Intelligence artificielle
Modification des émotions dans les séquences vidéo avec l’IA

Les chercheurs de Grèce et du Royaume-Uni ont développé une nouvelle approche d’apprentissage profond pour modifier les expressions et l’humeur apparente des personnes dans les séquences vidéo, tout en préservant la fidélité de leurs mouvements de lèvres par rapport à l’audio original d’une manière que les tentatives précédentes n’ont pas pu égaler.

À partir de la vidéo accompagnant l’article (intégrée à la fin de cet article), un court extrait de l’acteur Al Pacino dont l’expression est subtilement modifiée par NED, sur la base de concepts sémantiques de haut niveau définissant les expressions faciales individuelles et leurs émotions associées. La méthode « Reference-Driven » sur la droite prend les émotions interprétées d’une vidéo source et les applique à l’ensemble d’une séquence vidéo. Source : https://www.youtube.com/watch?v=Li6W8pRDMJQ
Ce domaine particulier entre dans la catégorie croissante des émotions deepfaked, où l’identité de l’orateur original est préservée, mais ses expressions et micro-expressions sont modifiées. À mesure que cette technologie d’IA se perfectionne, elle offre la possibilité aux productions de films et de télévision de faire des modifications subtiles aux expressions des acteurs – mais ouvre également une nouvelle catégorie de « vidéos deepfaked avec émotions modifiées ».
Changer les visages
Les expressions faciales des personnalités publiques, telles que les politiciens, sont soigneusement cadrées ; en 2016, les expressions faciales de Hillary Clinton ont fait l’objet d’une intense attention des médias pour leur impact potentiel négatif sur ses perspectives électorales ; les expressions faciales, il s’avère, sont également un sujet d’intérêt pour le FBI ; et elles constituent un indicateur critique lors des entretiens d’embauche, ce qui rend la perspective (très lointaine) d’un filtre de contrôle d’expression en direct un développement souhaitable pour les chercheurs d’emploi qui tentent de passer un pré-écran sur Zoom.
Une étude de 2005 au Royaume-Uni a affirmé que l’apparence faciale influence les décisions de vote, tandis qu’un article de 2019 du Washington Post a examiné l’utilisation de clips vidéo « hors contexte », qui est actuellement la chose la plus proche que les partisans de la fausse information aient pour vraiment pouvoir modifier la façon dont une personnalité publique semble se comporter, répondre ou ressentir.
Vers la manipulation des expressions neuronales
Actuellement, l’état de l’art dans la manipulation de l’affect facial est assez rudimentaire, car il s’agit de résoudre le désentrelacement de concepts de haut niveau (tels que triste, en colère, heureux, souriant) à partir du contenu vidéo réel. Même si les architectures de deepfake traditionnelles semblent réaliser ce désentrelacement de manière efficace, le fait de refléter les émotions à travers différentes identités nécessite toujours que deux ensembles de visages d’entraînement contiennent des expressions correspondantes pour chaque identité.

Exemples typiques d’images de visage dans les ensembles de données utilisés pour former des deepfakes. Actuellement, vous ne pouvez modifier l’expression faciale d’une personne que en créant des chemins d’expression spécifiques à l’identité dans un réseau neuronal de deepfake. Le logiciel de deepfake de 2017 n’a pas de compréhension intrinsèque et sémantique d’un « sourire » – il ne fait que mapper et faire correspondre les changements perçus dans la géométrie faciale entre les deux sujets.
Ce qui est souhaitable, et n’a pas encore été parfaitement réalisé, est de reconnaître comment le sujet B (par exemple) sourit, et de simplement créer un « commutateur de sourire » dans l’architecture, sans avoir besoin de le mapper à une image équivalente du sujet A souriant.
Le nouvel article s’intitule Neural Emotion Director : contrôle sémantique de l’expression faciale dans les vidéos « in-the-wild » en préservant la parole, et provient de chercheurs de l’École d’ingénierie électrique et informatique de l’Université technique nationale d’Athènes, de l’Institut d’informatique de la Fondation pour la recherche et la technologie Hellas (FORTH), et du Collège d’ingénierie, de mathématiques et de sciences physiques de l’Université d’Exeter au Royaume-Uni.
L’équipe a développé un cadre appelé Neural Emotion Director (NED), incorporant un réseau de traduction d’émotion basé sur 3D, 3D-Based Emotion Manipulator.
NED prend une séquence reçue de paramètres d’expression et la traduit dans un domaine cible. Il est formé sur des données non appariées, ce qui signifie qu’il n’est pas nécessaire de former sur des ensembles de données où chaque identité a des expressions faciales correspondantes.
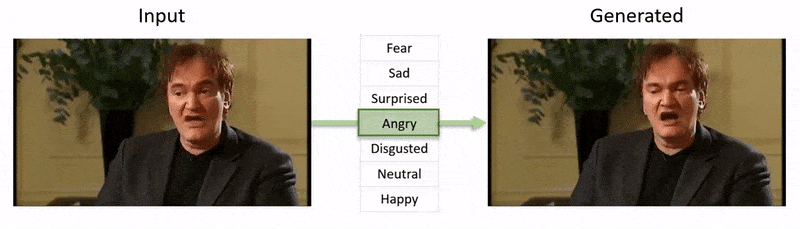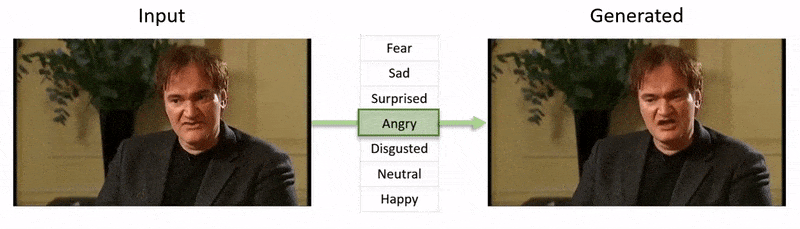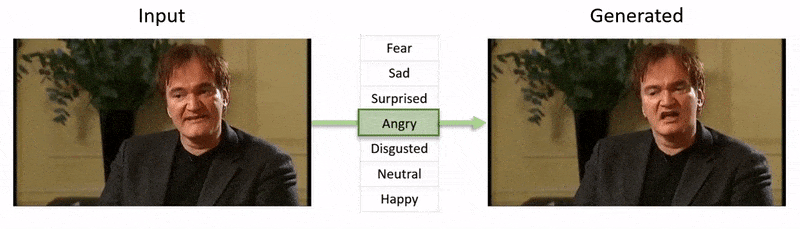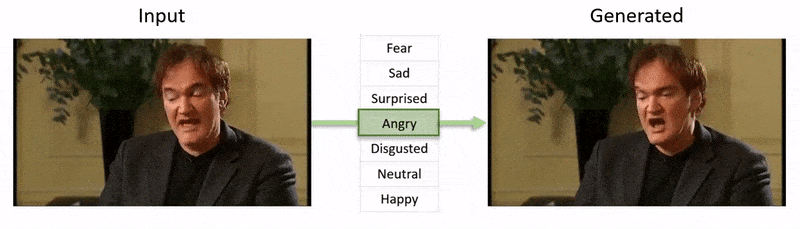
La vidéo, montrée à la fin de cet article, passe par une série de tests où NED impose un état émotionnel apparent sur des extraits de la base de données YouTube.
Les auteurs affirment que NED est la première méthode basée sur la vidéo pour « diriger » les acteurs dans des situations aléatoires et imprévisibles, et ont mis le code à disposition sur la page du projet NED.
Méthode et architecture
Le système est formé sur deux grands ensembles de données vidéo annotés avec des étiquettes d’« émotion ».
La sortie est activée par un rendu de visage vidéo qui rend l’émotion souhaitée à la vidéo en utilisant des techniques traditionnelles de synthèse d’images faciales, y compris la segmentation du visage, l’alignement des repères faciaux et le mélange, où seule la zone faciale est synthétisée, puis imposée sur la séquence d’origine.

