Intelligenza artificiale
Creazione di una rete generativa avversaria personalizzata con schizzi

I ricercatori di Carnegie Mellon e MIT hanno sviluppato una nuova metodologia che consente all’utente di creare sistemi di creazione di immagini personalizzati di rete generativa avversaria (GAN) semplicemente disegnando schizzi indicativi.
Un sistema di questo tipo potrebbe consentire all’utente finale di creare sistemi di generazione di immagini in grado di generare immagini molto specifiche, come ad esempio animali particolari, tipi di edifici e persino persone individuali. Attualmente, la maggior parte dei sistemi di generazione GAN produce output ampio e abbastanza casuale, con una limitata capacità di specificare caratteristiche particolari, come la razza di un animale, i tipi di capelli delle persone, gli stili di architettura o le identità facciali effettive.
L’approccio, descritto nel documento Schizza la tua GAN, utilizza una nuova interfaccia di schizzo come una funzione di “ricerca” efficace per trovare funzionalità e classi in database di immagini altrimenti sovraccarichi che possono contenere migliaia di tipi di oggetti, compresi molti sottotipi che non sono rilevanti per l’intento dell’utente. La GAN viene quindi addestrata su questo subset di immagini filtrate.
Disegnando l’oggetto specifico con cui l’utente desidera calibrare la GAN, le capacità generative del framework diventano specializzate per quella classe. Ad esempio, se un utente desidera creare un framework che generi un tipo specifico di gatto (piuttosto che solo un gatto qualsiasi, come può essere ottenuto con This Cat Does Not Exist), gli schizzi di input servono come filtro per escludere classi non rilevanti di gatti.

Source: https://peterwang512.github.io/GANSketching/
La ricerca è guidata da Sheng Yu-Wang di Carnegie Mellon University, insieme al collega Jun-Yan Zhu e David Bau del Laboratorio di informatica e intelligenza artificiale di MIT.
Il metodo stesso è chiamato ‘GAN sketching’ e utilizza gli schizzi di input per modificare direttamente i pesi di un modello GAN ‘template’ per mirare specificamente al dominio o sottodominio identificato attraverso cross-domain adversarial loss.
Sono stati esplorati diversi metodi di regolarizzazione per garantire che l’output del modello sia diversificato, mantenendo al contempo un’alta qualità dell’immagine. I ricercatori hanno creato applicazioni di esempio in grado di interpolare lo spazio latente e condurre procedure di editing di immagini.
Questo [$class] non esiste
I sistemi di generazione di immagini basati su GAN sono diventati una moda, se non un meme, negli ultimi anni, con una proliferazione di progetti in grado di generare immagini di cose non esistenti, tra cui persone, appartamenti in affitto, snack, piedi, cavalli, politici e insetti, tra gli altri.
I sistemi di sintesi di immagini basati su GAN vengono creati compilando o curando estesi dataset contenenti immagini del dominio di destinazione, come ad esempio volti o cavalli; addestrando modelli che generalizzano una gamma di funzionalità attraverso le immagini nel database; e implementando moduli generatori che possono produrre esempi casuali in base alle funzionalità apprese.

