
AI 101 թ
Ի՞նչ է չափումների կրճատումը:
Ի՞նչ է չափումների կրճատումը:
Չափերի կրճատում գործընթաց է, որն օգտագործվում է տվյալների շտեմարանի ծավալականությունը նվազեցնելու համար՝ հաշվի առնելով բազմաթիվ հատկանիշներ և դրանք ներկայացնելով որպես ավելի քիչ հատկանիշներ: Օրինակ, ծավալների կրճատումը կարող է օգտագործվել քսան հատկանիշներից բաղկացած տվյալների բազան ընդամենը մի քանի հատկանիշի կրճատելու համար: Չափերի կրճատումը սովորաբար օգտագործվում է չվերահսկվող ուսուցում առաջադրանքներ՝ բազմաթիվ հնարավորություններից ինքնաբերաբար դասեր ստեղծելու համար: Ավելի լավ հասկանալու համար ինչու և ինչպես է օգտագործվում ծավալների կրճատումը, մենք կանդրադառնանք բարձր ծավալային տվյալների հետ կապված խնդիրներին և ծավալների նվազեցման ամենատարածված մեթոդներին:
Լրացուցիչ չափերը հանգեցնում են չափից ավելի հարմարեցման
Չափայինությունը վերաբերում է տվյալների բազայի մեջ առկա հատկանիշների/սյունակների քանակին:
Հաճախ ենթադրվում է, որ մեքենայական ուսուցման մեջ ավելի շատ առանձնահատկություններ ավելի լավն են, քանի որ այն ստեղծում է ավելի ճշգրիտ մոդել: Այնուամենայնիվ, ավելի շատ հնարավորություններ պարտադիր չէ, որ թարգմանվեն ավելի լավ մոդելի:
Տվյալների հավաքածուի առանձնահատկությունները կարող են շատ տարբեր լինել՝ կախված նրանից, թե որքանով են դրանք օգտակար մոդելի համար, քանի որ շատ առանձնահատկություններ քիչ նշանակություն ունեն: Բացի այդ, որքան շատ հատկանիշներ պարունակի տվյալների բազան, այնքան ավելի շատ նմուշներ են անհրաժեշտ՝ ապահովելու համար, որ հատկանիշների տարբեր համակցությունները լավ ներկայացված են տվյալների մեջ: Հետևաբար, նմուշների քանակն աճում է հատկանիշների քանակին համամասնորեն: Ավելի շատ նմուշներ և ավելի շատ առանձնահատկություններ նշանակում են, որ մոդելը պետք է ավելի բարդ լինի, և քանի որ մոդելներն ավելի բարդ են դառնում, դրանք ավելի զգայուն են դառնում ավելորդ հարմարեցման նկատմամբ: Մոդելը չափազանց լավ է սովորում վերապատրաստման տվյալների օրինաչափությունները, և այն չի կարողանում ընդհանրացնել նմուշի տվյալներից դուրս:
Տվյալների բազայի ծավալայինության կրճատումն ունի մի քանի առավելություններ: Ինչպես նշվեց, ավելի պարզ մոդելներն ավելի քիչ են հակված գերհարմարվելու, քանի որ մոդելը պետք է ավելի քիչ ենթադրություններ անի այն մասին, թե ինչպես են հատկանիշները կապված միմյանց հետ: Բացի այդ, ավելի քիչ չափերը նշանակում են, որ ավելի քիչ հաշվողական հզորություն է պահանջվում ալգորիթմները վարժեցնելու համար: Նմանապես, ավելի փոքր ծավալներ ունեցող տվյալների բազայի համար անհրաժեշտ է ավելի քիչ պահեստային տարածք: Տվյալների հավաքածուի ծավալայինության կրճատումը կարող է նաև թույլ տալ ձեզ օգտագործել ալգորիթմներ, որոնք հարմար չեն բազմաթիվ առանձնահատկություններով տվյալների հավաքածուների համար:
Չափերի կրճատման ընդհանուր մեթոդներ
