותיים בפני עצמם. החוקרים מבחינים:
"התגובות צריכות ליצור תוכן על ידי משיכה ממקורות סמכותיים מאוד. זו סיבה נוספת לכך שיצירת קשרים מפורשים יותר בין רצפי מונחים ומטא נתונים של מסמכים היא כה חיונית. אם כל המסמכים בקורפוס מסומנים בציון סמכותי, יש לקחת את הציון הזה בחשבון בעת אימון המודל, יצירת תגובות או שניהם.'
אף על פי שהחוקרים אינם מציעים שתוצאות ה-SERP המסורתיות יהיו בלתי זמינות אם אורקל מומחה מסוג זה יימצא ביצועי ופופולרי, המאמר כולו מציג את מערכת הדירוג המסורתית, ורשימות תוצאות החיפוש, לאור עשורים של שנים. מערכת אחזור מידע ישנה ומיושנת.
"עצם העובדה שהדירוג הוא מרכיב קריטי בפרדיגמה הזו היא סימפטום של מערכת השליפה המספקת למשתמשים מבחר של תשובות פוטנציאליות, מה שגורם לנטל קוגניטיבי משמעותי למדי על המשתמש. הרצון להחזיר תשובות במקום רשימות מדורגות של תוצאות היה אחד הגורמים המניעים לפיתוח מערכות תשובות לשאלות. '
2: שקיפות
החוקרים מגיבים:
"ככל שניתן, יש להעמיד לרשותו את מקור המידע המוצג למשתמש. האם זהו מקור המידע העיקרי? אם לא, מהו המקור העיקרי?'
3: טיפול בהטיה
המאמר מציין כי מודלים של שפה שהוכשרו מראש נועדו לא להעריך אמת אמפירית, אלא להכליל ולתעדף מגמות דומיננטיות בנתונים. היא מודה שהנחיה זו פותחת את המודל לתקיפה (כפי שקרה עם זה של מיקרוסופט צ'אט בוט גזעני שלא במתכוון בשנת 2016), וכי יהיה צורך במערכות נלוות כדי להגן מפני תגובות מערכת מוטות כאלה.
4: הפעלת נקודות מבט מגוונות
המאמר גם מציע מנגנונים להבטיח ריבוי נקודות מבט:
"תגובות שנוצרות צריכות לייצג מגוון של נקודות מבט מגוונות, אך לא צריכות להיות מקטבות. לדוגמה, עבור שאילתות על נושאים שנויים במחלוקת, יש לכסות את שני הצדדים של הנושא בצורה הוגנת ומאוזנת. ברור שיש לזה קשר הדוק עם הטיית מודל'.
5: שפה נגישה
מלבד מתן תרגומים מדויקים במקרים שבהם התגובה המוסמכת היא בשפה אחרת, המאמר מציע שתגובות מובלעות צריכות להיכתב במונחים פשוטים ככל האפשר.















