Kecerdasan buatan
Ruter Model dan Perangkap Umpan Balik: Bagaimana AI Belajar dari Diri Sendiri
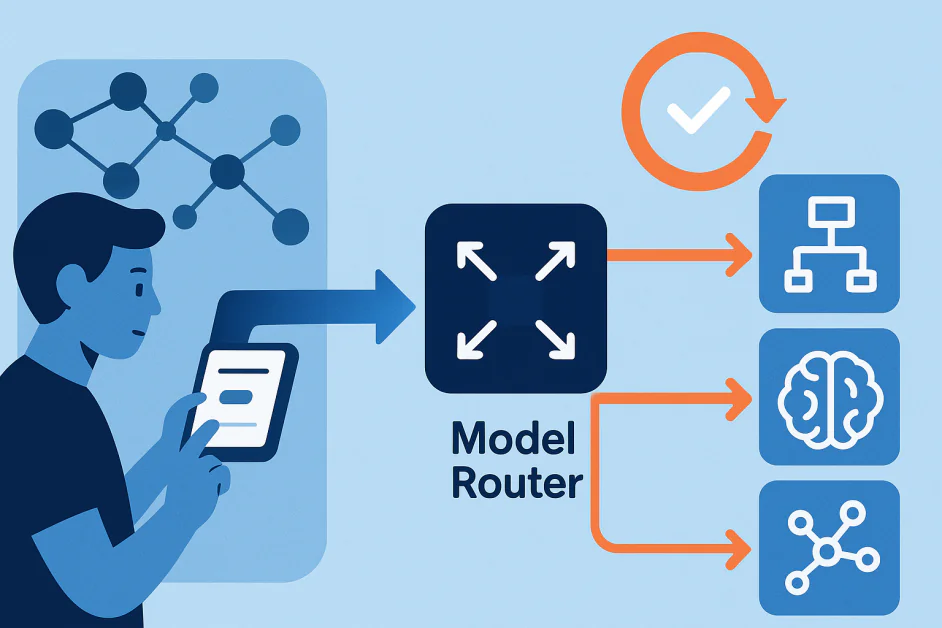
Sistem AI modern tidak lagi dibangun di sekitar satu model yang menangani setiap tugas. Sebaliknya, mereka bergantung pada koleksi model, masing-masing dirancang untuk tujuan tertentu. Di pusat pengaturan ini adalah ruter model, komponen yang menafsirkan permintaan pengguna dan memutuskan model mana yang harus menanganinya. Misalnya, dalam sistem seperti OpenAI’s GPT-5, ruter mungkin mengirimkan query sederhana ke model ringan untuk kecepatan sementara mengarahkan tugas penalaran kompleks ke model yang lebih maju.
Ruter tidak hanya mengelola lalu lintas. Mereka belajar dari perilaku pengguna, seperti ketika orang beralih antar model atau lebih memilih jawaban tertentu. Ini menciptakan siklus: ruter mengirimkan query, model menghasilkan jawaban, reaksi pengguna memberikan umpan balik, dan ruter memperbarui keputusannya. Ketika siklus-siklus ini beroperasi secara diam-diam di latar belakang, mereka dapat membentuk umpan balik tersembunyi. Umpan balik semacam itu dapat memperkuat bias, memperkuat pola yang rusak, atau secara bertahap mengurangi kinerja dengan cara yang sulit dideteksi.
Artikel ini melihat bagaimana ruter model bekerja, bagaimana umpan balik terbentuk, dan apa risiko yang mereka hadapi ketika sistem AI terus berkembang.
Mengenal Ruter Model dalam AI
Ruter model adalah lapisan pengambil keputusan dalam sistem AI multi-model. Perannya adalah menentukan model mana yang paling sesuai untuk sebuah tugas. Pilihan ini bergantung pada faktor-faktor seperti kompleksitas query, niat pengguna, konteks, dan pertimbangan antara biaya, akurasi, dan kecepatan.
Tidak seperti sistem yang mengikuti aturan tetap, sebagian besar ruter model adalah sistem pembelajaran mesin itu sendiri. Mereka dilatih pada sinyal dunia nyata dan beradaptasi seiring waktu. Mereka mungkin belajar dari perilaku pengguna seperti beralih antar model, menilai jawaban, atau mengubah kalimat pertanyaan, serta dari evaluasi otomatis yang mengukur kualitas output.
Kemampuan adaptasi ini membuat ruter kuat tetapi juga berisiko. Mereka meningkatkan efisiensi dan menyediakan pengalaman pengguna yang lebih baik, tetapi proses umpan balik yang sama yang memperbarui keputusan mereka juga dapat menciptakan lingkaran pengukuhan. Seiring waktu, lingkaran-lingkaran ini dapat memengaruhi tidak hanya strategi pengaturan tetapi juga bagaimana sistem AI yang lebih besar berperilaku.