Output da schizzi in DeepFacePencil, che consente agli utenti di creare volti fotorealistici da schizzi. Molti progetti simili di sketch-to-image esistono. Source: https://arxiv.org/pdf/2008.13343.pdf
Le funzionalità ad alta dimensionalità sono tra le prime a essere concretizzate durante il processo di addestramento e sono equivalenti ai primi ampi tratti di colore di un pittore su una tela. Queste caratteristiche ad alta dimensionalità si correleranno in seguito a funzionalità più dettagliate (ad esempio, il bagliore dell’occhio e i baffi appuntiti di un gatto, invece di un generico blob beige che rappresenta la testa).
So cosa intendi…
Mappando la relazione tra queste forme seminali precedenti e le interpretazioni dettagliate che si ottengono molto più tardi nel processo di addestramento, è possibile inferire relazioni tra immagini “vaghe” e “specifiche”, consentendo agli utenti di creare immagini complesse e fotorealistiche da schizzi grezzi.
Recentemente, NVIDIA ha rilasciato una versione desktop della sua ricerca a lungo termine GauGAN sulla generazione di paesaggi basata su GAN, che dimostra facilmente questo principio:
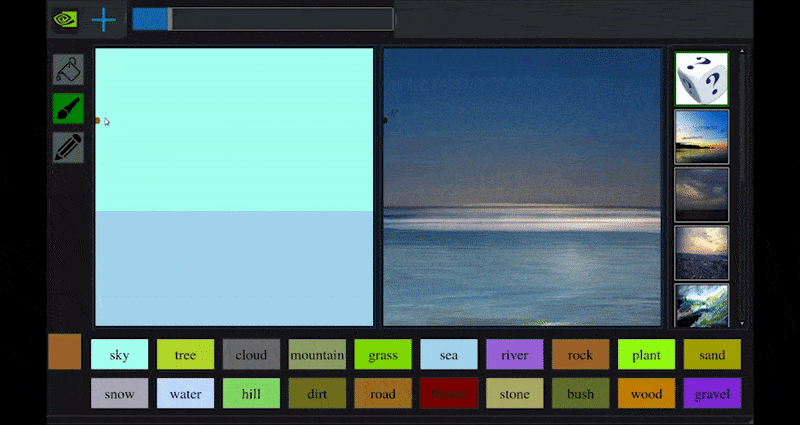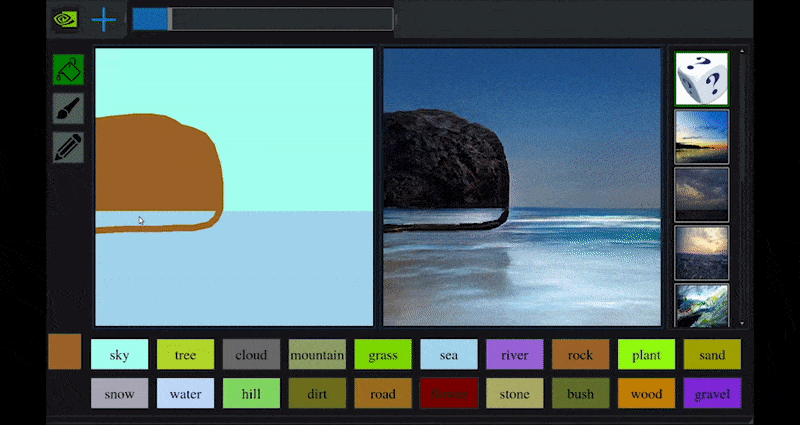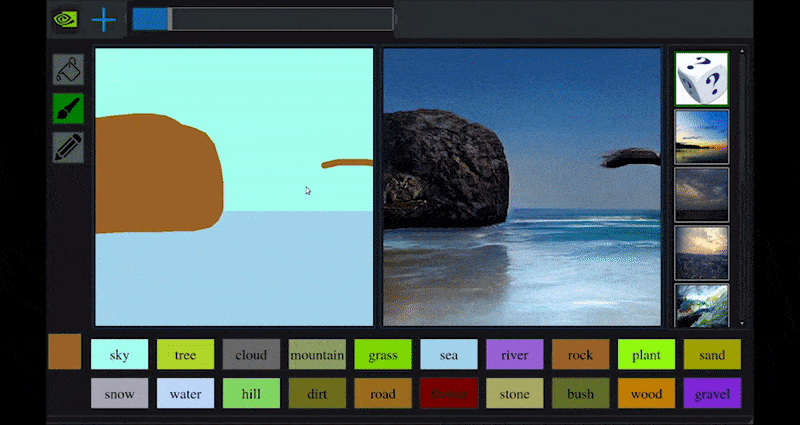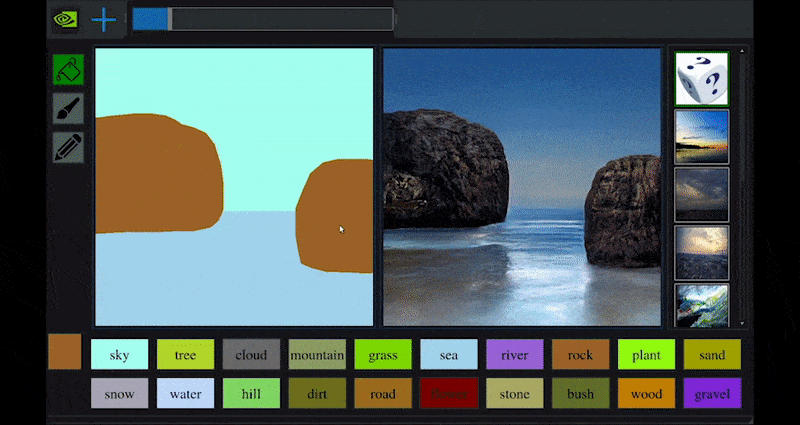
Approximate daubs sono tradotti in ricche immagini panoramiche attraverso NVIDIA’s GauGAN, e ora l’applicazione NVIDIA Canvas. Source: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Allo stesso modo, molti sistemi come DeepFacePencil hanno utilizzato lo stesso principio per creare generatori di immagini fotorealistiche indotti da schizzi per vari domini.