Չափերի կրճատումը կարող է լինել առանձնահատկությունների ընտրության կամ առանձնահատկությունների ճարտարագիտության միջոցով: Առանձնահատկությունների ընտրությունն այն է, որտեղ ինժեները բացահայտում է տվյալների հավաքածուի առավել համապատասխան հատկանիշները, մինչդեռ առանձնահատկություն ճարտարագիտություն նոր հատկանիշների ստեղծման գործընթացն է՝ այլ հատկանիշների համադրման կամ փոխակերպման միջոցով:
Առանձնահատկությունների ընտրությունը և ճարտարագիտությունը կարող են կատարվել ծրագրային կամ ձեռքով: Առանձնահատկությունները ձեռքով ընտրելիս և ինժեներական մշակելիս բնորոշ է տվյալների պատկերացումը՝ հատկանիշների և դասերի միջև փոխկապակցվածությունը հայտնաբերելու համար: Չափականության կրճատումն այս եղանակով կարող է բավականին ժամանակատար լինել, և, հետևաբար, հարթության նվազեցման ամենատարածված ուղիներից մի քանիսը ներառում են գրադարաններում հասանելի ալգորիթմների օգտագործումը, ինչպիսին է Scikit-learn for Python-ը: Չափականության կրճատման այս ընդհանուր ալգորիթմները ներառում են՝ Հիմնական բաղադրիչի վերլուծություն (PCA), եզակի արժեքի տարրալուծում (SVD) և գծային տարբերակիչ վերլուծություն (LDA):
Չվերահսկվող ուսուցման առաջադրանքների համար չափումների կրճատման համար օգտագործվող ալգորիթմները սովորաբար PCA-ն և SVD-ն են, մինչդեռ վերահսկվող ուսուցման ծավալների կրճատման համար օգտագործվող ալգորիթմները սովորաբար LDA-ն և PCA-ն են: Վերահսկվող ուսուցման մոդելների դեպքում նոր ստեղծվող առանձնահատկությունները պարզապես սնվում են մեքենայական ուսուցման դասակարգչի մեջ: Նկատի ունեցեք, որ այստեղ նկարագրված կիրառությունները պարզապես ընդհանուր օգտագործման դեպքեր են, և ոչ միակ պայմանները, որոնցում կարող են օգտագործվել այս տեխնիկան: Վերևում նկարագրված չափերի կրճատման ալգորիթմները պարզապես վիճակագրական մեթոդներ են և օգտագործվում են մեքենայական ուսուցման մոդելներից դուրս:
Հիմնական բաղադրիչի վերլուծություն

Լուսանկարը. Մատրիցա՝ բացահայտված հիմնական բաղադրիչներով
Հիմնական բաղադրիչի վերլուծություն (PCA) վիճակագրական մեթոդ է, որը վերլուծում է տվյալների բազայի բնութագրերը/առանձնահատկությունները և ամփոփում այն հատկանիշները, որոնք առավել ազդեցիկ են: Տվյալների հավաքածուի առանձնահատկությունները համակցված են միասին՝ ներկայացնելով այն ներկայացումները, որոնք պահպանում են տվյալների բնութագրերի մեծ մասը, բայց տարածված են ավելի քիչ չափերի վրա: Դուք կարող եք սա համարել որպես տվյալների «ցածրացում» ավելի բարձր չափման ներկայացումից մինչև ընդամենը մի քանի չափսերով:
Որպես իրավիճակի օրինակ, որտեղ PCA-ն կարող է օգտակար լինել, մտածեք գինին նկարագրելու տարբեր ձևերի մասին: Թեև հնարավոր է գինին նկարագրել՝ օգտագործելով շատ առանձնահատուկ առանձնահատկություններ, ինչպիսիք են CO2 մակարդակը, օդափոխության մակարդակը և այլն, նման առանձնահատուկ հատկանիշները կարող են համեմատաբար անօգուտ լինել գինու որոշակի տեսակի նույնականացման ժամանակ: Փոխարենը, ավելի խելամիտ կլինի տարբերակել տեսակը՝ հիմնվելով ավելի ընդհանուր հատկանիշների վրա, ինչպիսիք են համը, գույնը և տարիքը: PCA-ն կարող է օգտագործվել ավելի կոնկրետ առանձնահատկություններ համատեղելու և այնպիսի գործառույթներ ստեղծելու համար, որոնք ավելի ընդհանուր են, օգտակար և ավելի քիչ հավանական է, որ առաջացնեն ավելորդ հարմարեցում:
PCA-ն իրականացվում է՝ որոշելով, թե ինչպես են մուտքային հատկանիշները տարբերվում միջինից միմյանց նկատմամբ՝ որոշելով, թե արդյոք առկա են որևէ հարաբերություն հատկանիշների միջև: Դա անելու համար ստեղծվում է կովարիանտ մատրիցա, որը սահմանում է մի մատրից, որը կազմված է կովարիանսներից՝ կապված տվյալների հավաքածուի հատկանիշների հնարավոր զույգերի հետ: Սա օգտագործվում է փոփոխականների միջև փոխկապակցվածությունը որոշելու համար, ընդ որում բացասական կովարիանսը ցույց է տալիս հակադարձ հարաբերակցությունը և դրական հարաբերակցությունը, որը ցույց է տալիս դրական հարաբերակցությունը:
Տվյալների շտեմարանի հիմնական (ամենաազդեցիկ) բաղադրիչները ստեղծվում են սկզբնական փոփոխականների գծային համակցություններ ստեղծելու միջոցով, որը կատարվում է գծային հանրահաշվի հասկացությունների օգնությամբ, որոնք կոչվում են. սեփական արժեքներ և սեփական վեկտորներ. Համակցությունները ստեղծվում են այնպես, որ հիմնական բաղադրիչները միմյանց հետ փոխկապակցված չեն: Սկզբնական փոփոխականներում պարունակվող տեղեկատվության մեծ մասը սեղմված է առաջին մի քանի հիմնական բաղադրիչների մեջ, ինչը նշանակում է, որ ստեղծվել են նոր առանձնահատկություններ (հիմնական բաղադրիչներ), որոնք պարունակում են սկզբնական տվյալների տեղեկատվությունը փոքր ծավալային տարածության մեջ:
Եզակի արժեքի տարրալուծում
Լուսանկարը՝ Cmglee-ի կողմից – Սեփական աշխատանք, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
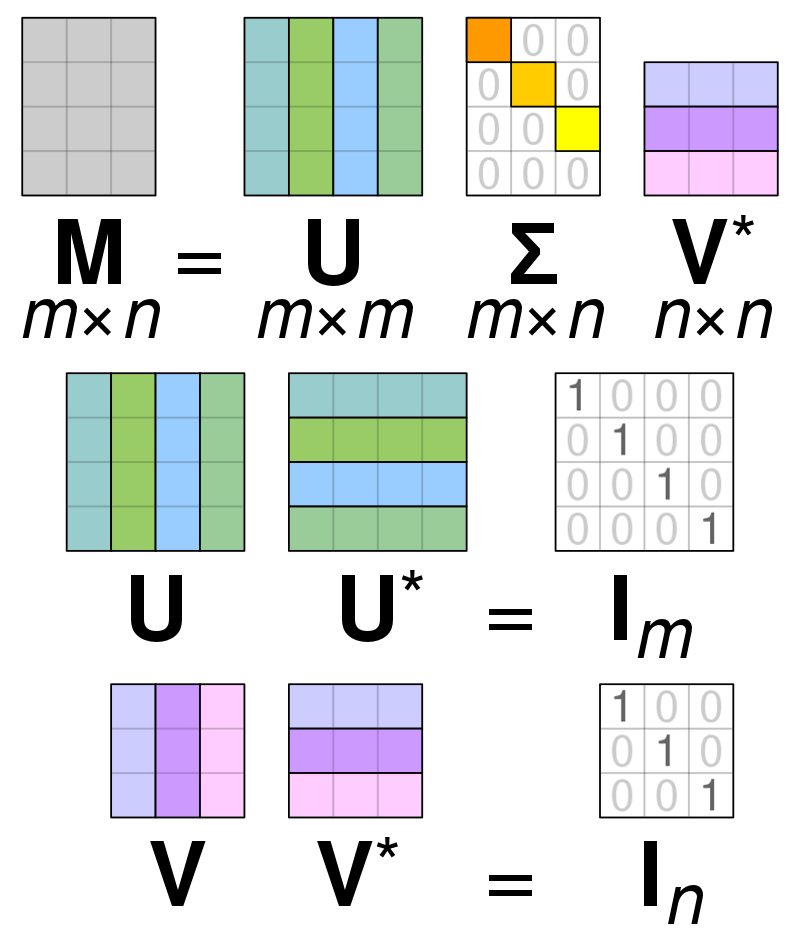
Եզակի արժեքի տարրալուծում (SVD) is օգտագործվում է մատրիցայի արժեքները պարզեցնելու համար, նվազեցնելով մատրիցը մինչև դրա բաղկացուցիչ մասերը և հեշտացնելով այդ մատրիցով հաշվարկները։ SVD-ն կարող է օգտագործվել ինչպես իրական արժեքի, այնպես էլ բարդ մատրիցների համար, սակայն այս բացատրության նպատակների համար կուսումնասիրենք, թե ինչպես կարելի է քայքայել իրական արժեքների մատրիցը:
Ենթադրենք, որ մենք ունենք իրական արժեքի տվյալներից կազմված մատրիցա, և մեր նպատակն է նվազեցնել սյունակների/հատկանիշների քանակը մատրիցում, որը նման է PCA-ի նպատակին: Ինչպես PCA-ն, այնպես էլ SVD-ն կսեղմի մատրիցայի չափսերը՝ հնարավորինս պահպանելով մատրիցայի փոփոխականությունը: Եթե մենք ցանկանում ենք գործել A մատրիցով, մենք կարող ենք ներկայացնել A մատրիցը որպես երեք այլ մատրիցներ, որոնք կոչվում են U, D և V: Մատրիցը A բաղկացած է սկզբնական x * y տարրերից, մինչդեռ U մատրիցը բաղկացած է X * X տարրերից (դա ուղղանկյուն մատրիցա): V մատրիցը տարբեր ուղղանկյուն մատրից է, որը պարունակում է y * y տարրեր: D մատրիցը պարունակում է x * y տարրերը և այն անկյունագծային մատրից է:
A մատրիցի արժեքները քայքայելու համար մենք պետք է փոխարկենք սկզբնական եզակի մատրիցային արժեքները նոր մատրիցում հայտնաբերված անկյունագծային արժեքներին: Ուղղանկյուն մատրիցների հետ աշխատելիս դրանց հատկությունները չեն փոխվում, եթե դրանք բազմապատկվեն այլ թվերով։ Հետևաբար, մենք կարող ենք մոտավորել A մատրիցը՝ օգտվելով այս հատկությունից: Երբ մենք բազմապատկում ենք ուղղանկյուն մատրիցները V մատրիցի տրանսպոզիայի հետ, ստացվում է մեր սկզբնական A-ին համարժեք մատրից:
Երբ մատրիցը տարրալուծվում է U, D և V մատրիցների, դրանք պարունակում են A մատրիցով հայտնաբերված տվյալները: Այնուամենայնիվ, մատրիցների ամենաձախ սյունակները կպահեն տվյալների մեծ մասը: Մենք կարող ենք վերցնել միայն այս առաջին մի քանի սյունակները և ունենալ A Matrix-ի ներկայացում, որն ունի շատ ավելի քիչ չափեր և տվյալների մեծ մասը A-ի ներսում:
Գծային դիսկրիմինանտ վերլուծություն

Ձախ՝ մատրիցա՝ LDA-ից առաջ, աջ՝ առանցք՝ LDA-ից հետո, այժմ բաժանելի
Գծային տարբերակիչ վերլուծություն (LDA) գործընթաց է, որը տվյալներ է վերցնում բազմաչափ գրաֆիկից և վերանախագծում է այն գծային գրաֆիկի վրա. Դուք կարող եք դա պատկերացնել՝ մտածելով երկչափ գրաֆիկի մասին, որը լցված է երկու տարբեր դասերի պատկանող տվյալների կետերով: Ենթադրենք, որ կետերը ցրված են շուրջը այնպես, որ չի կարող գծվել ոչ մի գիծ, որը կոկիկ կերպով կբաժանի երկու տարբեր դասերը: Այս իրավիճակը կարգավորելու համար 2D գրաֆիկում հայտնաբերված կետերը կարող են կրճատվել մինչև 1D գրաֆիկ (տող): Այս տողը կունենա իր վրա բաշխված բոլոր տվյալների կետերը, և հուսով ենք, որ այն կարելի է բաժանել երկու բաժնի, որոնք ներկայացնում են տվյալների լավագույն հնարավոր տարանջատումը:
LDA իրականացնելիս կան երկու հիմնական նպատակ. Առաջին նպատակը դասերի շեղումները նվազագույնի հասցնելն է, մինչդեռ երկրորդ նպատակը երկու դասերի միջոցների միջև հեռավորությունն առավելագույնի հասցնելն է: Այս նպատակներն իրագործվում են՝ ստեղծելով նոր առանցք, որը գոյություն կունենա 2D գրաֆիկում: Նորաստեղծ առանցքը գործում է երկու դասերը բաժանելու համար՝ հիմնվելով նախկինում նկարագրված նպատակների վրա: Առանցքի ստեղծումից հետո 2D գրաֆիկում հայտնաբերված կետերը տեղադրվում են առանցքի երկայնքով:
Նոր առանցքի երկայնքով սկզբնական կետերը նոր դիրք տեղափոխելու համար անհրաժեշտ է երեք քայլ: Առաջին քայլում առանձին դասերի միջինների միջև հեռավորությունը (դասերի միջև տարբերությունը) օգտագործվում է դասերի բաժանելիությունը հաշվարկելու համար: Երկրորդ քայլում հաշվարկվում է տարբերությունը տարբեր դասերի ներսում՝ որոշելով տվյալ դասի նմուշի և միջինի միջև հեռավորությունը: Վերջնական փուլում ստեղծվում է ավելի ցածր չափի տարածություն, որը առավելագույնի է հասցնում դասերի միջև տարբերությունը:
LDA տեխնիկան հասնում է լավագույն արդյունքների, երբ թիրախային դասերի միջոցները հեռու են միմյանցից: LDA-ն չի կարող արդյունավետորեն առանձնացնել դասերը գծային առանցքով, եթե բաշխումների միջոցները համընկնում են:










