IA 101
Qu’est-ce que les CNN (Convolutional Neural Networks) ?
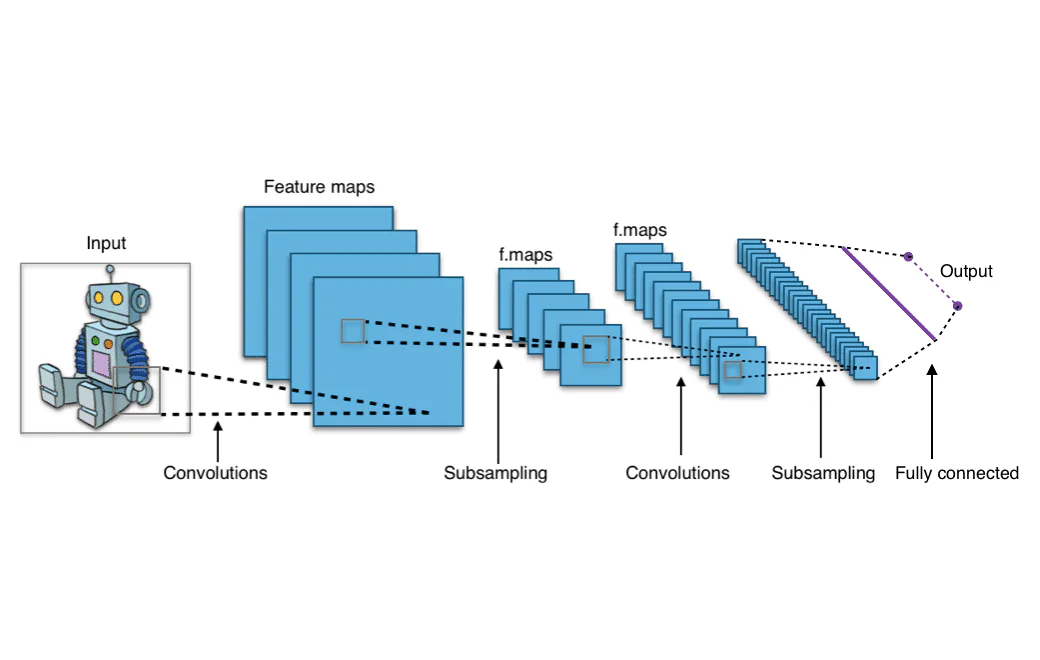
Vous vous êtes peut-être demandé comment Facebook ou Instagram peut reconnaître automatiquement les visages dans une image, ou comment Google vous permet de rechercher des photos similaires sur le web en téléchargeant simplement une photo. Ces fonctionnalités sont des exemples de vision par ordinateur, et elles sont alimentées par des réseaux de neurones convolutionnels (CNN). Mais qu’est-ce que les réseaux de neurones convolutionnels exactement ? Plongeons dans l’architecture d’un CNN et comprenons comment ils fonctionnent.
Qu’est-ce que les réseaux de neurones ?
Avant de commencer à parler des réseaux de neurones convolutionnels, prenons un moment pour définir les réseaux de neurones classiques. Il y a un autre article sur le sujet des réseaux de neurones disponible, nous n’allons donc pas nous y attarder ici. Cependant, pour les définir brièvement, ce sont des modèles de calcul inspirés du cerveau humain. Un réseau de neurones fonctionne en prenant des données et en les manipulant en ajustant des “poids”, qui sont des hypothèses sur la façon dont les fonctionnalités d’entrée sont liées les unes aux autres et à la classe de l’objet. Au fur et à mesure que le réseau est formé, les valeurs des poids sont ajustées et elles convergeront probablement vers des poids qui capturent avec précision les relations entre les fonctionnalités.
C’est ainsi qu’un réseau de neurones feed-forward fonctionne, et les CNN sont composés de deux moitiés : un réseau de neurones feed-forward et un groupe de couches convolutionnelles.
Qu’est-ce que les réseaux de neurones convolutionnels (CNN) ?
Qu’est-ce que les “convolutions” qui se produisent dans un réseau de neurones convolutionnel ? Une convolution est une opération mathématique qui crée un ensemble de poids, créant essentiellement une représentation de parties de l’image. Cet ensemble de poids est appelé un noyau ou un filtre. Le filtre créé est plus petit que l’image d’entrée complète, ne couvrant qu’une sous-section de l’image. Les valeurs du filtre sont multipliées avec les valeurs de l’image. Le filtre est ensuite déplacé pour former une représentation d’une nouvelle partie de l’image, et le processus est répété jusqu’à ce que l’image entière ait été couverte.
