Kecerdasan buatan
Adobe Research Memperluas Disentangled GAN Face Editing

Tidak sulit untuk memahami mengapa entanglement adalah masalah dalam sintesis gambar, karena seringkali menjadi masalah di bidang lain kehidupan; misalnya, jauh lebih sulit untuk menghilangkan kunyit dari kari daripada membuang acar dalam burger, dan hampir mustahil untuk mengurangi manisnya secangkir kopi. Beberapa hal hanya datang dalam paket.
Demikian pula, entanglement adalah hambatan bagi arsitektur sintesis gambar yang idealnya ingin memisahkan fitur dan konsep yang berbeda saat menggunakan pembelajaran mesin untuk membuat atau mengedit wajah (atau anjing, perahu, atau domain lain).
Jika Anda bisa memisahkan benang seperti usia, jenis kelamin, warna rambut, warna kulit, emosi, dan sebagainya, Anda akan memiliki awal dari instrumentalitas dan fleksibilitas yang sebenarnya dalam kerangka kerja yang bisa membuat dan mengedit gambar wajah pada tingkat yang sangat granular, tanpa menarik ‘penumpang’ yang tidak diinginkan ke dalam konversi ini.

Pada entanglement maksimum (atas kiri), semua yang bisa Anda lakukan adalah mengubah gambar dari jaringan GAN yang dipelajari ke gambar orang lain.
Ini secara efektif menggunakan teknologi visi komputer AI terbaru untuk mencapai sesuatu yang telah diselesaikan dengan cara lain lebih dari tiga puluh tahun yang lalu.
Dengan beberapa derajat pemisahan (‘Pemisahan Sedang’ di atas gambar sebelumnya), memungkinkan untuk melakukan perubahan berbasis gaya seperti warna rambut, ekspresi, aplikasi kosmetik, dan rotasi kepala terbatas, di antara lainnya.

Sumber: FEAT: Face Editing with Attention, Februari 2022, https://arxiv.org/pdf/2202.02713.pdf
Telah ada beberapa upaya dalam dua tahun terakhir untuk membuat lingkungan pengeditan wajah interaktif yang memungkinkan pengguna untuk mengubah karakteristik wajah dengan slider dan interaksi UI tradisional lainnya, sambil menjaga fitur inti wajah target tetap utuh saat membuat penambahan atau perubahan. Namun, ini telah terbukti menjadi tantangan karena entanglement fitur/gaya yang mendasarinya dalam ruang laten GAN.
Misalnya, ciri kacamata sering kali terjalin dengan ciri usia tua, yang berarti menambahkan kacamata mungkin juga ‘mengubah’ wajah, sementara mengubah wajah mungkin menambahkan kacamata, tergantung pada derajat pemisahan fitur tingkat tinggi yang diterapkan (lihat ‘Pengujian’ di bawah untuk contoh).
Yang paling mencolok, hampir mustahil untuk mengubah warna rambut dan aspek rambut lainnya tanpa menghitung ulang benang rambut dan disposisi, yang memberikan efek ‘menggelegak’, transisi.

Sumber: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-to-Latent GAN Traversal
Sebuah makalah baru yang dipimpin oleh Adobe dimasukkan untuk WACV 2022 menawarkan pendekatan baru untuk masalah-masalah yang mendasarinya dalam makalah berjudul Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images.

