Cybersécurité
Pourquoi les attaques d’images adverses ne sont pas une plaisanterie
Attaquer les systèmes de reconnaissance d’images avec des images adverses soigneusement conçues a été considéré comme une preuve de concept amusante mais trivial au cours des cinq dernières années. Cependant, de nouvelles recherches en Australie suggèrent que l’utilisation occasionnelle de jeux de données d’images très populaires pour les projets commerciaux d’IA pourrait créer un nouveau problème de sécurité persistant.
Pendant quelques années maintenant, un groupe d’universitaires de l’Université d’Adélaïde tente d’expliquer quelque chose d’important sur l’avenir des systèmes de reconnaissance d’images basés sur l’IA.
C’est quelque chose qui serait difficile (et très coûteux) à résoudre actuellement, et qui serait inconcevablement coûteux à remédier une fois que les tendances actuelles dans la recherche sur la reconnaissance d’images auront été entièrement développées en déploiements commercialisés et industrialisés dans 5-10 ans.
Avant de commencer, jetons un coup d’œil à une fleur classée comme le président Barack Obama, l’une des six vidéos que l’équipe a publiées sur la page du projet :
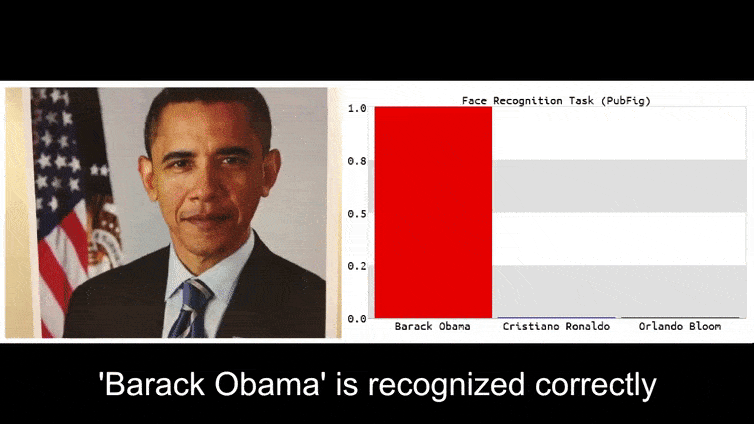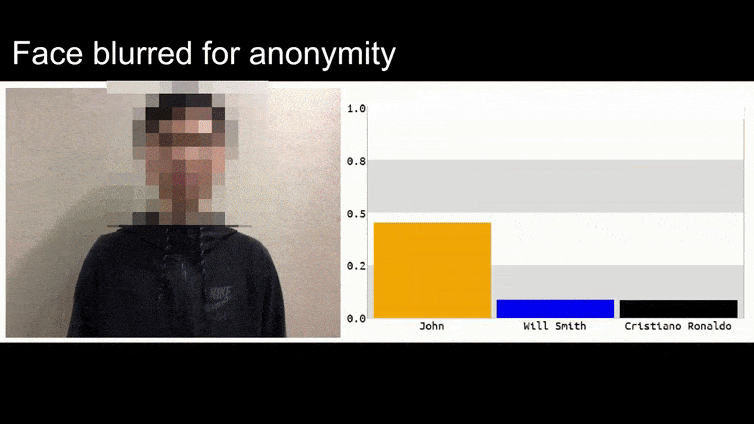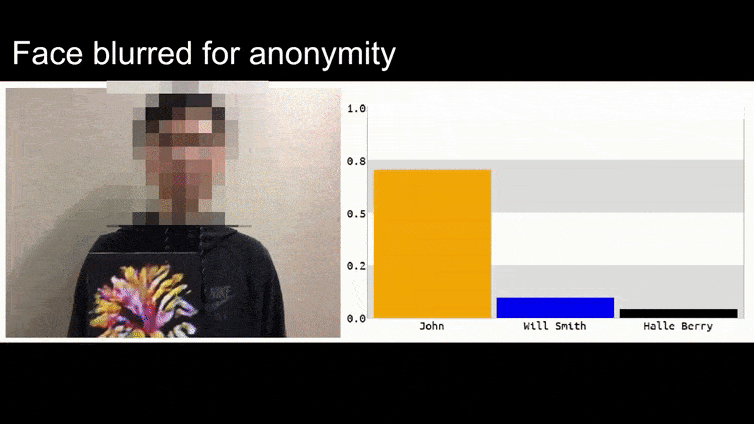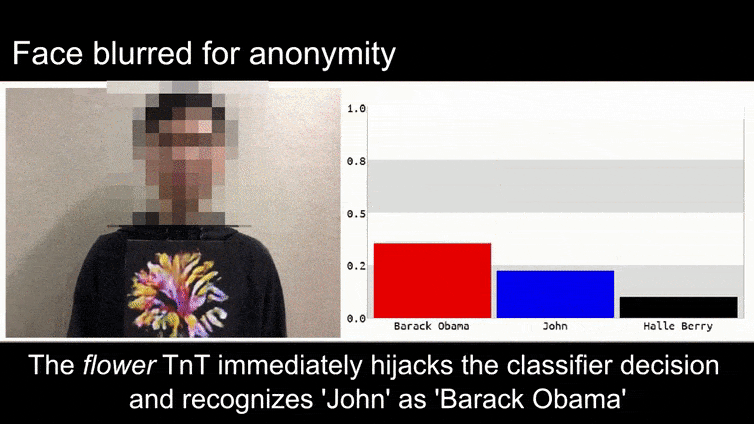