Une autre façon de penser à cela est d’imaginer un mur de briques, avec les briques représentant les pixels de l’image d’entrée. Une “fenêtre” est déplacée le long du mur, qui est le filtre. Les briques visibles à travers la fenêtre sont les pixels ayant leur valeur multipliée par les valeurs à l’intérieur du filtre. Pour cette raison, cette méthode de création de poids avec un filtre est souvent appelée la technique des “fenêtres glissantes”.
La sortie des filtres déplacés autour de l’image d’entrée complète est un tableau bidimensionnel représentant l’image entière. Ce tableau est appelé une “carte de fonctionnalités”.
Pourquoi les convolutions sont-elles essentielles
Quel est l’objectif de la création de convolutions ? Les convolutions sont nécessaires car un réseau de neurones doit être capable d’interpréter les pixels d’une image comme des valeurs numériques. La fonction des couches convolutionnelles est de convertir l’image en valeurs numériques que le réseau de neurones peut interpréter et extraire des modèles pertinents. Le travail des filtres dans le réseau convolutionnel est de créer un tableau bidimensionnel de valeurs qui peut être transmis aux couches ultérieures du réseau de neurones, celles qui apprendront les modèles de l’image.
Filtres et canaux
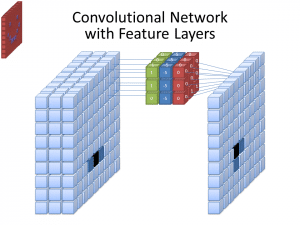
Photo : cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
Les CNN n’utilisent pas un seul filtre pour apprendre des modèles à partir des images d’entrée. Plusieurs filtres sont utilisés, car les différents tableaux créés par les différents filtres conduisent à une représentation plus complexe et riche de l’image d’entrée. Les nombres de filtres courants pour les CNN sont 32, 64, 128 et 512. Plus il y a de filtres, plus le CNN a d’opportunités pour examiner les données d’entrée et en apprendre.
Un CNN analyse les différences de valeurs de pixels pour déterminer les limites des objets. Dans une image en niveaux de gris, le CNN ne regarderait que les différences entre le noir et le blanc, les termes clairs et sombres. Lorsque les images sont des images en couleur, non seulement le CNN prend en compte les termes clairs et sombres, mais il doit également prendre en compte les trois canaux de couleur différents – rouge, vert et bleu. Dans ce cas, les filtres possèdent 3 canaux, comme l’image elle-même. Le nombre de canaux qu’un filtre possède est appelé sa profondeur, et le nombre de canaux dans le filtre doit correspondre au nombre de canaux dans l’image.
Architecture du réseau de neurones convolutionnel (CNN)
Examinons l’architecture complète d’un réseau de neurones convolutionnel. Une couche convolutionnelle se trouve au début de chaque réseau convolutionnel, car il est nécessaire de transformer les données d’image en tableaux numériques. Cependant, les couches convolutionnelles peuvent également suivre d’autres couches convolutionnelles, ce qui signifie que ces couches peuvent être empilées les unes sur les autres. Avoir plusieurs couches convolutionnelles signifie que les sorties d’une couche peuvent subir des convolutions supplémentaires et être regroupées en modèles pertinents. En pratique, cela signifie que lorsque les données d’image passent à travers les couches convolutionnelles, le réseau commence à “reconnaître” des fonctionnalités plus complexes de l’image.
Les premières couches d’un ConvNet sont responsables de l’extraction des fonctionnalités de bas niveau, telles que les pixels qui forment des lignes simples. Les couches ultérieures du ConvNet relieront ces lignes pour former des formes. Ce processus de passage d’une analyse de surface à une analyse de niveau profond se poursuit jusqu’à ce que le ConvNet reconnaisse des formes complexes comme des animaux, des visages humains et des voitures.
Une fois que les données ont traversé toutes les couches convolutionnelles, elles passent dans la partie densément connectée du CNN. Les couches densément connectées sont ce à quoi ressemble un réseau de neurones feed-forward traditionnel, une série de nœuds disposés en couches qui sont connectés les uns aux autres. Les données passent à travers ces couches densément connectées, qui apprennent les modèles qui ont été extraits par les couches convolutionnelles, et en faisant cela, le réseau devient capable de reconnaître des objets.










