
Best Of
Մեքենայի ուսուցման 10 լավագույն ալգորիթմները
Թեև մենք ապրում ենք GPU-ով արագացված մեքենայական ուսուցման արտասովոր նորարարությունների ժամանակաշրջանում, վերջին հետազոտական փաստաթղթերում հաճախ (և ակնհայտորեն) ներկայացված են ալգորիթմներ, որոնք տասնամյակներ են, որոշ դեպքերում՝ 70 տարեկան:
Ոմանք կարող են պնդել, որ այս հին մեթոդներից շատերը պատկանում են «վիճակագրական վերլուծության» ճամբարին, այլ ոչ թե մեքենայական ուսուցման, և նախընտրում են թվագրել ոլորտի գալուստը միայն 1957թ. Perceptron-ի գյուտը.
Հաշվի առնելով, թե որքանով են այս հին ալգորիթմները աջակցում և ներգրավված մեքենայական ուսուցման վերջին միտումների և վերնագրերի գրավիչ զարգացումների մեջ, դա վիճելի դիրքորոշում է: Այսպիսով, եկեք տեսնենք վերջին նորարարությունների հիմքում ընկած որոշ «դասական» շինանյութեր, ինչպես նաև որոշ նոր գրառումներ, որոնք վաղաժամ հայտ են ներկայացնում AI-ի փառքի սրահի համար:
1. Տրանսֆորմատորներ
2017 թվականին Google Research-ը ղեկավարել է հետազոտական համագործակցությունը, որն ավարտվել է թուղթ Ուշադրությունն այն ամենն է, ինչ ձեզ հարկավոր է. Աշխատանքը նախանշում էր նոր ճարտարապետություն, որը նպաստում էր ուշադրության մեխանիզմներ կոդավորիչ/ապակոդավորիչ և կրկնվող ցանցային մոդելներում «խողովակաշարից» մինչև ինքնուրույն կենտրոնական փոխակերպման տեխնոլոգիա:
Մոտեցումը կրկնօրինակվեց տրանսֆորմատորև այդ ժամանակից ի վեր դարձել է բնական լեզվի մշակման (NLP) հեղափոխական մեթոդոլոգիա՝ հզորացնելով, ի թիվս բազմաթիվ այլ օրինակների, ավտոռեգեսիվ լեզվի մոդելին և AI-ի պաստառի համար նախատեսված GPT-3-ին:
![]()
Տրանսֆորմատորները նրբագեղորեն լուծեցին խնդիրը հաջորդականության փոխակերպում, որը նաև կոչվում է «փոխակերպում», որը զբաղված է մուտքային հաջորդականությունների ելքային հաջորդականությունների վերամշակմամբ։ Տրանսֆորմատորը նաև ստանում և կառավարում է տվյալները շարունակական ձևով, այլ ոչ թե հաջորդական խմբաքանակներով, ինչը թույլ է տալիս «հիշողության կայունություն», որը RNN ճարտարապետությունները նախատեսված չեն ստանալու համար: Տրանսֆորմատորների ավելի մանրամասն ակնարկի համար նայեք մեր հղում հոդվածը.
Ի տարբերություն կրկնվող նեյրոնային ցանցերի (RNN), որոնք սկսել էին գերակշռել ML հետազոտությունը CUDA դարաշրջանում, տրանսֆորմատորային ճարտարապետությունը կարող էր նաև հեշտությամբ լինել. զուգահեռաբար, բացելով ճանապարհը արդյունավետորեն անդրադառնալու տվյալների շատ ավելի մեծ կորպուսին, քան RNN-ները:
Հանրաճանաչ օգտագործում
Transformers-ը գրավեց հանրության երևակայությունը 2020 թվականին OpenAI-ի GPT-3-ի թողարկմամբ, որն այն ժամանակ ռեկորդ էր սահմանել: 175 միլիարդ պարամետր. Այս ակնհայտ ապշեցուցիչ ձեռքբերումը ի վերջո ստվերվեց հետագա նախագծերի կողմից, ինչպիսին է 2021 թ. ազատ արձակել Microsoft-ի Megatron-Turing NLG 530B-ից, որը (ինչպես ենթադրում է անունը) ունի ավելի քան 530 միլիարդ պարամետր:

Hyperscale Transformer NLP նախագծերի ժամանակացույց: Source: Microsoft
Տրանսֆորմատորային ճարտարապետությունը նույնպես անցել է NLP-ից համակարգչային տեսլականի վրա՝ սնուցելով ա նոր սերունդ պատկերների սինթեզի շրջանակներ, ինչպիսիք են OpenAI-ը CLIP և ԴԱԼ-Է, որոնք օգտագործում են text>image տիրույթի քարտեզագրում՝ թերի պատկերները ավարտելու և վերապատրաստված տիրույթներից նոր պատկերներ սինթեզելու համար՝ հարակից հավելվածների աճող թվի մեջ:

