कृत्रिम बुद्धिमत्ता
एआई तर्क का विकास: श्रृंखला से पुनरावृत्ति और स्तरीय रणनीतियों तक
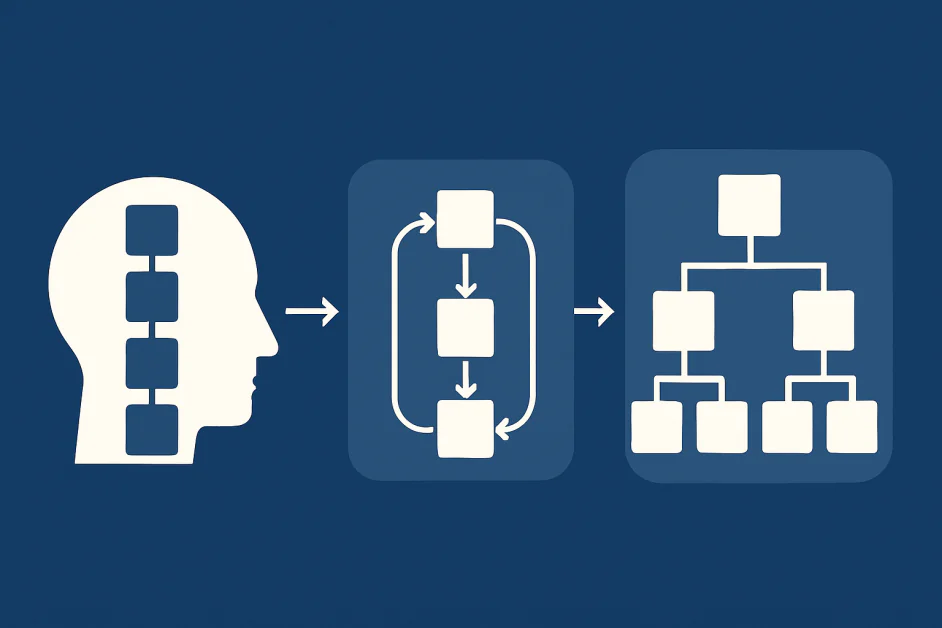
पिछले कुछ वर्षों में, चेन-ऑफ-थॉट प्रॉम्प्टिंग बड़े भाषा मॉडल में तर्क के लिए केंद्रीय विधि बन गई है। मॉडल को “ज़ोर से सोचने” के लिए प्रोत्साहित करके, शोधकर्ताओं ने पाया कि चरण-दर-चरण स्पष्टीकरण गणित और तर्क जैसे क्षेत्रों में सटीकता में सुधार करते हैं। हालांकि, जैसे ही कार्य अधिक जटिल हो जाते हैं, सीओटी की सीमाएं स्पष्ट हो जाती हैं। सीओटी की सावधानी से चुने गए तर्क के उदाहरणों पर निर्भरता इसे उन कार्यों को संभालने में मुश्किल बना देती है जो या तो बहुत सरल हैं या उन उदाहरणों से अधिक कठिन हैं। जबकि सीओटी ने भाषा मॉडल में संरचित सोच की शुरुआत की, क्षेत्र अब जटिल, बहु-चरण समस्याओं को संभालने में सक्षम नई दृष्टिकोणों की मांग करता है जिनकी जटिलता भिन्न होती है। इसके परिणामस्वरूप, शोधकर्ता अब पुनरावृत्ति और स्तरीय तर्क जैसी नई रणनीतियों का अन्वेषण कर रहे हैं। ये तरीके तर्क को गहरा, अधिक कुशल और अधिक मजबूत बनाने का उद्देश्य रखते हैं। यह लेख सीओटी की सीमाओं, सीओटी के विकास, और एआई तर्क को स्केल करने के लिए अनुप्रयोगों, चुनौतियों और भविष्य के दिशानिर्देशों की खोज करता है।
चेन-ऑफ-थॉट की सीमाएं
सीओटी तर्क ने मॉडल को जटिल कार्यों को छोटे चरणों में तोड़ने में मदद की। यह क्षमता न केवल बेंचमार्क परिणामों में सुधार की है गणित प्रतियोगिताओं, तर्क पजल्स, और प्रोग्रामिंग कार्यों में बल्कि मध्यवर्ती चरणों को उजागर करके कुछ पारदर्शिता भी प्रदान करती है। इसके बावजूद, हालांकि, सीओटी अपनी चुनौतियों के बिना नहीं है। शोध से पता चलता है कि सीओटी उन समस्याओं पर सबसे अच्छा काम करता है जिन्हें प्रतीकात्मक तर्क या सटीक गणना की आवश्यकता होती है। हालांकि, खुले प्रश्नों के लिए, सामान्य ज्ञान तर्क, या तथ्यात्मक रिकॉल के लिए, यह अक्सर थोड़ा या यहां तक कि सटीकता को कम कर देता है।
सीओटी मूल रूप से रेखीय है। मॉडल एक एकल अनुक्रम उत्पन्न करता है जो एक उत्तर की ओर ले जाता है। यह छोटे, स्पष्ट रूप से परिभाषित समस्याओं के लिए अच्छा काम करता है, लेकिन तब संघर्ष करता है जब कार्यों को गहरी खोज की आवश्यकता होती है। इसके अलावा, जटिल तर्क अक्सर शाखाओं, पीछे की ओर जाने और मान्यताओं को फिर से देखने में शामिल होता है। एक एकल रेखीय श्रृंखला इसे पकड़ नहीं सकती। यदि मॉडल एक प्रारंभिक त्रुटि करता है, तो सभी बाद के चरण ढह जाते हैं। यहां तक कि जब तर्क सही होता है, तो रेखीय आउटपुट नई जानकारी के अनुकूल नहीं हो सकते हैं या पहले की मान्यताओं की जांच नहीं कर सकते हैं। वास्तविक दुनिया तर्क को लचीलापन की आवश्यकता होती है जो सीओटी प्रदान नहीं करता है।
शोधकर्ता स्केलिंग समस्याओं को भी उजागर करते हैं। जैसे ही मॉडल कठिन कार्यों का सामना करते हैं, श्रृंखलाएं लंबी और अधिक नाजुक हो जाती हैं। कई श्रृंखलाओं का नमूना लेना मदद कर सकता है, लेकिन यह जल्द ही अकुशल हो जाता है। प्रश्न यह है कि संकीर्ण, एकल-पथ तर्क से अधिक मजबूत रणनीतियों में कैसे आगे बढ़ें।
पुनरावृत्ति तर्क एक अगला कदम के रूप में
एक आशाजनक दिशा पुनरावृत्ति है। एक ही पास में एक अंतिम उत्तर का उत्पादन करने के बजाय, मॉडल तर्क, मूल्यांकन और परिष्करण के चक्रों में संलग्न होता है। यह उन लोगों की तरह है जो कठिन समस्याओं को हल करने के लिए पहले एक समाधान का मसौदा तैयार करते हैं, इसे जांचते हैं, कमजोरियों की पहचान करते हैं और इसे चरणबद्ध तरीके से सुधारते हैं।
पुनरावृत्ति विधियों को मॉडल को त्रुटियों से उबरने और वैकल्पिक समाधानों का अन्वेषण करने की अनुमति देती हैं। वे एक प्रतिक्रिया लूप बनाते हैं जहां मॉडल अपने स्वयं के तर्क की आलोचना करता है, या जहां कई मॉडल एक दूसरे की आलोचना करते हैं। एक शक्तिशाली विचार स्व-संगति है। एक श्रृंखला विचार पर भरोसा करने के बजाय, मॉडल कई तर्क मार्गों का नमूना लेता है और फिर सबसे सामान्य उत्तर चुनता है। यह एक छात्र की तरह है जो एक उत्तर पर विश्वास करने से पहले समस्या को कई तरीकों से आजमाता है। शोध से पता चला है कि कई तर्क मार्गों को एकत्रित करने से विश्वसनीयता में सुधार होता है। अधिक हाल के कार्य इस विचार को संरचित पुनरावृत्ति में विस्तारित करते हैं जहां आउटपुट बार-बार जांचे, सुधारे और विस्तारित किए जाते हैं।
यह क्षमता मॉडल को बाहरी उपकरणों का उपयोग करने की भी अनुमति देती है। पुनरावृत्ति इसे आसान बनाती है कि खोज इंजन, सॉल्वर, या मेमोरी सिस्टम को लूप में एकीकृत किया जाए। एक उत्तर पर भरोसा करने के बजाय, मॉडल बाहरी संसाधनों को पूछताछ कर सकता है, अपने तर्क को फिर से देख सकता है और अपने चरणों को संशोधित कर सकता है। पुनरावृत्ति तर्क को एक स्थिर श्रृंखला के बजाय एक गतिशील प्रक्रिया में बदल देती है।
जटिलता के लिए स्तरीय दृष्टिकोण
पुनरावृत्ति अकेले पर्याप्त नहीं है जब कार्य बहुत बड़े हो जाते हैं। उन समस्याओं के लिए जिन्हें लंबे क्षितिज या बहु-चरण योजना की आवश्यकता होती है, स्तरीयता आवश्यक हो जाती है। मानव स्तरीय तर्क का उपयोग करते हैं सभी समय। हम कार्यों को उप-समस्याओं में तोड़ते हैं, लक्ष्य निर्धारित करते हैं और उन्हें संरचित परतों में काम करते हैं। मॉडल को भी इसी क्षमता की आवश्यकता है।
स्तरीय विधियों मॉडल को एक कार्य को छोटे चरणों में तोड़ने और उन्हें समानांतर या क्रम में हल करने की अनुमति देती हैं। विचार कार्यक्रम और विचार के पेड़ पर शोध इस दिशा को उजागर करता है। एक समतल श्रृंखला के बजाय, तर्क एक पेड़ या ग्राफ के रूप में व्यवस्थित किया जाता है जहां कई मार्ग अन्वेषण किए जा सकते हैं और छंटनी की जा सकती है। यह विभिन्न रणनीतियों के माध्यम से खोज करने और सबसे आशाजनक एक का चयन करने की अनुमति देता है। इस दिशा में, एक नई विकास विचार का जंगल फ्रेमवर्क है, जो एक ही समय में कई तर्क “पेड़” लॉन्च करता है और उन पर सहमति और त्रुटि-सुधार का उपयोग करता है। प्रत्येक पेड़ एक अलग मार्ग का अन्वेषण कर सकता है; जो पेड़ आशाजनक नहीं लगते हैं उन्हें छंटनी दी जाती है, जबकि स्व-सुधार तंत्र मॉडल को किसी भी शाखा में त्रुटियों का पता लगाने और उन्हें ठीक करने की अनुमति देते हैं। सभी पेड़ों से वोटों को जोड़कर, मॉडल एक सामूहिक निर्णय लेता है।
स्तरीयता भी समन्वय को सक्षम बनाती है। बड़े कार्यों को उन एजेंटों के पास वितरित किया जा सकता है जो समस्या के विभिन्न भागों को संभालते हैं। एक एजेंट योजना पर ध्यान केंद्रित कर सकता है, दूसरा गणना पर, और दूसरा सत्यापन पर। परिणामों को फिर एक सुसंगत एकल समाधान में एकीकृत किया जा सकता है। बहु-एजेंट तर्क में प्रारंभिक प्रयोग सुझाव देते हैं कि ऐसा श्रम विभाजन एकल-श्रृंखला विधियों को बेहतर बना सकता है।
सत्यापन और विश्वसनीयता
पुनरावृत्ति और स्तरीय रणनीतियों की एक और ताकत यह है कि वे स्वाभाविक रूप से सत्यापन की अनुमति देती हैं। चेन-ऑफ-थॉट तर्क चरणों को उजागर करता है, लेकिन यह उनकी सटीकता की गारंटी नहीं देता है। पुनरावृत्ति लूप के साथ, मॉडल अपने स्वयं के चरणों की जांच कर सकता है या उन्हें अन्य मॉडल द्वारा जांचा जा सकता है। स्तरीयता के साथ, विभिन्न स्तरों को स्वतंत्र रूप से सत्यापित किया जा सकता है।
यह संरचित मूल्यांकन पाइपलाइनों के लिए दरवाजा खोलता है। उदाहरण के लिए, एक मॉडल निचले स्तर पर उम्मीदवार समाधान उत्पन्न कर सकता है, जबकि एक उच्च-स्तरीय नियंत्रक उन्हें चुनता है या परिष्कृत करता है। या एक बाहरी सत्यापनकर्ता आउटपुट को स्वीकार करने से पहले उन्हें प्रतिबंधों के खिलाफ परीक्षण कर सकता है। ये तंत्र तर्क को कम भंगुर और अधिक विश्वसनीय बनाते हैं।
सत्यापन न केवल सटीकता के बारे में है। यह व्याख्या में भी सुधार करता है। तर्क को परतों या पुनरावृत्ति में व्यवस्थित करके, शोधकर्ता अधिक आसानी से देख सकते हैं कि विफलताएं कहां होती हैं। यह दोनों डिबगिंग और संरेखण का समर्थन करता है, डेवलपर्स को यह नियंत्रित करने में अधिक नियंत्रण देता है कि मॉडल कैसे तर्क देते हैं।
अनुप्रयोग
उन्नत तर्क रणनीतियां पहले से ही विभिन्न क्षेत्रों में उपयोग की जा रही हैं। विज्ञान में, वे उन्नत गणित और यहां तक कि शोध प्रस्तावों के मसौदे तैयार करने में समस्या-समाधान का समर्थन करते हैं।
प्रोग्रामिंग में, मॉडल अब प्रतिस्पर्धी कोडिंग, डिबगिंग और पूर्ण सॉफ्टवेयर विकास चक्र में अच्छा प्रदर्शन करते हैं।
कानूनी और व्यावसायिक क्षेत्र जटिल अनुबंध विश्लेषण और रणनीतिक योजना से लाभान्वित होते हैं। एजेंटिक एआई सिस्टम तर्क को उपकरणों के साथ जोड़ती है, जो एपीआई, डेटाबेस और वेब के माध्यम से बहु-चरण संचालन का प्रबंधन करती है। शिक्षा में, ट्यूटरिंग सिस्टम चरण-दर-चरण अवधारणाओं की व्याख्या कर सकते हैं और व्यक्तिगत मार्गदर्शन प्रदान कर सकते हैं।
चुनौतियां और खुले प्रश्न
पुनरावृत्ति और स्तरीय तरीकों के वादे के बावजूद, अभी भी कई चुनौतियों का सामना करना है। एक कुशलता है। पुनरावृत्ति लूप और पेड़ खोजें गणनात्मक रूप से महंगी हो सकती हैं। पूर्णता के साथ गति का संतुलन एक खुला समस्या है।
एक अन्य चुनौती नियंत्रण है। यह सुनिश्चित करना कि मॉडल उपयोगी रणनीतियों का पालन करते हैं और अकुशल लूप में नहीं जाते हैं, कठिन है। शोधकर्ता विधियों का अन्वेषण कर रहे हैं तर्क को सूर्य सिद्धांतों, योजना अल्गोरिदम या सीखे हुए नियंत्रकों के साथ मार्गदर्शन करने के लिए, लेकिन क्षेत्र अभी भी युवा है।
मूल्यांकन भी एक खुला प्रश्न है। पारंपरिक सटीकता बेंचमार्क केवल परिणामों को पकड़ते हैं, तर्क प्रक्रियाओं की गुणवत्ता नहीं। तर्क रणनीतियों की मजबूती, अनुकूलनशीलता और पारदर्शिता को मापने के लिए नए मूल्यांकन ढांचे की आवश्यकता है।
अंत में, संरेखण चिंताएं हैं। पुनरावृत्ति और स्तरीय तर्क मॉडल की ताकत और कमजोरियों दोनों को बढ़ा सकते हैं। जबकि वे तर्क को अधिक विश्वसनीय बना सकते हैं, वे यह भी अधिक कठिन बना देते हैं कि मॉडल खुले संदर्भों में कैसे व्यवहार करेंगे। सावधानीपूर्वक डिजाइन और पर्यवेक्षण आवश्यक है ताकि नए जोखिमों से बचा जा सके।
नीचे की रेखा
चेन-ऑफ-थॉट ने एआई में संरचित तर्क का दरवाजा खोल दिया, लेकिन इसकी रेखीय सीमाएं स्पष्ट हैं। भविष्य पुनरावृत्ति और स्तरीय रणनीतियों में निहित है जो तर्क को अधिक अनुकूल, सत्यापन योग्य और स्केलेबल बनाती हैं। चक्रों का उपयोग करके और परतों में समस्या समाधान करके, एआई श्रृंखला से गतिशील तर्क प्रणालियों में जा सकता है जो वास्तविक दुनिया की जटिलता को संभालने में सक्षम हैं।












