
Mesterséges Intelligencia
ST-NeRF: Összeállítás és szerkesztés videoszintézishez

Egy kínai kutatókonzorcium rendelkezik fejlett olyan technikák, amelyek szerkesztési és kompozíciós képességeket hoznak az elmúlt év egyik legmenőbb képszintézis-kutatási ágazatába, a Neural Radiance Fields-be (NeRF). A rendszer az ST-NeRF (Spatio-Temporal Coherent Neural Radiance Field) nevet viseli.
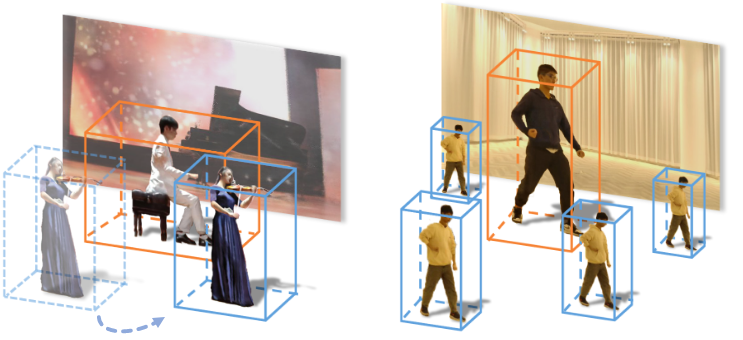
Ami az alábbi képen egy fizikai kameralapnak tűnik, az valójában csak egy felhasználó „görgeti” a 4D-s térben létező videotartalom nézőpontjait. A POV nincs lekötve a videón látható személyek teljesítményéhez, akiknek mozgása 180 fokos sugár bármely részéről megtekinthető.

A videó minden aspektusa diszkréten rögzített elem, amely egy összefüggő jelenetté áll össze, amelyet dinamikusan lehet felfedezni.
Az oldalak szabadon sokszorosíthatók a jeleneten belül, vagy átméretezhetők:

Ezen túlmenően, az egyes aspektusok időbeli viselkedése könnyen megváltoztatható, lelassítható, visszafelé futtatható vagy számos módon manipulálható, ami utat nyit a szűrőarchitektúrákhoz és rendkívül magas szintű értelmezhetőséghez.

Két különálló NeRF aspektus fut különböző sebességgel ugyanabban a jelenetben. Forrás: https://www.youtube.com/watch?v=Wp4HfOwFGP4
Nincs szükség az előadók vagy a környezet rotoszkópos vizsgálatára, vagy arra, hogy az előadók vakon és a tervezett jelenet kontextusától függetlenül hajtsák végre a mozdulataikat. Ehelyett a felvételeket természetesen 16, 180 fokos szögben lefedő videokamerával rögzítik:


A fent ábrázolt három elem, a két ember és a környezet elkülönül egymástól, és csak szemléltetés céljából vázoljuk. Mindegyik kicserélhető, és mindegyik beilleszthető a jelenetbe az egyéni rögzítési idővonal egy korábbi vagy későbbi pontján.
Az ST-NeRF egy innováció a neurális sugárzási mezők kutatásában.NeRF), egy gépi tanulási keretrendszer, amelyben a több nézőpont rögzítése egy navigálható virtuális térbe szintetizálódik kiterjedt képzéssel (bár az egyetlen nézőpont rögzítése is a NeRF kutatás egyik alágazata).

A neurális sugárzási mezők úgy működnek, hogy több rögzítési nézőpontot egyetlen koherens és navigálható 3D térben gyűjtenek össze, a lefedettség becsült és egy neurális hálózat által megjelenített hézagokkal. Ahol videót (állóképek helyett) használnak, a renderelési erőforrások gyakran jelentősek. Forrás: https://www.matthewtancik.com/nerf
A NeRF iránti érdeklődés az elmúlt kilenc hónapban felerősödött, és a Reddit fenntartotta lista A származékos vagy feltáró jellegű NeRF papírok jelenleg hatvan projektet sorol fel.

