Intelligence artificielle
Nouvelle méthode de Deepfake qui résout le problème de l’hôte de visage

Malgré plusieurs années d’hyperventilation médiatique sur le potentiel des images de deepfake pour miner notre foi de longue date dans l’authenticité des séquences vidéo, toutes les méthodes populaires actuelles reposent sur la recherche d’hôtes de visage qui sont globalement similaires en forme au visage cible.
Lorsque les images d’origine présentent un visage large, mais que le sujet cible a un visage étroit, les résultats ont toujours été problématiques, car un tel transfert implique de couper une partie du visage d’origine et de reconstruire l’arrière-plan maintenant exposé. Les packages actuels tels que DeepFaceLab et FaceSwap sont capables de produire des résultats limités lorsque la configuration est inversée (étroit > large), mais n’ont pas de fonctionnalité pour aborder de manière convaincante ce scénario.
Maintenant, une collaboration entre Tencent et l’Université de Xiamen en Chine a développé une nouvelle approche, intitulée HifiFace, conçue pour remédier à cette lacune.

Deux deepfakes HifiFace, le premier d’Anne Hathaway, où une bonne ressemblance est obtenue malgré une forme de visage d’hôte incompatible. HifiFace fonctionne également bien sur les cibles avec des lunettes, traditionnellement un obstacle dans les deepfakes. Source: https://arxiv.org/pdf/2106.09965.pdf
Remodelage d’un visage de deepfake
Les approches précédentes, telles que Subject Agnostic Face Swapping and Reenactment (FSGAN) en 2019, ont reposé sur 3DMM fitting (3D Morphable Models) ou d’autres méthodologies basées sur la reconnaissance de repères faciaux ou la transformation, où les linéaments du visage à « réécrire » dictent pretty much les limites de l’échange :

Détection de repères faciaux 3DMM. Source: https://github.com/Yinghao-Li/3DMM-fitting
Bien que les méthodes concurrentes aient tiré parti de fonctionnalités dérivées de réseaux de reconnaissance de visage, celles-ci sont principalement destinées à reconstituer la texture plutôt que la structure, et produisent également un effet « masque-like » dans les cas où le visage hôte n’est pas entièrement compatible (c’est-à-dire les limites et la forme de la ligne des cheveux, de la mâchoire et des pommettes).
Pour résoudre ces problèmes, les chercheurs chinois, basés au Media Analytics and Computing Lab du département d’intelligence artificielle de l’université, ont développé un réseau de bout en bout qui régresse les coefficients du visage cible et du visage source en utilisant un modèle de reconstruction 3D, qui est ensuite recombinaisonné en tant qu’informations de forme, et concaténé avec des informations de vecteur d’identité provenant d’un réseau de reconnaissance de visage.
Ces données géométriques sont ensuite alimentées dans un modèle encodeur-décodeur en tant qu’informations structurelles, fusionnant avec l’expression et la disposition du visage cible, qui sont utilisées comme sources auxiliaires pour un transfert précis.

Fusion faciale sémantique
En outre, HifiFace inclut un composant de fusion faciale sémantique (SFF), qui utilise une fonctionnalité de niveau inférieur dans l’encodeur pour préserver les informations spatiales et de texture, sans sacrifier l’identité de l’image cible. Les fonctionnalités de l’encodeur et du décodeur sont intégrées dans un masque adaptatif appris, et les informations de fond sont mélangées à la sortie par le biais du masque de visage appris.

HifiFace en action. Source: https://johann.wang/HifiFace/
De cette façon, HifiFace s’écarte de l’utilisation des limites de visage d’origine comme limite dure, en utilisant une segmentation sémantique de visage dilatée, dans laquelle le modèle peut effectuer une meilleure fusion adaptative sur les limites de bord du visage.
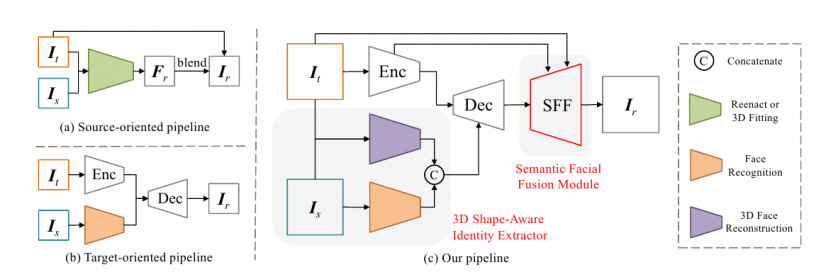
Deux approches antérieures (en haut et en bas à gauche), et la nouvelle architecture HifiFace, qui se compose d’un encodeur, d’un décodeur, d’un extracteur d’identité 3D conscient de la forme et d’un module SFF.

Dans une comparaison avec les méthodes antérieures FSGAN, SimSwap et FaceShifter, HifiFace démontre une reconstruction supérieure de la forme du visage, car il ne prétend pas approximer des éléments « fantômes » où les délimitations faciales confondent la carte d’identité > identité, mais les reconstruit définitivement.

Test
Les chercheurs ont mis en œuvre le système en utilisant les ensembles de données VGGFace2 et DeepGlint Asian-Celeb. Les visages ont été alignés via 5 repères extérieurs et recadrés à 256×256 pixels. Un réseau d’amélioration de portrait a également été utilisé pour générer une version de 512×512 pixels, pour un modèle à plus haute résolution supplémentaire. Le modèle a été formé sous Adam.

Bien que FaceShifter préserve bien l’identité, il ne peut pas aborder les questions telles que l’expression, la couleur et l’occlusion aussi efficacement que HifiFace, et a une structure de réseau plus complexe. FSGAN a des problèmes pour transférer l’éclairage de la source à la cible.
Les chercheurs utilisent FaceForensics++ pour des comparaisons quantitatives, en échantillonnant dix cadres chacun dans un lot de vidéos converties à travers les méthodes concurrentes, et constatant que HifiFace a obtenu un score de récupération d’identifiant supérieur. Lors du test d’une gamme d’autres facteurs, tels que la qualité d’image, les chercheurs ont également constaté que leur méthode surperforme les méthodologies rivales.

Les linéaments du visage de Benedict Cumberbatch sont reproduits fidèlement.
Le travail représente un mouvement supplémentaire vers l’abstraction de la matière source afin qu’elle ne soit qu’un modèle grossier dans lequel des identités précises peuvent être transférées. Certains des packages FOSS actuels, y compris DeepFaceLab, présentent une fonctionnalité nascente pour le remplacement de la tête complète, mais, comme HifiFace, ils ne tiennent pas compte des cheveux, et ils sont plus efficaces pour « construire » un visage que pour le sculpter pour correspondre à une source cible souhaitée.