Source : https://www.youtube.com/watch?v=Klepca1Ny3c
Dans l’image ci-dessus, un système de reconnaissance faciale qui sait clairement reconnaître Barack Obama est trompé avec une certitude de 80 % qu’un homme anonyme tenant une image adverse craftée d’une fleur est également Barack Obama. Le système ne se soucie même pas que le « faux visage » est sur la poitrine du sujet, et non sur ses épaules.
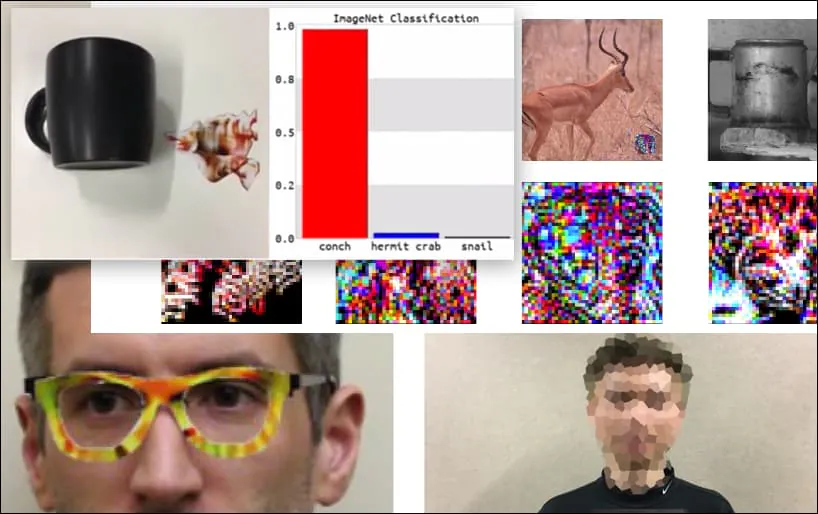
Bien que les chercheurs aient réussi à accomplir ce type de capture d’identité en générant une image cohérente (une fleur) au lieu du simple bruit aléatoire habituel, il semble que des exploits farces comme celui-ci apparaissent régulièrement dans la recherche sur la sécurité de la vision par ordinateur. Par exemple, ces lunettes à motifs étranges qui ont pu tromper la reconnaissance faciale en 2016, ou des images adverses spécialement conçues qui tentent de réécrire les panneaux de signalisation routière.
Si vous êtes intéressé, le modèle de réseau de neurones convolutifs (CNN) attaqué dans l’exemple ci-dessus est VGGFace (VGG-16), formé sur le jeu de données PubFig de l’Université de Columbia. D’autres échantillons d’attaque développés par les chercheurs ont utilisé différents ressources dans différentes combinaisons.