L’architettura di DeepFacePencil.
Semplificazione di sketch-to-image
L’approccio GAN Sketching del nuovo documento cerca di rimuovere il formidabile onere di raccolta e cura dei dati che è normalmente coinvolto nello sviluppo di framework di immagini GAN, utilizzando l’input dell’utente per definire quale subset di immagini costituisca i dati di addestramento.
Il sistema è stato progettato per richiedere solo un piccolo numero di schizzi di input per calibrare il framework. Il sistema effettivamente inverte la funzionalità di PhotoSketch, un’iniziativa di ricerca congiunta del 2019 da parte di ricercatori di Carnegie Mellon, Adobe, Uber ATG e Argo AI, che è incorporata nel nuovo lavoro. PhotoSketch è stato progettato per creare schizzi artistici da immagini e contiene già la mappatura efficace delle relazioni di creazione di immagini vaghe>specifiche.
Per la parte di generazione del processo, il nuovo metodo modifica solo i pesi di StyleGAN2. Poiché i dati di immagine utilizzati sono solo un subset dei dati totali disponibili, la modifica della rete di mappatura ottiene risultati desiderabili.
Il metodo è stato valutato su una serie di sottodomini popolari, tra cui equestre, chiese e gatti.

Il dataset LSUN di Princeton University del 2016 è stato utilizzato come materiale principale da cui derivare sottodomini di destinazione. Per stabilire un sistema di mappatura degli schizzi robusto alle eccentricità dell’input degli utenti del mondo reale, il sistema è stato addestrato su immagini del dataset QuickDraw sviluppato da Microsoft tra il 2021-2016.
Sebbene la mappatura degli schizzi tra PhotoSketch e QuickDraw siano abbastanza diverse, i ricercatori hanno trovato che il loro framework riesce bene a superare entrambi abbastanza facilmente su pose relativamente semplici, sebbene pose più complesse (come gatti sdraiati) si rivelino più impegnative, mentre l’input degli utenti molto astratto (ad esempio disegni troppo grezzi) ostacola anche la qualità dei risultati.

Spazio latente e editing di immagini naturali
I ricercatori hanno sviluppato due applicazioni basate sul lavoro principale: editing dello spazio latente e editing di immagini. L’editing dello spazio latente offre controlli utente interpretabili che sono facilitati al momento dell’addestramento e consentono un ampio grado di variazione, rimanendo fedeli al dominio di destinazione e piacevolmente coerenti attraverso le variazioni.

Interpolazione dello spazio latente liscia con i modelli personalizzati di GAN Sketching.
La componente di editing dello spazio latente è stata alimentata dal progetto GANSpace del 2020, un’iniziativa congiunta dell’Università di Aalto, Adobe e NVIDIA.
Un’immagine singola può anche essere alimentata nel modello personalizzato, facilitando l’editing di immagini naturali. In questa applicazione, un’immagine singola viene proiettata sul GAN personalizzato, abilitando non solo l’editing diretto, ma anche la conservazione dell’editing dello spazio latente di livello superiore, se questo è stato utilizzato.

Qui, un’immagine reale è stata utilizzata come input per il GAN (modello di gatto), che edita l’input per corrispondere agli schizzi inviati. Ciò consente l’editing di immagini tramite schizzi.
Sebbene configurabile, il sistema non è progettato per funzionare in tempo reale, almeno in termini di addestramento e calibrazione. Attualmente, GAN Sketching richiede 30.000 iterazioni di addestramento. Il sistema richiede anche l’accesso ai dati di addestramento originali per il modello originale.
In casi in cui il dataset è open source e ha una licenza che consente la copia locale, ciò potrebbe essere gestito includendo i dati di origine in un pacchetto installato localmente, sebbene ciò richiederebbe una notevole quantità di spazio su disco; o accedendo o elaborando i dati in modalità remota, tramite un approccio basato su cloud, che introduce overhead di rete e (nel caso in cui l’elaborazione effettiva si verifichi sul cloud) possibili considerazioni di costo di calcolo.

Trasformazioni da modelli FFHQ personalizzati addestrati su solo 4 schizzi generati dall’uomo.