L’architecture pour le pipeline du Neural Emotion Detector (NED). Source : https://arxiv.org/pdf/2112.00585.pdf
Initialement, le système obtient la récupération faciale 3D et impose des alignements de repères faciaux sur les trames d’entrée afin d’identifier l’expression. Après cela, ces paramètres d’expression récupérés sont transmis au 3D-Based Emotion Manipulator, et un vecteur de style est calculé par le biais d’une étiquette sémantique (telle que « heureux ») ou d’un fichier de référence.
Un fichier de référence est une vidéo qui représente une expression/emotion particulière reconnue, qui est ensuite imposée à l’ensemble de la vidéo cible, en remplaçant l’expression d’origine.

Étapes du pipeline de transfert d’émotion, mettant en vedette divers acteurs échantillonnés à partir de vidéos YouTube.
La forme de visage 3D générée finale est ensuite concaténée avec la coordonnée de visage moyenne normalisée (NMFC) et les images d’yeux (les points rouges sur l’image ci-dessus), et transmise au rendu neuronal, qui effectue la manipulation finale.
Résultats
Les chercheurs ont mené des études approfondies, y compris des études d’utilisateurs et d’ablation, pour évaluer l’efficacité de la méthode par rapport aux travaux antérieurs, et ont constaté que dans la plupart des catégories, NED surpasse l’état de l’art actuel dans ce sous-secteur de la manipulation faciale neuronale.

Les auteurs de l’article imaginent que les mises en œuvre ultérieures de ce travail, et des outils de nature similaire, seront utiles principalement dans les industries de la télévision et du cinéma, en déclarant :
« Notre méthode ouvre une multitude de nouvelles possibilités pour des applications utiles des technologies de rendu neuronal, allant de la post-production cinématographique et des jeux vidéo aux avatars affectifs photoréalistes. »
Il s’agit d’un travail précoce dans le domaine, mais l’un des premiers à tenter la réenactment faciale avec des vidéos plutôt que des images fixes. Même si les vidéos sont essentiellement de nombreuses images fixes s’affichant très rapidement, il existe des considérations temporelles qui rendent les applications précédentes du transfert d’émotion moins efficaces. Dans la vidéo jointe et les exemples de l’article, les auteurs incluent des comparaisons visuelles de la sortie de NED par rapport à d’autres méthodes récentes comparables.

Des comparaisons plus détaillées et de nombreux autres exemples de NED peuvent être trouvés dans la vidéo complète ci-dessous :
3 décembre 2021, 18h30 GMT+2 – À la demande de l’un des auteurs de l’article, des corrections ont été apportées concernant le « fichier de référence », que j’ai malencontreusement indiqué comme étant une photo fixe (alors qu’il s’agit en fait d’un clip vidéo). Aussi une modification du nom de l’Institut d’informatique de la Fondation pour la recherche et la technologie.
3 décembre 2021, 20h50 GMT+2 – Une deuxième demande de l’un des auteurs de l’article pour une modification supplémentaire du nom de l’institution mentionnée ci-dessus.












