Intelligenza artificiale
DALL-E 2 è solo ‘incollare cose insieme’ senza capire le loro relazioni?

Un nuovo studio di ricerca dell’Università di Harvard suggerisce che il framework di generazione di immagini testuali DALL-E 2 di OpenAI, che ha fatto notizia, abbia difficoltà notevoli nel riprodurre anche le relazioni a livello di infante tra gli elementi che compone in foto sintetizzate, nonostante la sofisticatezza sgargiante di gran parte della sua produzione.
I ricercatori hanno condotto uno studio sugli utenti che ha coinvolto 169 partecipanti crowdsourced, che sono stati presentati con immagini DALL-E 2 basate sui principi umani più basilari di semantica delle relazioni, insieme ai prompt di testo che li avevano creati. Quando è stato chiesto se i prompt e le immagini erano correlati, meno del 22% delle immagini sono state percepite come pertinenti ai loro prompt associati, in termini di relazioni molto semplici che DALL-E 2 era stato chiesto di visualizzare.

Uno screen-grab dalle prove condotte per il nuovo studio. I partecipanti sono stati incaricati di selezionare tutte le immagini che corrispondevano al prompt. Fonte: https://arxiv.org/pdf/2208.00005.pdf
I risultati suggeriscono anche che l’apparente capacità di DALL-E di congiungere elementi disparati possa diminuire man mano che questi elementi diventano meno probabili di essere stati presenti nei dati di training reali che alimentano il sistema.
Ad esempio, le immagini per il prompt ‘bambino che tocca una ciotola’ hanno ottenuto un tasso di accordo dell’87% (cioè i partecipanti hanno cliccato sulla maggior parte delle immagini come rilevanti per il prompt), mentre renderings fotorealistici simili di ‘una scimmia che tocca un iguana’ hanno raggiunto solo l’11% di accordo:


DALL-E fatica a rappresentare l’evento improbabile di una ‘scimmia che tocca un iguana’, probabilmente perché è poco comune, più probabilmente inesistente, nel set di training.
Nel secondo esempio, DALL-E 2 spesso ottiene la scala e addirittura la specie sbagliata, presumibilmente a causa della scarsità di immagini del mondo reale che rappresentano questo evento. Al contrario, è ragionevole aspettarsi un alto numero di foto di training relative a bambini e cibo, e che questo sub-dominio/classe sia ben sviluppato.
La difficoltà di DALL-E nel giustapporre elementi di immagine fortemente contrastanti suggerisce che il pubblico è attualmente così abbagliato dalle capacità fotorealistici e ampiamente interpretative del sistema da non aver sviluppato un occhio critico per i casi in cui il sistema ha effettivamente solo ‘incollato’ un elemento in modo netto su un altro, come in questi esempi dal sito ufficiale di DALL-E 2:

Sintesi di cut-and-paste, dagli esempi ufficiali per DALL-E 2. Fonte: https://openai.com/dall-e-2/
Il nuovo studio afferma*:
‘La comprensione relazionale è un componente fondamentale dell’intelligenza umana, che si manifesta precoce nello sviluppo, e viene calcolata rapidamente e automaticamente nella percezione.
‘La difficoltà di DALL-E 2 con relazioni spaziali di base (come in, on, under) suggerisce che qualunque cosa abbia imparato, non ha ancora imparato i tipi di rappresentazioni che consentono agli esseri umani di strutturare il mondo in modo così flessibile e robusto.
‘Un’interpretazione diretta di questa difficoltà è che sistemi come DALL-E 2 non hanno ancora la composizionalità relazionale.’
Gli autori suggeriscono che i sistemi di generazione di immagini guidati dal testo come la serie DALL-E potrebbero trarre vantaggio dall’utilizzo di algoritmi comuni alla robotica, che modellano identità e relazioni simultaneamente, a causa della necessità per l’agente di interagire effettivamente con l’ambiente piuttosto che semplicemente fabbricare una miscela di elementi diversi.
Un tale approccio, intitolato CLIPort, utilizza lo stesso meccanismo CLIP che serve come elemento di valutazione della qualità in DALL-E 2:
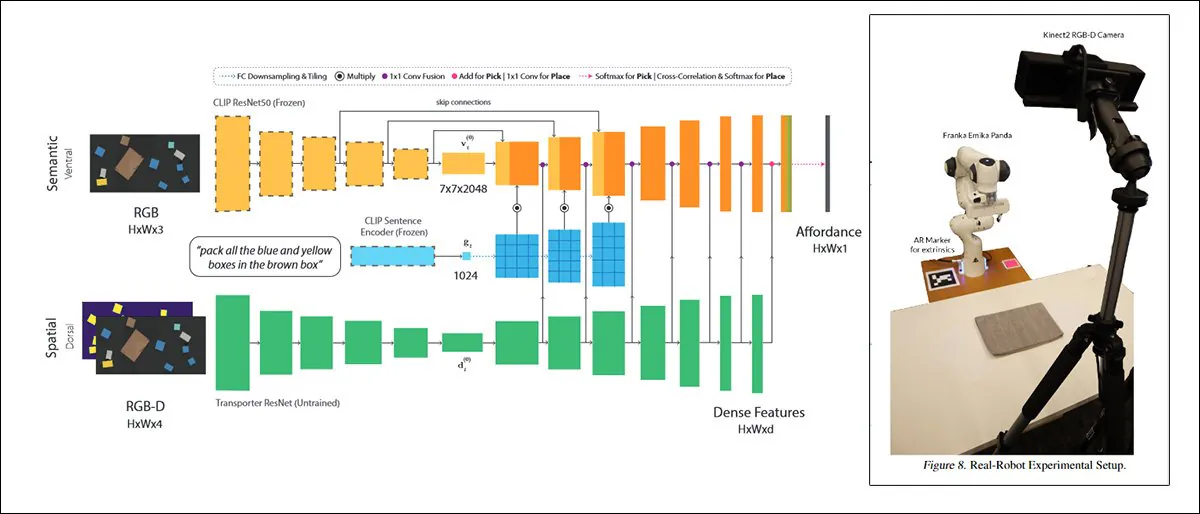
CLIPort, una collaborazione del 2021 tra l’Università di Washington e NVIDIA, utilizza CLIP in un contesto così pratico che i sistemi addestrati su di esso devono necessariamente sviluppare una comprensione delle relazioni fisiche, un motivatore che è assente in DALL-E 2 e in framework di sintesi di immagini ‘fantastici’ simili. Fonte: https://arxiv.org/pdf/2109.12098.pdf
Gli autori suggeriscono inoltre che ‘un’altra plausibile aggiornamento’ potrebbe essere per l’architettura dei sistemi di sintesi di immagini come DALL-E di incorporare effetti moltiplicativi in un solo livello di calcolo, consentendo il calcolo delle relazioni in un modo ispirato alle capacità di elaborazione delle informazioni dei sistemi biologici biologici.
Il nuovo studio si intitola Test della comprensione relazionale nella generazione di immagini guidata dal testo, e proviene da Colin Conwell e Tomer D. Ullman del Dipartimento di Psicologia di Harvard.
Oltre la critica iniziale
Commentando il ‘trucco’ dietro la realtà e l’integrità della produzione di DALL-E 2, gli autori notano lavori precedenti che hanno trovato carenze nei sistemi di generazione di immagini generativi di stile DALL-E.
A giugno di quest’anno, l’Università della California, Berkeley ha notato la difficoltà di DALL-E nel gestire riflessi e ombre; lo stesso mese, uno studio della Corea ha indagato l”unicità’ e l’originalità della produzione di stile DALL-E 2 con un occhio critico; un analisi preliminare delle immagini DALL-E 2, poco dopo il lancio, dell’Università di New York e dell’Università del Texas, ha trovato vari problemi con la composizionalità e altri fattori essenziali nelle immagini DALL-E 2; e il mese scorso, un lavoro congiunto tra l’Università dell’Illinois e il MIT ha offerto suggerimenti per miglioramenti architettonici per tali sistemi in termini di composizionalità.
I ricercatori notano inoltre che i luminari di DALL-E come Aditya Ramesh hanno concesso i problemi del framework con la legatura, la dimensione relativa, il testo e altre sfide.
Gli sviluppatori dietro il sistema di sintesi di immagini rivale di Google, Imagen, hanno anche proposto DrawBench, un sistema di confronto innovativo che valuta l’accuratezza delle immagini attraverso framework con metriche diverse.
Invece, gli autori del nuovo studio suggeriscono che un risultato migliore potrebbe essere ottenuto mettendo la stima umana – piuttosto che metriche algoritmiche interne – contro le immagini risultanti, per stabilire dove si trovano le debolezze e cosa potrebbe essere fatto per mitigarle.
Lo studio
A questo scopo, il nuovo progetto si basa su principi psicologici e cerca di ritirarsi dall’attuale ondata di interesse nella progettazione del prompt (che è, in effetti, una concessione alle carenze di DALL-E 2, o qualsiasi sistema comparabile), per indagare e potenzialmente affrontare le limitazioni che rendono tali ‘soluzioni’ necessarie.