DALL-E-ն փորձում է լրացնել Պլատոնի կիսանդրու մասնակի պատկերը: Աղբյուր՝ https://openai.com/blog/dall-e/
2. Գեներատիվ հակառակորդ ցանցեր (GANs)
Թեև տրանսֆորմատորները ստացել են արտակարգ լրատվամիջոցների լուսաբանում GPT-3-ի թողարկման և ընդունման շնորհիվ, Generative Adversarial Network (GAN) ինքնին դարձել է ճանաչելի բրենդ և կարող է ի վերջո միանալ խորը մտքեր որպես բայ.
Առաջին առաջարկված ի 2014 և հիմնականում օգտագործվում է պատկերների սինթեզի համար՝ Generative Adversarial Network ճարտարապետություն կազմված է ա Գեներատոր եւ Խտրականացնող. The Generator-ը պտտվում է տվյալների բազայի հազարավոր պատկերների միջով՝ կրկնվող փորձելով դրանք վերակառուցել: Յուրաքանչյուր փորձի համար Խտրականացնողը գնահատում է Գեներատորի աշխատանքը և հետ է ուղարկում Գեներատորին՝ ավելի լավ աշխատելու համար, բայց առանց որևէ պատկերացում կազմելու նախորդ վերակառուցման սխալների մասին:

Աղբյուր՝ https://developers.google.com/machine-learning/gan/gan_structure
Սա ստիպում է Գեներատորին ուսումնասիրել բազմաթիվ պողոտաներ՝ փոխարենը հետևելու հնարավոր փակուղիներին, որոնք կհանգեցնեին, եթե Խտրականացնողը նրան ասեր, թե որտեղ է այն սխալ գնում (տես ստորև #8): Մինչ ուսուցումն ավարտվի, Գեներատորն ունի տվյալների հավաքածուի կետերի միջև հարաբերությունների մանրամասն և համապարփակ քարտեզ:

Թղթից GAN հավասարակշռության բարելավում` տարածական իրազեկության բարձրացման միջոցովՆոր շրջանակը պտտվում է GAN-ի երբեմն առեղծվածային թաքնված տարածության միջով՝ ապահովելով արձագանքող գործիք պատկերի սինթեզի ճարտարապետության համար: Աղբյուր՝ https://genforce.github.io/eqgan/
Ըստ անալոգիայի՝ սա է տարբերությունը Լոնդոնի կենտրոնական ուղևորություն սովորելու կամ ջանասիրաբար ձեռք բերելու միջև։ Գիտելիքը.
Արդյունքը բարձր մակարդակի հատկանիշների հավաքածու է վարժեցված մոդելի թաքնված տարածության մեջ: Բարձր մակարդակի հատկանիշի իմաստային ցուցիչը կարող է լինել «անձը», մինչդեռ հատկանիշի հետ կապված առանձնահատկությունների միջոցով իջնելը կարող է բացահայտել այլ սովորված բնութագրեր, ինչպիսիք են «տղամարդ» և «իգական»: Ավելի ցածր մակարդակներում ենթահատկանիշները կարող են բաժանվել «շիկահեր», «կովկասյան» և այլն:
Խճճվածությունն է ուշագրավ խնդիր GAN-ների և կոդավորիչ/ապակոդավորող շրջանակների թաքնված տարածության մեջ. GAN-ի կողմից ստեղծված կանացի դեմքի ժպիտը գաղտնի տարածության մեջ նրա «ինքնության» խճճված հատկանիշն է, թե՞ դա զուգահեռ ճյուղ է:

GAN-ի կողմից ստեղծված դեմքերն այս անձից գոյություն չունեն: Աղբյուրը՝ https://this-person-does-not-exist.com/en
Անցած մի քանի տարին առաջ բերեց աճող թվով նոր հետազոտական նախաձեռնություններ այս առումով՝ հավանաբար ճանապարհ հարթելով խաղարկային մակարդակի, Photoshop ոճով խմբագրման համար GAN-ի թաքնված տարածության համար, բայց այս պահին շատ փոխակերպումներ արդյունավետ են: բոլորը կամ ոչինչ» փաթեթները: Հատկանշական է, որ 2021-ի վերջին NVIDIA-ի EditGAN թողարկումը հասնում է ա մեկնաբանելիության բարձր մակարդակ թաքնված տարածության մեջ՝ օգտագործելով իմաստային հատվածավորման դիմակներ:
Հանրաճանաչ օգտագործում
Բացի նրանց (իրականում բավականին սահմանափակ) ներգրավվածությունից հանրահայտ խորը կեղծ տեսանյութերում, պատկերի/վիդեոկենտրոն GAN-ները վերջին չորս տարիների ընթացքում շատացել են՝ հմայելով ինչպես հետազոտողներին, այնպես էլ հանրությանը: Նոր թողարկումների գլխապտույտ արագությանը և հաճախականությանը հետևելը դժվարություն է, թեև GitHub պահեստը Հիանալի GAN հավելվածներ նպատակ ունի տրամադրել համապարփակ ցուցակ:
Generative Adversarial Networks-ը տեսականորեն կարող է ստանալ հատկանիշներ ցանկացած լավ շրջանակված տիրույթից, ներառյալ տեքստը.
3: SVM
Ծագումով ի 1963, Աջակցման վեկտորային մեքենա (SVM) հիմնական ալգորիթմ է, որը հաճախակի է հայտնվում նոր հետազոտություններում: SVM-ի ներքո վեկտորները քարտեզագրում են տվյալների կետերի հարաբերական դիրքը տվյալների բազայում, մինչդեռ աջակցություն վեկտորները գծում են տարբեր խմբերի, հատկանիշների կամ գծերի սահմանները:
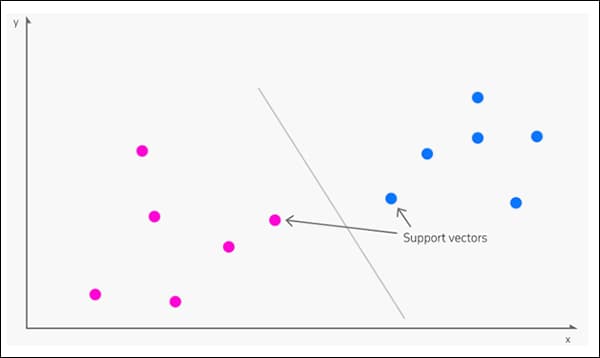
Աջակցող վեկտորները սահմանում են խմբերի միջև սահմանները: Աղբյուր՝ https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Ստացված սահմանը կոչվում է a հիպերպլան.
Հատկությունների ցածր մակարդակներում SVM-ն է երկչափ (վերևում գտնվող պատկերը), բայց որտեղ ավելի մեծ թվով խմբեր կամ տեսակներ կան, այն դառնում է եռաչափ.

Կետերի և խմբերի ավելի խորը զանգվածը պահանջում է եռաչափ SVM: Աղբյուր՝ https://cml.rhul.ac.uk/svm.html
Հանրաճանաչ օգտագործում
Քանի որ աջակցող վեկտորային մեքենաները կարող են արդյունավետ և ագնոստիկ կերպով ուղղել տարբեր տեսակի բարձրաչափ տվյալներ, դրանք լայնորեն հայտնվում են մեքենայական ուսուցման տարբեր ոլորտներում, ներառյալ. խորը կեղծիքի հայտնաբերում, պատկերների դասակարգում, ատելության խոսքի դասակարգում, ԴՆԹ վերլուծություն և բնակչության կառուցվածքի կանխատեսումայլոց մեջ:
4. K-Means Clustering
Կլաստերավորումն ընդհանուր առմամբ ան չվերահսկվող ուսուցում մոտեցում, որը ձգտում է դասակարգել տվյալների կետերը խտության գնահատում, ստեղծելով ուսումնասիրվող տվյալների բաշխման քարտեզ։

K-նշանակում է տվյալների մեջ աստվածների հատվածների, խմբերի և համայնքների խմբավորում: Աղբյուր՝ https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Means Clustering դարձել է այս մոտեցման ամենահայտնի իրականացումը, տվյալների մատնանշումը տարբերակիչ «K խմբերի» մեջ, որոնք կարող են ցույց տալ ժողովրդագրական հատվածները, առցանց համայնքները կամ ցանկացած այլ հնարավոր գաղտնի ագրեգացիա, որը սպասում է չմշակված վիճակագրական տվյալների հայտնաբերմանը:

Կլաստերները ձևավորվում են K-Means վերլուծության մեջ: Աղբյուր՝ https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
K արժեքը ինքնին որոշիչ գործոն է գործընթացի օգտակարության և կլաստերի համար օպտիմալ արժեք սահմանելու հարցում: Սկզբում K արժեքը նշանակվում է պատահականորեն, և դրա առանձնահատկությունները և վեկտորային բնութագրերը համեմատվում են հարևանների հետ: Այն հարևանները, որոնք ամենից շատ նման են տվյալների կետին պատահականորեն նշանակված արժեքով, վերագրվում են դրա կլաստերին, քանի դեռ տվյալները չեն տալիս բոլոր խմբավորումները, որոնք թույլ է տալիս գործընթացը:
Կլաստերների միջև տարբեր արժեքների քառակուսի սխալի կամ «արժեքի» սյուժեն կբացահայտի արմունկի կետ տվյալների համար.