Un clavier est reclassé comme un conque, dans un modèle WideResNet50 sur ImageNet. Les chercheurs ont également veillé à ce que le modèle n’ait pas de biais en faveur des conques. Voir la vidéo complète pour des démonstrations étendues et supplémentaires à https://www.youtube.com/watch?v=dhTTjjrxIcU
La reconnaissance d’images en tant que vecteur d’attaque émergent
Les nombreuses attaques impressionnantes que les chercheurs détaillent et illustrent ne sont pas des critiques de jeux de données ou d’architectures d’apprentissage automatique spécifiques qui les utilisent. Ni ne peuvent-elles être facilement défendues en changeant de jeux de données ou de modèles, en réentraînant des modèles, ou par d’autres « remèdes simples » qui amènent les praticiens de l’apprentissage automatique à se moquer de démonstrations sporadiques de ce type de tromperie.
Plutôt, les exploits de l’équipe d’Adélaïde exemplifient une faiblesse centrale dans l’ensemble de l’architecture actuelle du développement de la reconnaissance d’images basée sur l’IA ; une faiblesse qui pourrait exposer de nombreux systèmes de reconnaissance d’images futurs à une manipulation facile par les attaquants, et placer les mesures de défense ultérieures sur la défensive.
Imaginez les dernières images d’attaque adverses (comme la fleur ci-dessus) étant ajoutées comme « exploits de zero-day » aux systèmes de sécurité du futur, tout comme les frameworks actuels anti-malware et antivirus mettent à jour leurs définitions de virus chaque jour.
Le potentiel d’attaques d’images adverses nouvelles serait inépuisable, car l’architecture fondamentale du système n’a pas anticipé les problèmes en aval, comme cela s’est produit avec Internet, le bug du millénaire et la tour de Pise penchée.
De quelle manière, alors, préparons-nous le terrain pour cela ?
Obtenir les données pour une attaque
Des images adverses telles que l’exemple de « fleur » ci-dessus sont générées en ayant accès aux jeux de données qui ont formé les modèles d’ordinateur. Vous n’avez pas besoin d’un « accès privilégié » aux données de formation (ou aux architectures de modèle), puisque les jeux de données les plus populaires (et de nombreux modèles formés) sont largement disponibles dans un torrent robuste et constamment mis à jour.
Par exemple, le géant de la vision par ordinateur, ImageNet, est disponible sur Torrent dans toutes ses nombreuses itérations, en contournant ses restrictions habituelles , et en rendant disponibles des éléments secondaires importants, tels que les ensembles de validation.

Source : https://academictorrents.com
Si vous avez les données, vous pouvez (comme l’observe l’équipe d’Adélaïde) « rétro-ingénier » efficacement n’importe quel jeu de données populaire, tel que CityScapes ou CIFAR.
Dans le cas de PubFig, le jeu de données qui a permis la « fleur d’Obama » dans l’exemple précédent, l’Université de Columbia a abordé une tendance croissante en matière de problèmes de droits d’auteur autour de la redistribution de jeux de données d’images en instruisant les chercheurs sur la façon de reproduire le jeu de données via des liens curatifs, plutôt que de rendre la compilation directement disponible, en observant ‘Cela semble être la façon dont d’autres grandes bases de données Web semblent évoluer’.
Dans la plupart des cas, ce n’est pas nécessaire : Kaggle estime que les dix jeux de données d’images les plus populaires en vision par ordinateur sont : CIFAR-10 et CIFAR-100 (tous deux téléchargeables directement) ; CALTECH-101 et 256 (tous deux disponibles, et actuellement disponibles sous forme de torrents) ; MNIST (officiellement disponible, également sur les torrents) ; ImageNet (voir ci-dessus) ; Pascal VOC (disponible, également sur les torrents) ; MS COCO (disponible, et sur les torrents) ; Sports-1M (disponible) ; et YouTube-8M (disponible).
Cette disponibilité est également représentative de la gamme plus large de jeux de données d’images de vision par ordinateur disponibles, car l’obscurité est la mort dans une culture de développement open source « publier ou périr ».
Dans tous les cas, la rareté de jeux de données gérables, le coût élevé du développement d’ensembles d’images, la dépendance à l’égard des « anciens favoris » et la tendance à simplement adapter les anciens jeux de données exacerbent tous le problème décrit dans le nouveau document d’Adélaïde.