Csak néhány az eredeti NeRF-papír számos mellékhajtása közül. Forrás: https://crossminds.ai/graphlist/nerf-neural-radiance-fields-ai-research-graph-60708936c8663c4cfa875fc2/
Megfizethető képzés
A cikk a Shanghai Tech University és a kutatók együttműködése DGene digitális technológia, és némi lelkesedéssel fogadták az Open Review-nál.
Az ST-NeRF számos újítást kínál a korábbi kezdeményezésekhez képest az ML-alapú navigálható videoterekben. Nem utolsósorban pedig magas szintű valósághűséget ér el mindössze 16 kamerával. Bár a Facebooké DyNeRF ennél csak két kamerával többet használ, sokkal korlátozottabb navigációs ívet kínál.

Példa a Facebook DyNeRF környezetére, korlátozottabb mozgástérrel és négyzetméterenként több kamerával a jelenet rekonstrukciójához. Forrás: https://neural-3d-video.github.io
Amellett, hogy hiányzik az egyes szempontok szerkesztésének és összeállításának képessége, a DyNeRF különösen drága a számítási erőforrások szempontjából. Ezzel szemben a kínai kutatók azt állítják, hogy az adataik képzési költsége valahol 900 és 3,000 dollár között mozog, szemben a legmodernebb DVDGAN videógenerációs modell 30,000 XNUMX dollárjával és az olyan intenzív rendszerekkel, mint a DyNeRF.
A bírálók azt is megjegyezték, hogy az ST-NeRF jelentős újítást jelent a mozgástanulás folyamatának és a képszintézis folyamatának szétválasztásában. Ez az elválasztás teszi lehetővé a szerkesztést és az összeállítást, a korábbi megközelítések pedig korlátozóak és lineárisak.
Bár a 16 kamera nagyon korlátozott készlet egy ilyen teljes félkör látószögéhez, a kutatók azt remélik, hogy a későbbi munkák során tovább csökkentik ezt a számot proxy-előzetes statikus hátterek és több adatvezérelt jelenetmodellezési megközelítés révén. Azt is remélik, hogy beépítik az újravilágítási lehetőségeket, a legújabb innováció a NeRF kutatásban.
Az ST-NeRF korlátainak kezelése
Azon akadémiai CS-dolgozatokkal összefüggésben, amelyek hajlamosak egy új rendszer tényleges használhatóságát egy eldobható végbekezdésben szemétbe helyezni, még a kutatók által az ST-NeRF-re vonatkozó korlátok is szokatlanok.
Megfigyelik, hogy a rendszer jelenleg nem tudja egyénre szabni és külön megjeleníteni a jelenetben lévő objektumokat, mivel a felvételen szereplő embereket egyéni entitásokra szegmentálják egy olyan rendszeren keresztül, amelyet úgy terveztek, hogy felismerje az embereket, és nem tárgyakat – ez a probléma könnyen megoldhatónak tűnik a YOLO-val és hasonlókkal. keretrendszerek, az emberi videó kivonatának keményebb munkája már elkészült.
Bár a kutatók megjegyzik, hogy jelenleg nem lehet lassított felvételt generálni, úgy tűnik, kevés akadálya van ennek megvalósításának a keretinterpoláció meglévő újításaival, mint pl. DAIN és a RIFE.
Mint minden NeRF-megvalósítás, és a számítógépes látáskutatás sok más ágazatában, az ST-NeRF is meghibásodhat súlyos elzáródás esetén, amikor az alanyt átmenetileg kitakarja egy másik személy vagy egy tárgy, és nehéz lehet folyamatosan követni vagy pontosan meghatározni. utána visszaszerezni. Akárcsak máshol, ennek a nehézségnek az upstream megoldásokra kell várnia. Mindeközben a kutatók elismerik, hogy ezekben az eldugult keretekben manuális beavatkozásra van szükség.
Végül a kutatók megfigyelik, hogy az emberi szegmentálási eljárások jelenleg a színkülönbségeken alapulnak, ami két ember nem szándékos összeállításához vezethet egy szegmentálási blokkba – ami nem korlátozódik az ST-NeRF-re, hanem a használt könyvtárra jellemző, és amely talán megoldható lenne optikai áramlásanalízissel és más feltörekvő technikákkal.
Első megjelenés: 7. május 2021.