Bahan tambahan dari makalah Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images. Di sini kita lihat bahwa karakteristik dasar dalam wajah yang dipelajari tidak ditarik ke dalam perubahan yang tidak terkait. Lihat video embed di akhir artikel untuk detail dan resolusi yang lebih baik. Sumber: https://www.youtube.com/watch?v=rf_61llRH0Q
Makalah ini dipimpin oleh Ilmuwan Terapan Adobe Siavash Khodadadeh, bersama dengan empat peneliti Adobe lainnya, dan seorang peneliti dari Departemen Ilmu Komputer Universitas Central Florida.
Makalah ini menarik sebagian karena Adobe telah beroperasi di ruang ini selama beberapa waktu, dan menggoda untuk membayangkan fungsionalitas ini memasuki proyek Creative Suite dalam beberapa tahun ke depan; tetapi terutama karena arsitektur yang dibuat untuk proyek ini mengambil pendekatan yang berbeda untuk mempertahankan integritas visual dalam editor wajah GAN saat perubahan diterapkan.
Penulis menyatakan:
‘[Kami] melatih jaringan saraf untuk melakukan transformasi laten-ke-laten yang menemukan pengkodean laten yang sesuai dengan gambar dengan atribut yang diubah. Karena teknik ini adalah one-shot, tidak bergantung pada trajektori linier atau non-linier dari perubahan atribut yang bertahap.’
‘Dengan melatih jaringan dari ujung ke ujung melalui pipa generasi penuh, sistem dapat beradaptasi dengan ruang laten arsitektur generator yang ada. Sifat konservasi, seperti mempertahankan identitas orang, dapat dikodekan dalam bentuk kerugian pelatihan. ‘
‘Setelah jaringan laten-ke-laten dilatih, dapat digunakan kembali untuk gambar arbitrer tanpa pelatihan ulang.’
Hal ini berarti bahwa arsitektur yang diusulkan tiba dengan pengguna dalam keadaan selesai. Masih perlu menjalankan jaringan saraf pada sumber daya lokal, tetapi gambar baru dapat ‘dijatuhkan’ dan siap untuk diubah hampir seketika, karena kerangka kerja cukup terpisah untuk tidak memerlukan pelatihan gambar khusus lebih lanjut.
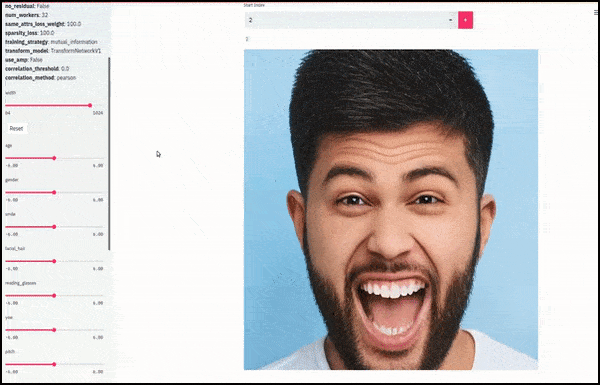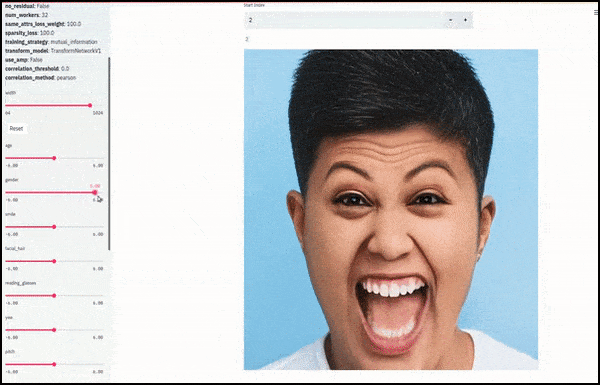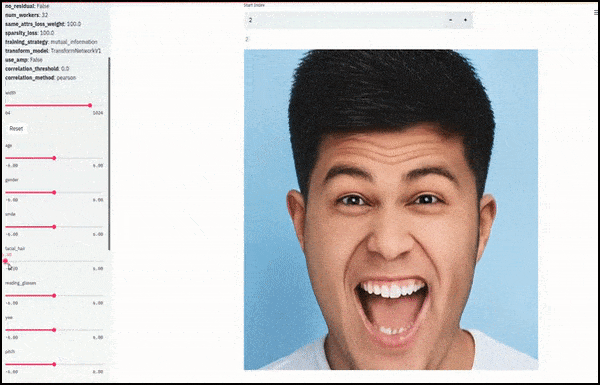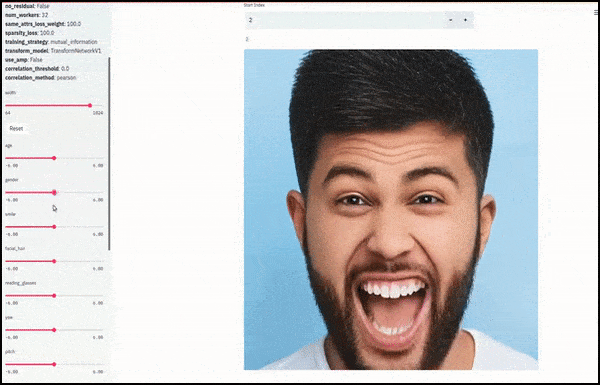
Jenis kelamin dan rambut wajah berubah saat slider memplot jalur acak dan sewenang-wenang melalui ruang laten, tidak hanya ‘menggosok antara titik akhir’. Lihat video di akhir artikel untuk lebih banyak transformasi dengan resolusi yang lebih baik.
Di antara pencapaian utama dalam karya ini adalah kemampuan jaringan untuk ‘membekukan’ identitas dalam ruang laten dengan mengubah hanya atribut dalam vektor target, dan memberikan ‘istilah koreksi’ yang melestarikan identitas yang diubah.
Pada dasarnya, jaringan yang diusulkan tersemat dalam arsitektur yang lebih luas yang mengatur semua elemen yang diproses, yang melewati komponen prainisialisasi dengan bobot yang membeku yang tidak akan menghasilkan efek sampingan yang tidak diinginkan pada transformasi.
Karena proses pelatihan bergantung pada triplet yang dapat dihasilkan baik oleh gambar biji (di bawah GAN inversion) atau pengkodean laten awal yang ada, proses pelatihan keseluruhan tidak terawasi, dengan tindakan implisit dari rentang label dan sistem kurasi yang biasa dalam sistem tersebut secara efektif dipanggang ke dalam arsitektur. Bahkan, sistem baru menggunakan regresi atribut off-the-shelf:
‘[Jumlah] atribut yang jaringan kami dapat kendalikan secara independen hanya terbatas pada kemampuan pengenal(s) – jika satu memiliki pengenal untuk atribut, kami dapat menambahkannya ke wajah sewenang-wenang. Dalam eksperimen kami, kami melatih jaringan laten-ke-laten untuk memungkinkan penyesuaian 35 atribut wajah yang berbeda, lebih dari pendekatan sebelumnya.’
Sistem ini mencakup pengaman tambahan terhadap transformasi ‘efek samping’ yang tidak diinginkan: dalam ketiadaan permintaan untuk perubahan atribut, jaringan laten-ke-laten akan memetakan vektor laten ke dirinya sendiri, lebih lanjut meningkatkan persistensi stabil dari identitas target.
Pengenalan Wajah
Satu masalah berulang dengan editor wajah GAN dan berbasis encoder/decoder tahun-tahun terakhir telah menjadi bahwa transformasi yang diterapkan cenderung merusak kemiripan. Untuk melawan ini, proyek Adobe menggunakan jaringan pengenalan wajah yang tersemat yang disebut FaceNet sebagai diskriminator.