Critiques typiques des méthodes d’attaque d’images adverses
La critique la plus fréquente et la plus persistante des ingénieurs en apprentissage automatique contre l’efficacité de la dernière technique d’attaque d’images adverses est que l’attaque est spécifique à un jeu de données particulier, à un modèle particulier, ou aux deux ; qu’elle n’est pas « généralisable » à d’autres systèmes ; et, par conséquent, ne représente qu’une menace triviale.
La deuxième critique la plus fréquente est que l’attaque d’image adverse est ‘white box’, ce qui signifie que vous auriez besoin d’un accès direct à l’environnement de formation ou aux données. C’est en effet un scénario peu probable, dans la plupart des cas – par exemple, si vous vouliez exploiter le processus de formation pour les systèmes de reconnaissance faciale de la police métropolitaine de Londres, vous devriez pirater votre chemin dans NEC, soit avec une console, soit avec une hache.
L’ADN à long terme des jeux de données de vision par ordinateur populaires
En ce qui concerne la première critique, nous devrions considérer non seulement qu’un petit nombre de jeux de données de vision par ordinateur dominent l’industrie par secteur d’année en année (c’est-à-dire ImageNet pour plusieurs types d’objets, CityScapes pour les scènes de conduite et FFHQ pour la reconnaissance faciale) ; mais également que, en tant que données d’images annotées simples, ils sont « agnostiques de plate-forme » et très transférables.
En fonction de ses capacités, n’importe quelle architecture de formation de vision par ordinateur trouvera quelques fonctionnalités d’objets et de classes dans le jeu de données ImageNet. Certaines architectures peuvent trouver plus de fonctionnalités que d’autres, ou établir des connexions plus utiles que d’autres, mais toutes devraient trouver au moins les fonctionnalités de niveau le plus élevé :

Données ImageNet, avec le nombre minimum de bonnes identifications – fonctionnalités de « niveau élevé ».
Ce sont ces fonctionnalités de « niveau élevé » qui distinguent et « impriment » un jeu de données, et qui sont les « crochets » fiables sur lesquels accrocher une méthodologie d’attaque d’images adverses à long terme qui peut chevaucher différents systèmes et grandir en tandem avec le « vieux » jeu de données à mesure que celui-ci est perpétué dans de nouvelles recherches et produits.
Une architecture plus sophistiquée produira des identifications plus précises et plus granulaires, des fonctionnalités et des classes :

Cependant, plus un générateur d’attaque adverse repose sur ces fonctionnalités inférieures (c’est-à-dire « jeune homme caucasien » au lieu de « visage »), moins il sera efficace dans les architectures de chevauchement ou ultérieures qui utilisent des versions différentes du jeu de données d’origine – telles qu’un sous-ensemble ou un ensemble filtré, où de nombreuses images d’origine du jeu de données complet ne sont pas présentes :

Attaques adverses sur des modèles « zéroés », pré-formés
Que se passe-t-il si vous téléchargez simplement un modèle pré-formé qui a été formé à l’origine sur un jeu de données très populaire, et que vous lui donnez de nouvelles données ?
Le modèle a déjà été formé sur (par exemple) ImageNet, et tout ce qui reste, ce sont les poids, qui peuvent avoir pris des semaines ou des mois à former, et sont maintenant prêts à vous aider à identifier des objets similaires à ceux qui existaient dans les données d’origine (maintenant absentes).

Avec les données d’origine supprimées de l’architecture de formation, ce qui reste, c’est la « prédisposition » du modèle pour classer les objets de la manière dont il a appris à le faire à l’origine, ce qui causera essentiellement de nombreuses « signatures » d’origine à se reformer et à redevenir vulnérables une fois de plus aux mêmes anciennes méthodes d’attaque d’images adverses.
Ces poids sont précieux. Sans les données ou les poids, vous avez essentiellement une architecture vide sans données. Vous devrez l’entraîner à partir de zéro, au grand coût du temps et des ressources de calcul, comme l’ont fait les auteurs originaux (probablement sur un matériel plus puissant et avec un budget plus élevé que celui dont vous disposez).
Le problème est que les poids sont déjà bien formés et résistants. Bien qu’ils s’adapteront quelque peu lors de la formation, ils se comporteront de manière similaire sur vos nouvelles données qu’ils l’ont fait sur les données d’origine, produisant des fonctionnalités de signature que un système d’attaque adverse peut se connecter à nouveau.