Bagaimana Umpan Balik Terbentuk
Umpan balik terjadi ketika output sistem memengaruhi data yang kemudian dipelajari. Contoh sederhana adalah sistem rekomendasi: jika Anda mengklik video olahraga, sistem menampilkan lebih banyak konten olahraga, yang membentuk apa yang Anda tonton selanjutnya. Seiring waktu, sistem memperkuat pola-pola sendiri. Contoh lain untuk memahami umpan balik adalah polisi prediktif. Algoritma mungkin memprediksi kejahatan yang lebih tinggi di lingkungan tertentu, yang dapat menyebabkan patroli lebih banyak. Patroli yang meningkat mengungkap lebih banyak insiden, yang kemudian mengonfirmasi prediksi algoritma. Sistem tampak akurat, tetapi data tersebut cenderung dipengaruhi oleh pengaruhnya sendiri. Umpan balik dapat langsung atau tersembunyi. Umpan balik langsung mudah dikenali, seperti sistem rekomendasi yang melatih kembali pada saran sendiri. Umpan balik tersembunyi lebih halus karena mereka muncul ketika bagian-bagian sistem yang berbeda secara tidak langsung memengaruhi satu sama lain.
Ruter model dapat menciptakan lingkaran yang serupa. Keputusan ruter membentuk model mana yang menghasilkan jawaban. Jawaban itu membentuk perilaku pengguna, yang menjadi umpan balik untuk ruter. Seiring waktu, ruter mungkin mulai memperkuat pola yang berhasil di masa lalu daripada secara konsisten memilih model terbaik. Lingkaran-lingkaran ini sulit dideteksi dan dapat secara diam-diam mendorong sistem AI ke arah yang tidak diinginkan.
Mengapa Umpan Balik dalam Ruter Berisiko
Sementara umpan balik membantu ruter meningkatkan kecocokan tugas, mereka juga membawa risiko yang dapat mengubah perilaku sistem. Salah satu risiko adalah memperkuat bias awal. Jika ruter secara terus-menerus mengirimkan jenis query tertentu ke Model A, sebagian besar umpan balik akan berasal dari output Model A. Ruter mungkin kemudian menganggap Model A selalu yang terbaik, mengesampingkan Model B, bahkan jika Model B kadang-kadang dapat berkinerja lebih baik. Penggunaan yang tidak merata ini dapat menjadi self-reinforcing. Model yang berkinerja baik pada tugas yang diarahkan menarik lebih banyak permintaan, yang memperkuat kekuatan mereka. Model yang kurang digunakan menerima lebih sedikit kesempatan untuk diperbarui, menciptakan ketidakseimbangan dan mengurangi keragaman.
Bias juga dapat berasal dari model evaluasi yang digunakan untuk menilai kebenaran. Jika model “hakim” memiliki titik buta, bias tersebut langsung diteruskan ke ruter, yang kemudian mengoptimalkan untuk nilai hakim daripada kebutuhan pengguna yang sebenarnya. Perilaku pengguna menambahkan tingkat kompleksitas lain. Jika ruter cenderung mengembalikan gaya jawaban tertentu, pengguna mungkin beradaptasi dengan mengubah query mereka untuk memenuhi pola tersebut, memperkuatnya lebih lanjut. Seiring waktu, ini dapat mempersempit baik perilaku pengguna maupun respons sistem. Ruter juga dapat belajar untuk mengasosiasikan pola query tertentu atau demografi dengan model tertentu. Ini dapat menyebabkan pengalaman yang sistematis berbeda di seluruh kelompok, potensial memperkuat dan memperkuat bias sosial yang ada.
Kekhawatiran utama lainnya adalah drift jangka panjang. Keputusan yang dibuat ruter hari ini memengaruhi data pelatihan yang digunakan besok. Jika model diperbarui dengan output yang dipengaruhi oleh pengaturan, mereka mungkin belajar preferensi ruter daripada pendekatan independen. Ini dapat membuat respons di seluruh model lebih seragam dan mengintegrasikan bias yang bertahan seiring waktu.
Strategi untuk Menghentikan Siklus
Mengurangi risiko lingkaran tersembunyi memerlukan desain dan pengawasan aktif. Pelatihan harus menggunakan sumber data yang beragam, bukan hanya klik pengguna atau peralihan. Pengaturan acak sesekali juga dapat mencegah satu model monopoli jenis tugas tertentu. Pemantauan sangat penting. Audit reguler dapat mengungkap apakah ruter bergeser ke pola tertentu atau terlalu mengandalkan satu model. Transparansi dalam keputusan ruter membantu peneliti mendeteksi bias lebih awal.
Ruter juga harus diperbarui secara berkala dengan data segar dan seimbang sehingga bias lama tidak terkunci. Mengintegrasikan pengawasan manusia, terutama di domain sensitif, menambahkan lapisan akuntabilitas lain. Manusia dapat mengidentifikasi ketika ruter secara sistematis memfavoritkan satu model atau mengklasifikasikan query tertentu secara salah.
Kunci utamanya adalah memperlakukan ruter sebagai model yang tunduk pada umpan balik, bukan sebagai komponen tetap atau netral. Dengan mengakui bagaimana ruter sendiri dibentuk oleh data yang mereka buat, peneliti dan pengembang dapat merancang sistem yang tetap adil, adaptif, dan dapat diandalkan seiring waktu.
Intinya
Ruter model menawarkan keuntungan yang jelas dalam efisiensi dan adaptabilitas, tetapi mereka juga membawa risiko tersembunyi. Umpan balik dalam sistem ini dapat secara diam-diam memperkuat bias, membatasi keragaman respons, dan mengunci model ke pola perilaku yang sempit. Ketika arsitektur ini menjadi lebih umum, mengenali dan mengatasi risiko ini lebih awal akan menjadi kunci untuk membangun sistem AI yang tetap adil, dapat diandalkan, dan benar-benar adaptif.