Arsitektur proyek, lihat kiri tengah bawah untuk inklusi FaceNet. Sumber: Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images, OpenAccess.
(Dalam catatan pribadi, ini tampaknya menjadi langkah maju menuju integrasi sistem pengenalan wajah standar dan bahkan pengenalan ekspresi ke dalam jaringan generatif, yang paling mungkin merupakan cara terbaik untuk mengatasi pemetaan piksel-buta-ke-piksel yang mendominasi arsitektur deepfake saat ini dengan biaya kesetiaan ekspresi dan domain lainnya dalam sektor generasi wajah.)
Akses Semua Area di Ruang Laten
Fitur lain yang mengesankan dari kerangka kerja ini adalah kemampuannya untuk melakukan perjalanan sewenang-wenang antara transformasi potensial di ruang laten, sesuai keinginan pengguna. Beberapa sistem sebelumnya yang menyediakan antarmuka eksplorasi sering meninggalkan pengguna secara efektif ‘menggosok’ antara garis waktu transformasi fitur tetap – mengesankan, tetapi sering kali pengalaman yang cukup linier atau preskriptif.

Dari Improving GAN Equilibrium by Raising Spatial Awareness: di sini pengguna menggosok melalui serangkaian titik transisi potensial antara dua lokasi ruang laten, tetapi dalam batas lokasi ruang laten yang telah dipelajari sebelumnya. Untuk menerapkan jenis transformasi lain berdasarkan materi yang sama, konfigurasi ulang dan/atau pelatihan ulang diperlukan. Sumber: https://genforce.github.io/eqgan/
Selain dapat menerima gambar pengguna baru, pengguna juga dapat secara manual ‘membekukan’ elemen yang ingin dilestarikan selama proses transformasi. Dengan cara ini pengguna dapat memastikan bahwa (misalnya) latar belakang tidak bergeser, atau bahwa mata tetap terbuka atau tertutup.
Data
Jaringan regresi atribut dilatih pada tiga jaringan: FFHQ, CelebAMask-HQ, dan jaringan lokal yang dihasilkan GAN yang diperoleh dengan mengambil sampel 400.000 vektor dari ruang Z StyleGAN-V2.
Gambar di luar distribusi (OOD) disaring, dan atribut diekstrak menggunakan Face API Microsoft, dengan hasil set gambar yang dihasilkan dibagi 90/10, meninggalkan 721.218 gambar pelatihan dan 72.172 gambar uji untuk dibandingkan.
Pengujian
Meskipun jaringan eksperimental awalnya dikonfigurasikan untuk mengakomodasi 35 transformasi potensial, ini dikurangi menjadi delapan untuk melakukan pengujian analog melawan kerangka kerja yang setara InterFaceGAN, GANSpace, dan StyleFlow.
Delapan atribut yang dipilih adalah Usia, Kebotakan, Jenggot, Ekspresi, Jenis Kelamin, Kacamata, Gaya, dan Yaw. Diperlukan untuk mengubah kerangka kerja yang bersaing untuk beberapa dari delapan atribut yang tidak diprovisikan dalam distribusi asli, seperti menambahkan kebotakan dan jenggot ke InterFaceGAN.
Seperti yang diharapkan, tingkat entanglement yang lebih besar terjadi pada arsitektur saingan. Misalnya, dalam satu tes, InterFaceGAN dan StyleFlow keduanya mengubah jenis kelamin subjek saat diminta untuk menerapkan usia:

Dua kerangka kerja yang bersaing menggulirkan perubahan jenis kelamin ke dalam transformasi ‘usia’, juga mengubah warna rambut tanpa permintaan langsung dari pengguna.
Selain itu, dua saingan menemukan bahwa kacamata dan usia adalah aspek yang tidak terpisahkan:

Kacamata dan perubahan warna rambut dibuang tanpa biaya tambahan!
Ini bukanlah kemenangan seragam untuk penelitian: seperti yang dapat dilihat dalam video yang disertakan di akhir artikel, kerangka kerja ini adalah yang paling tidak efektif saat mencoba melakukan ekstrapolasi sudut yang beragam (yaw), sementara GANSpace memiliki hasil umum yang lebih baik untuk usia dan penerapan kacamata. Kerangka kerja laten-ke-laten terikat dengan GANSpace dan StyleFlow mengenai penambahan pitch (sudut kepala).

Hasil dihitung berdasarkan kalibrasi detektor wajah MTCNN. Hasil yang lebih rendah lebih baik.
Untuk detail lebih lanjut dan resolusi yang lebih baik dari contoh, lihat video yang menyertain makalah di bawah.
Dipublikasikan pertama kali pada 16 Februari 2022.