À long terme, cela préserve également l’« ADN » des jeux de données de vision par ordinateur qui ont douze ans ou plus, et qui peuvent avoir traversé une évolution notable des efforts open source à des déploiements commercialisés – même lorsque les données d’origine ont été complètement rejetées au début du projet. Certains de ces déploiements commerciaux peuvent ne pas se produire pendant des années encore.
Pas de boîte blanche nécessaire
En ce qui concerne la deuxième critique courante des systèmes d’attaque d’images adverses, les auteurs du nouveau document ont constaté que leur capacité à tromper les systèmes de reconnaissance avec des images craftées de fleurs est très transférable à travers plusieurs architectures.
Bien qu’ils observent que leur méthode « Universal NaTuralistic adversarial paTches » (TnT) est la première à utiliser des images reconnaissables (plutôt que du bruit de perturbation aléatoire) pour tromper les systèmes de reconnaissance d’images, les auteurs déclarent également :
‘[TnTs] sont efficaces contre de multiples classificateurs d’état de l’art allant du WideResNet50 largement utilisé dans la tâche de reconnaissance visuelle à grande échelle du jeu de données ImageNet au VGG-face modèles dans la tâche de reconnaissance faciale du jeu de données PubFig dans les attaques ciblées et non ciblées.
‘TnTs peuvent posséder : i) le naturalisme réalisable [avec] les déclencheurs utilisés dans les méthodes d’attaque de Trojan ; et ii) la généralisation et la transférabilité des exemples adverses à d’autres réseaux.
‘Cela soulève des préoccupations en matière de sécurité et de sûreté concernant les DNN déjà déployés, ainsi que les futurs déploiements de DNN où les attaquants peuvent utiliser des patchs d’objets naturels peu visibles pour induire les systèmes de neurones en erreur sans modifier le modèle et risquer la découverte.’
Les auteurs suggèrent que les contre-mesures conventionnelles, telles que la dégradation de l’exactitude propre d’un réseau, pourraient théoriquement fournir une certaine défense contre les patchs TnT, mais que ‘TnTs peuvent toujours contourner ces méthodes de défense SOTA prouvables avec la plupart des systèmes de défense qui réalisent 0 % de robustesse’.
Des solutions possibles incluent l’apprentissage fédéré, où la provenance des images contributives est protégée, et de nouvelles approches qui pourraient directement « chiffrer » les données au moment de la formation, comme celle récemment suggérée par l’Université d’aéronautique et d’astronautique de Nankin.
Même dans ces cas, il serait important de se former sur des données d’images réellement nouvelles – à ce stade, les images et les annotations associées dans le petit groupe des jeux de données de vision par ordinateur les plus populaires sont si profondément ancrées dans les cycles de développement du monde entier qu’elles ressemblent plus à des logiciels qu’à des données ; des logiciels qui n’ont souvent pas été mis à jour de manière notable depuis des années.
Conclusion
Les attaques d’images adverses sont rendues possibles non seulement par les pratiques open source de l’apprentissage automatique, mais également par une culture de développement d’IA d’entreprise qui est motivée à réutiliser des jeux de données de vision par ordinateur bien établis pour plusieurs raisons : ils ont déjà prouvé leur efficacité ; ils sont beaucoup moins chers que « partir de zéro » ; et ils sont maintenus et mis à jour par des esprits et des organisations de pointe à travers l’académie et l’industrie, à des niveaux de financement et de dotation en personnel qui seraient difficiles pour une seule entreprise à reproduire.
En outre, dans de nombreux cas où les données ne sont pas originales (comme CityScapes), les images ont été collectées avant les récentes controverses autour des pratiques de collecte et de confidentialité des données, laissant ces anciens jeux de données dans une sorte de purgatoire semi-légal qui peut ressembler à un « havre de paix » du point de vue d’une entreprise.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems est co-écrit par Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe de l’Université d’Adélaïde, ainsi que Shiqing Ma du Département d’informatique de l’Université Rutgers.
Mis à jour le 1er décembre 2021, 7h06 GMT+2 – correction d’une faute d’orthographe.












