Intelligence artificielle
Le GPT-4o d’OpenAI : Le modèle d’IA multimodal qui transforme l’interaction homme-machine

OpenAI a publié son dernier et plus avancé modèle de langage à ce jour – GPT-4o, également connu sous le nom de “Omni” modèle. Ce système d’IA révolutionnaire représente un géant pas en avant, avec des capacités qui brouillent la frontière entre l’intelligence humaine et artificielle.
Au cœur du GPT-4o se trouve sa nature multimodale native, qui lui permet de traiter et de générer du contenu de manière transparente à travers le texte, l’audio, les images et la vidéo. Cette intégration de plusieurs modalités dans un seul modèle est une première du genre, promettant de réorganiser la façon dont nous interagissons avec les assistants d’IA.
Mais le GPT-4o est bien plus qu’un simple système multimodal. Il affiche une amélioration de performance stupéfiante par rapport à son prédécesseur, le GPT-4, et laisse les modèles concurrents comme Gemini 1.5 Pro, Claude 3 et Llama 3-70B dans la poussière. Plongeons plus profondément dans ce qui rend ce modèle d’IA vraiment innovant.
Performances et efficacité inégalées
L’un des aspects les plus impressionnants du GPT-4o est ses capacités de performance sans précédent. Selon les évaluations d’OpenAI, le modèle a une avance de 60 points Elo sur le précédent meilleur performer, le GPT-4 Turbo. Cet avantage significatif place le GPT-4o dans une ligue à part, surpassant même les modèles d’IA les plus avancés actuellement disponibles.
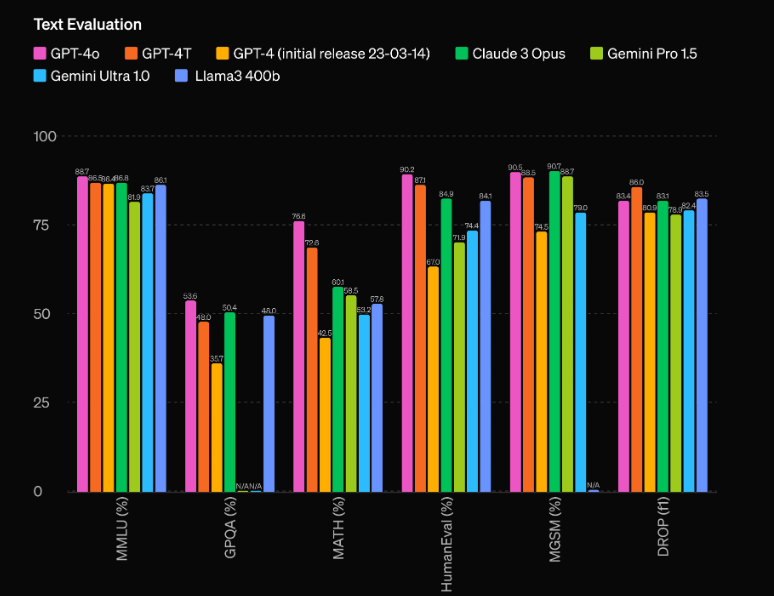
Mais les performances brutes ne sont pas le seul domaine où le GPT-4o brille. Le modèle affiche également une efficacité impressionnante, fonctionnant à deux fois la vitesse du GPT-4 Turbo tout en coûtant seulement la moitié pour fonctionner. Cette combinaison de performances supérieures et de rentabilité fait du GPT-4o une proposition extrêmement attrayante pour les développeurs et les entreprises qui cherchent à intégrer des capacités d’IA de pointe dans leurs applications.
Capacités multimodales : fusion du texte, de l’audio et de la vision
Peut-être l’aspect le plus innovant du GPT-4o est sa nature multimodale native, qui lui permet de traiter et de générer du contenu de manière transparente à travers plusieurs modalités, y compris le texte, l’audio et la vision. Cette intégration de plusieurs modalités dans un seul modèle est une première du genre, et elle promet de révolutionner la façon dont nous interagissons avec les assistants d’IA.
Avec le GPT-4o, les utilisateurs peuvent engager des conversations naturelles et en temps réel en utilisant la parole, le modèle reconnaissant et répondant instantanément aux entrées audio. Mais les capacités ne s’arrêtent pas là – le GPT-4o peut également interpréter et générer du contenu visuel, ouvrant un monde de possibilités pour des applications allant de l’analyse et de la génération d’images à la compréhension et à la création de vidéos.
L’une des démonstrations les plus impressionnantes des capacités multimodales du GPT-4o est sa capacité à analyser une scène ou une image en temps réel, décrivant et interprétant avec précision les éléments visuels qu’il perçoit. Cette fonctionnalité a des implications profondes pour des applications telles que les technologies d’assistance pour les personnes malvoyantes, ainsi que dans des domaines comme la sécurité, la surveillance et l’automatisation.
Mais les capacités multimodales du GPT-4o vont au-delà de la simple compréhension et de la génération de contenu à travers différentes modalités. Le modèle peut également fusionner ces modalités de manière transparente, créant des expériences véritablement immersives et engageantes. Par exemple, lors de la démo en direct d’OpenAI, le GPT-4o a pu générer une chanson en fonction de conditions d’entrée, fusionnant sa compréhension du langage, de la théorie musicale et de la génération audio dans une sortie cohérente et impressionnante.
Utilisation de GPT0 avec Python
import openai
# Remplacez par votre clé API OpenAI réelle
OPENAI_API_KEY = "your_openai_api_key_here";
# Fonction pour extraire le contenu de la réponse
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Impossible de résoudre la réponse : {response_dict}")
# Fonction asynchrone pour envoyer une requête à l'API de chat OpenAI
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Exemple d'utilisation
async def main():
prompt = "Bonjour !"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
J’ai :
- Importé le module openai directement au lieu d’utiliser une classe personnalisée.
- Renommé la fonction openai_chat_resolve en get_response_content et apporté quelques modifications mineures à sa mise en œuvre.
- Remplacé la classe AsyncOpenAI par la fonction openai.ChatCompletion.acreate, qui est la méthode asynchrone officielle fournie par la bibliothèque Python d’OpenAI.
- Ajouté une fonction d’exemple principale qui démontre comment utiliser la fonction send_openai_chat_request.
Veuillez noter que vous devez remplacer “your_openai_api_key_here” par votre clé API OpenAI réelle pour que le code fonctionne correctement.