«Արմունկի կետը» կլաստերային գրաֆիկում: Աղբյուր՝ https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Անկյունի կետը հայեցակարգով նման է այն ձևին, որով կորուստը հարթվում է մինչև նվազող եկամուտները տվյալների բազայի վերապատրաստման դասընթացի ավարտին: Այն ներկայացնում է այն կետը, երբ խմբերի միջև այլ տարբերություններ չեն երևա՝ ցույց տալով տվյալների հաղորդման հետագա փուլերին անցնելու պահը, կամ այլապես՝ զեկուցելու արդյունքները:
Հանրաճանաչ օգտագործում
K-Means Clustering-ը, հասկանալի պատճառներով, առաջնային տեխնոլոգիա է հաճախորդների վերլուծության մեջ, քանի որ այն առաջարկում է հստակ և բացատրելի մեթոդաբանություն՝ մեծ քանակությամբ առևտրային գրառումները ժողովրդագրական պատկերացումների և «առաջատարների» վերածելու համար:
Այս հավելվածից դուրս K-Means Clustering-ը նույնպես օգտագործվում է սողանքի կանխատեսում, բժշկական պատկերի հատվածավորում, պատկերների սինթեզ GAN-ներով, փաստաթղթերի դասակարգում, եւ քաղաքային պլանավորում, ի թիվս բազմաթիվ այլ պոտենցիալ և փաստացի օգտագործման:
5. Պատահական անտառ
Պատահական անտառը ան անսամբլային ուսուցում մեթոդ, որը միջինացնում է արդյունքը զանգվածից որոշել ծառերը ստեղծել արդյունքի ընդհանուր կանխատեսում:

Աղբյուր՝ https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Եթե դուք ուսումնասիրել եք այն նույնիսկ այնքան քիչ, որքան դիտելը Վերադառնալ դեպի ապագա եռագրություն, որոշումների ծառը ինքնին բավականին հեշտ է հայեցակարգել. մի շարք ուղիներ են ընկած ձեր առջև, և յուրաքանչյուր ճանապարհ ճյուղավորվում է դեպի նոր արդյունք, որն իր հերթին պարունակում է հետագա հնարավոր ուղիներ:
In ամրապնդման ուսուցում, դուք կարող եք նահանջել ճանապարհից և նորից սկսել ավելի վաղ դիրքից, մինչդեռ որոշումների ծառերը պարտավորվում են կատարել իրենց ճանապարհորդությունները:
Այսպիսով, Random Forest ալգորիթմը, ըստ էության, հանդիսանում է որոշումների համար սփրեդ-խաղադրույք: Ալգորիթմը կոչվում է «պատահական», քանի որ այն կազմում է ժամանակավոր ընտրություն և դիտարկումներ՝ հասկանալու համար միջին հաշվով որոշումների ծառի զանգվածի արդյունքների գումարը:
Քանի որ այն հաշվի է առնում բազմաթիվ գործոններ, պատահական անտառային մոտեցումը կարող է ավելի դժվար լինել իմաստալից գծապատկերների վերածելը, քան որոշման ծառը, բայց, ամենայն հավանականությամբ, զգալիորեն ավելի արդյունավետ կլինի:
Որոշման ծառերը ենթակա են գերհարմարեցման, որտեղ ստացված արդյունքները հատուկ են տվյալներին և չեն կարող ընդհանրացվել: Random Forest-ի կողմից տվյալների կետերի կամայական ընտրությունը պայքարում է այս միտումի դեմ՝ խորացնելով տվյալների իմաստալից և օգտակար ներկայացուցչական միտումները:

Որոշման ծառի ռեգրեսիա. Աղբյուր՝ https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Հանրաճանաչ օգտագործում
Ինչպես այս ցանկի ալգորիթմներից շատերի դեպքում, Random Forest-ը սովորաբար գործում է որպես տվյալների «վաղ» տեսակավորող և զտիչ, և որպես այդպիսին հետևողականորեն հայտնվում է նոր հետազոտական փաստաթղթերում: Պատահական անտառի օգտագործման որոշ օրինակներ ներառում են Մագնիսական ռեզոնանսային պատկերի սինթեզ, Bitcoin գնի կանխատեսում, մարդահամարի հատվածավորում, տեքստի դասակարգում և վարկային քարտի խարդախության հայտնաբերում.
Քանի որ Random Forest-ը ցածր մակարդակի ալգորիթմ է մեքենայական ուսուցման ճարտարապետություններում, այն կարող է նաև նպաստել ցածր մակարդակի այլ մեթոդների, ինչպես նաև վիզուալացման ալգորիթմների կատարմանը, այդ թվում՝ Ինդուկտիվ կլաստերավորում, Հատկանիշի փոխակերպումներ, տեքստային փաստաթղթերի դասակարգում օգտագործելով նոսր հատկանիշներ, եւ ցուցադրվում են խողովակաշարերը.
6. Միամիտ Բայես
Համակցված խտության գնահատման հետ (տես 4, վերևում), ա միամիտ Բայես Դասակարգիչը հզոր, բայց համեմատաբար թեթև ալգորիթմ է, որն ի վիճակի է գնահատել հավանականությունները տվյալների հաշվարկված հատկանիշների հիման վրա:

Հատկանշական հարաբերությունները միամիտ Bayes դասակարգիչում: Աղբյուր՝ https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
«Միամիտ» տերմինը վերաբերում է ենթադրությանը Բեյսի թեորեմ որ հատկանիշները կապ չունեն, հայտնի է որպես պայմանական անկախություն. Եթե դուք որդեգրեք այս տեսակետը, բադի պես քայլելն ու խոսելը բավարար չեն պարզելու համար, որ մենք գործ ունենք բադի հետ, և ոչ մի «ակնհայտ» ենթադրություն վաղաժամ չի ընդունվում:
Ակադեմիական և հետաքննական խստության այս մակարդակը չափազանց մեծ կլինի այնտեղ, որտեղ առկա է «ողջախոհությունը», բայց արժեքավոր չափանիշ է, երբ անցնում ենք բազմաթիվ անորոշությունների և պոտենցիալ կապ չունեցող փոխկապակցվածությունների վրա, որոնք կարող են գոյություն ունենալ մեքենայական ուսուցման տվյալների բազայում:
Բնօրինակ Բայեսյան ցանցում առանձնահատկությունները ենթակա են գնահատման գործառույթներ, ներառյալ նկարագրության նվազագույն երկարությունը և Բայեսյան գոլը, որը կարող է սահմանափակումներ դնել տվյալների վրա՝ կապված տվյալների կետերի միջև հայտնաբերված գնահատված կապերի և այդ կապերի հոսքի ուղղությամբ:
Բայեսի միամիտ դասակարգիչը, ընդհակառակը, գործում է՝ ենթադրելով, որ տվյալ օբյեկտի հատկանիշներն անկախ են՝ հետագայում օգտագործելով Բայեսի թեորեմը՝ տվյալ օբյեկտի հավանականությունը հաշվարկելու համար՝ հիմնվելով նրա հատկանիշների վրա:
Հանրաճանաչ օգտագործում
Naive Bayes ֆիլտրերը լավ ներկայացված են հիվանդության կանխատեսում և փաստաթղթերի դասակարգում, սպամի ֆիլտրացման, զգացմունքների դասակարգում, առաջարկող համակարգեր, եւ խարդախության հայտնաբերում, ի թիվս այլ հավելվածների:
7: K- Մոտակա հարևանները (KNN)
Առաջին անգամ առաջարկվել է ԱՄՆ ռազմաօդային ուժերի ավիացիոն բժշկության դպրոցի կողմից ի 1951և ստիպված լինելով իրեն հարմարեցնել 20-րդ դարի կեսերի ժամանակակից հաշվողական սարքավորումներին, K-Մոտակա հարևանները (KNN) նիհար ալգորիթմ է, որը դեռևս աչքի է ընկնում ակադեմիական աշխատություններում և մասնավոր հատվածի մեքենայական ուսուցման հետազոտական նախաձեռնություններում:
KNN-ը կոչվում է «ծույլ սովորող», քանի որ այն սպառիչ կերպով սկանավորում է տվյալների բազան՝ տվյալների կետերի միջև փոխհարաբերությունները գնահատելու համար, այլ ոչ թե պահանջում է մեքենայական ուսուցման լիարժեք մոդելի վերապատրաստում:

KNN խմբավորում. Աղբյուր. https://scikit-learn.org/stable/modules/neighbors.html
Թեև KNN-ը ճարտարապետական առումով սլացիկ է, նրա համակարգված մոտեցումը զգալի պահանջարկ է դնում կարդալու/գրելու գործողությունների վրա, և դրա օգտագործումը շատ մեծ տվյալների հավաքածուներում կարող է խնդրահարույց լինել առանց լրացուցիչ տեխնոլոգիաների, ինչպիսիք են Հիմնական բաղադրիչների վերլուծությունը (PCA), որը կարող է փոխակերպել բարդ և մեծ ծավալի տվյալների հավաքածուներ: մեջ ներկայացուցչական խմբավորումներ որ KNN-ը կարող է անցնել ավելի քիչ ջանքերով:
A վերջին ուսումնասիրությունը գնահատեց մի շարք ալգորիթմների արդյունավետությունն ու տնտեսությունը, որոնց հանձնարարված է կանխատեսել, թե արդյոք աշխատակիցը կհեռանա ընկերությունից, պարզելով, որ յոթանասունական KNN-ը գերազանցում է ավելի ժամանակակից հավակնորդներին ճշգրտության և կանխատեսող արդյունավետության առումով:
Հանրաճանաչ օգտագործում
Չնայած հայեցակարգի և կատարման իր հանրաճանաչ պարզությանը, KNN-ը խրված չէ 1950-ականներին. այն հարմարեցվել է ավելի շատ DNN-ի վրա կենտրոնացած մոտեցում Փենսիլվանիայի պետական համալսարանի 2018 թվականի առաջարկով և մնում է կենտրոնական վաղ փուլի գործընթաց (կամ հետմշակման վերլուծական գործիք) շատ ավելի բարդ մեքենայական ուսուցման շրջանակներում:
Տարբեր կոնֆիգուրացիաներում KNN-ն օգտագործվել է կամ դրա համար առցանց ստորագրության ստուգում, պատկերների դասակարգում, տեքստի արդյունահանում, բերքի կանխատեսում, եւ դեմքի ճանաչում, բացի այլ հավելվածներից և միավորումներից:

KNN-ի վրա հիմնված դեմքի ճանաչման համակարգ մարզումների ժամանակ: Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8. Մարկովի որոշման գործընթաց (MDP)
Մաթեմատիկական շրջանակ, որը ներկայացրել է ամերիկացի մաթեմատիկոս Ռիչարդ Բելմանը ի 1957Մարկովյան որոշման գործընթացը (MDP) ամենահիմնական բլոկներից մեկն է ամրապնդման ուսուցում ճարտարապետություններ. Ինքնին հայեցակարգային ալգորիթմ է, այն հարմարեցվել է մեծ թվով այլ ալգորիթմների մեջ և հաճախ կրկնվում է AI/ML հետազոտության ներկայիս մշակույթում:
MDP-ն ուսումնասիրում է տվյալների միջավայրը՝ օգտագործելով դրա ներկայիս վիճակի գնահատումը (այսինքն՝ «որտեղ» է այն գտնվում տվյալների մեջ)՝ որոշելու, թե տվյալների որ հանգույցն է ուսումնասիրել հաջորդը:

Աղբյուր՝ https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Մարկովյան որոշման հիմնական գործընթացը նախապատվությունը կտա կարճաժամկետ առավելություններին ավելի ցանկալի երկարաժամկետ նպատակներից: Այդ իսկ պատճառով, այն սովորաբար ներդրվում է ուժեղացման ուսուցման քաղաքականության ավելի համապարփակ ճարտարապետության համատեքստում և հաճախ ենթակա է սահմանափակող գործոնների, ինչպիսիք են. զեղչված պարգևև շրջակա միջավայրի փոփոխող այլ փոփոխականներ, որոնք կխանգարեն նրան շտապել դեպի անմիջական նպատակ՝ առանց հաշվի առնելու ավելի լայն ցանկալի արդյունքը:
Հանրաճանաչ օգտագործում
MDP-ի ցածր մակարդակի հայեցակարգը լայնորեն տարածված է ինչպես հետազոտության, այնպես էլ մեքենայական ուսուցման ակտիվ տեղակայման մեջ: Այն առաջարկվել է IoT անվտանգության պաշտպանության համակարգեր, ձկան բերքահավաք, եւ շուկայի կանխատեսում.
Բացի դրանից ակնհայտ կիրառելիություն Շախմատի և այլ խիստ հաջորդական խաղերի համար MDP-ն նույնպես բնական մրցակից է ռոբոտաշինության համակարգերի ընթացակարգային ուսուցում, ինչպես տեսնում ենք ստորև ներկայացված տեսանյութում։

9. Ժամկետային հաճախականություն-Փաստաթղթի հակադարձ հաճախականություն
Ժամկետային հաճախականություն (TF) փաստաթղթում բառի հայտնվելու դեպքերի թիվը բաժանում է այդ փաստաթղթի բառերի ընդհանուր թվի վրա: Այսպիսով բառը կնքել հազար բառանոց հոդվածում մեկ անգամ հայտնվելը ունի 0.001 տերմինի հաճախականություն: Ինքնին, TF-ն հիմնականում անօգուտ է որպես տերմինի կարևորության ցուցիչ, քանի որ անիմաստ հոդվածները (օրինակ՝ a, և, որ, եւ it) գերակշռում են.
Տերմինի համար իմաստալից արժեք ստանալու համար «Հակադարձ փաստաթղթի հաճախականությունը» (IDF) հաշվարկում է բառի TF-ն տվյալների բազայի մի քանի փաստաթղթերում՝ ցածր գնահատական տալով շատ բարձր հաճախականությանը: կանգառներ, ինչպիսիք են հոդվածները։ Ստացված հատկանիշի վեկտորները նորմալացվում են ամբողջ արժեքներով՝ յուրաքանչյուր բառին համապատասխան կշիռ հատկացնելով:

TF-IDF-ն կշռում է տերմինների արդիականությունը՝ հիմնված մի շարք փաստաթղթերի հաճախականության վրա, իսկ ավելի հազվադեպ հանդիպողը՝ կարևորության ցուցանիշ: Աղբյուրը՝ https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Թեև այս մոտեցումը խանգարում է իմաստային նշանակություն ունեցող բառերի կորստին ծայրամասեր, հաճախականության կշիռը շրջելը ինքնաբերաբար չի նշանակում, որ ցածր հաճախականության տերմին է Նշում արտառոց, քանի որ որոշ բաներ հազվադեպ են լինում և անարժեք. Հետևաբար, ցածր հաճախականությամբ տերմինը պետք է ապացուցի իր արժեքը ավելի լայն ճարտարապետական համատեքստում՝ ներառելով (նույնիսկ յուրաքանչյուր փաստաթղթի համար ցածր հաճախականությամբ) մի շարք փաստաթղթերի տվյալների բազայում:
Չնայած դրան տարիքըTF-IDF-ը հզոր և հանրաճանաչ մեթոդ է բնական լեզվի մշակման շրջանակներում նախնական զտման անցումների համար:
Հանրաճանաչ օգտագործում
Քանի որ TF-IDF-ը գոնե որոշակի դեր է խաղացել Google-ի հիմնականում գաղտնի PageRank ալգորիթմի մշակման մեջ վերջին քսան տարիների ընթացքում, այն դարձել է. շատ լայնորեն ընդունված որպես մանիպուլյատիվ SEO մարտավարություն, չնայած Ջոն Մյուլլերի 2019 թ մերժում դրա կարևորությունը որոնման արդյունքների համար:
PageRank-ի շուրջ գաղտնիության պատճառով չկա հստակ ապացույց, որ TF-IDF-ն է Նշում ներկայումս արդյունավետ մարտավարություն Google-ի վարկանիշում բարձրանալու համար: հրահրող քննարկում ՏՏ մասնագետների շրջանում վերջերս ցույց է տալիս հանրաճանաչ ըմբռնում, ճիշտ է, թե ոչ, այդ տերմինի չարաշահումը դեռ կարող է հանգեցնել SEO-ի տեղադրման բարելավմանը (չնայած լրացուցիչ մենաշնորհի չարաշահման մեղադրանքները և ավելորդ գովազդ լղոզել այս տեսության սահմանները):
10. Ստոխաստիկ գրադիենտ ծագում
Ստոխաստիկ գրադիենտ ծագում (SGD) ավելի ու ավելի տարածված մեթոդ է մեքենայական ուսուցման մոդելների ուսուցման օպտիմալացման համար:
Gradient Descent-ը ինքնին մեթոդ է՝ օպտիմալացնելու և հետագայում քանակականացնելու այն բարելավումը, որը մոդելը կատարում է մարզման ընթացքում:
Այս իմաստով, «գրադիենտը» ցույց է տալիս թեքություն դեպի ներքև (այլ ոչ թե գույնի վրա հիմնված աստիճանավորում, տես ստորև նկարը), որտեղ «բլրի» ամենաբարձր կետը՝ ձախ կողմում, ներկայացնում է մարզման գործընթացի սկիզբը: Այս փուլում մոդելը դեռևս մեկ անգամ չի տեսել տվյալների ամբողջականությունը և բավականաչափ չի սովորել տվյալների միջև փոխհարաբերությունների մասին՝ արդյունավետ փոխակերպումներ առաջացնելու համար:

Գրադիենտ վայրէջք FaceSwap-ի վերապատրաստման դասընթացի վրա: Մենք կարող ենք տեսնել, որ մարզումը որոշ ժամանակով բարձրացել է երկրորդ խաղակեսում, բայց ի վերջո վերականգնել է իր ճանապարհը գրադիենտից դեպի ընդունելի կոնվերգենցիա:
Ամենացածր կետը, աջ կողմում, ներկայացնում է կոնվերգենցիան (այն կետը, որտեղ մոդելը նույնքան արդյունավետ է, որքան երբևէ անցնելու է պարտադրված սահմանափակումների և պարամետրերի տակ):
Գրադիենտը գործում է որպես ռեկորդ և կանխատեսող սխալի մակարդակի (որքան ճշգրիտ է մոդելը ներկայումս քարտեզագրել տվյալների փոխհարաբերությունները) և կշիռների (պարամետրերը, որոնք ազդում են մոդելի սովորելու ձևի վրա) անհամամասնության համար:
Առաջընթացի այս գրառումը կարող է օգտագործվել տեղեկացնելու համար ա ուսուցման դրույքաչափերի ժամանակացույցը, ավտոմատ գործընթաց, որը ճարտարապետությանը հուշում է դառնալ ավելի հատիկավոր և ճշգրիտ, քանի որ վաղ անորոշ մանրամասները վերածվում են հստակ հարաբերությունների և քարտեզագրումների: Փաստորեն, գրադիենտ կորուստը տալիս է ճիշտ ժամանակին քարտեզ, թե որտեղ պետք է անցնի վերապատրաստումը և ինչպես պետք է այն շարունակվի:
Stochastic Gradient Descent-ի նորամուծությունը կայանում է նրանում, որ այն թարմացնում է մոդելի պարամետրերը յուրաքանչյուր ուսումնական օրինակի վրա յուրաքանչյուր կրկնության համար, ինչը ընդհանուր առմամբ արագացնում է դեպի մերձեցման ճանապարհը: Վերջին տարիներին հիպերմասշտաբային տվյալների հավաքածուների հայտնվելու պատճառով SGD-ն վերջերս մեծ ժողովրդականություն է վայելել՝ որպես հաջորդող լոգիստիկ խնդիրները լուծելու հնարավոր մեթոդ:
Մյուս կողմից, SGD-ն ունի բացասական հետևանքներ առանձնահատկությունների մասշտաբավորման համար և կարող է պահանջել ավելի շատ կրկնություններ՝ նույն արդյունքին հասնելու համար, որոնք պահանջում են լրացուցիչ պլանավորում և լրացուցիչ պարամետրեր՝ համեմատած սովորական Գրադիենտ ծագման հետ:
Հանրաճանաչ օգտագործում
Իր կարգավորելիության շնորհիվ և չնայած իր թերություններին, SGD-ն դարձել է ամենահայտնի օպտիմալացման ալգորիթմը նեյրոնային ցանցերի տեղադրման համար: SGD-ի կոնֆիգուրացիաներից մեկը, որը դառնում է գերիշխող նոր AI/ML հետազոտական փաստաթղթերում, ադապտիվ պահի գնահատման ընտրությունն է (ADAM, ներկայացված ի 2015) օպտիմիզատոր:
ADAM-ը դինամիկ կերպով հարմարեցնում է ուսուցման արագությունը յուրաքանչյուր պարամետրի համար («հարմարվողական ուսուցման արագություն»), ինչպես նաև ներառում է նախորդ թարմացումների արդյունքները հետագա կազմաձևման մեջ («մոմենտում»): Բացի այդ, այն կարող է կազմաձևվել, որպեսզի օգտագործի ավելի ուշ նորարարությունները, ինչպիսիք են Նեստերովի թափը.
Այնուամենայնիվ, ոմանք պնդում են, որ իմպուլսի օգտագործումը կարող է նաև արագացնել ADAM-ը (և նմանատիպ ալգորիթմները) մինչև a ենթաօպտիմալ եզրակացություն. Ինչպես մեքենայական ուսուցման հետազոտական հատվածի արյունահոսող եզրերի մեծ մասի դեպքում, SGD-ն ընթացքի մեջ է:
Առաջին անգամ հրապարակվել է 10 թվականի փետրվարի 2022-ին: Փոփոխված է 10 փետրվարի 20.05 EET – ձևաչափում:















