Andersonin kulma
Vaaroja käytettäessä lainauksia NLG-sisällön todentamiseen

MieliLuonnollisen kielen generointimallit, kuten GPT-3, ovat altis “hallusinointiin” materiaalia, jonka ne esittävät faktuaalisen tiedon yhteydessä. Aikakaudella, joka on poikkeuksellisen huolissaan tekstipohjaisen väärän tiedon kasvusta, nämä “miellyttävät” mielikuvitukselliset lennokkuudet edustavat olemassaolokriisiä automaattisen kirjoittamisen ja tiivistelmäjärjestelmien kehittämiselle ja tulevaisuudelle AI-vetoinen journalismi, sekä monille muille luonnollisen kielen prosessoinnin (NLP) alaryhmille.
Perusongelma on, että GPT-tyyppiset kielen mallit johtavat avainominaisuuksia ja luokkia erittäin suurista koulutustekstien korpusista, ja oppivat käyttämään näitä ominaisuuksia kielen rakennuspalikkoina taitavasti ja aidosti, riippumatta generoidun sisällön tarkkuudesta tai jopa hyväksyttävyydestä.
NLG-järjestelmät riippuvat siis tällä hetkellä ihmisten tosiasioita vahvistavasta roolista yhdessä kahdessa lähestymistavassa: joko mallit ovat siemen-tekstigeneraattoreita, jotka välittömästi ohjataan ihmiskäyttäjille vahvistettaviksi tai muokattaviksi; tai ihmiset toimivat kalliina suodattimina parantamaan aineistojen laatua, joita käytetään vähemmän abstrakteja ja “luovia” malleja, jotka ovat itsessään edelleen vaikeasti luotettavia tosiasioita ja jotka vaativat lisää ihmisten valvontaa.
Vanha uutinen ja väärät tosiasiat
Luonnollisen kielen generointi (NLG) -mallit pystyvät tuottamaan vakuuttavia ja uskottavia tuloksia, koska ne ovat oppineet semanttisen arkkitehtuurin, eikä abstraktimmin sisäistäneet itse historiaa, tieteen, taloutta tai muita aiheita, joista ne voivat tarvittaessa lausua mielipidettä, jotka ovat tehokkaasti “matkustajina” lähdeaineistossa.
Tosiasiallisen tarkkuuden osalta NLG-mallien generoimasta tiedosta oletetaan, että koulutusaineisto, jolla ne on koulutettu, on itsessään luotettava ja ajantasainen, mikä asettaa erittäin suuren taakan esikäsittelyssä ja lisää ihmisten tekemässä vahvistamisessa – kalliin esteen, jota NLP-tutkimuksen ala parhaillaan ratkaisee monilla rintamilla.
GPT-3-asteiset järjestelmät vaativat poikkeuksellisen paljon aikaa ja rahaa koulutukseen, ja koulutuksen jälkeen ne ovat vaikeita päivittää “ydin”-tasolla. Vaikka istunnon perusteella tapahtuvat paikalliset muutokset voivat lisätä toteutettujen mallien hyödyllisyyttä ja tarkkuutta, nämä hyödyt ovat vaikeita, joskus mahdottomia siirtää takaisin ydinmalliin ilman täydellistä tai osittaista uudelleenkoulutusta.
Tästä syystä on vaikea luoda koulutettuja kielen malleja, jotka voivat hyödyntää uusinta tietoa.

Koulutettu jopa ennen COVID-19:n saapumista, text-davinci-002 – GPT-3:n iterointi, jota sen luoja OpenAI pitää “kykykkäimpänä” – voi prosessoida 4000 merkkiä pyynnössä, mutta ei tiedä mitään COVID-19:stä tai Ukrainan vuoden 2022 hyökkäyksestä (nämä kysymykset ja vastaukset ovat 5. huhtikuuta 2022). Mielenkiintoista kyllä, “tuntematon” on hyväksytty vastaus kummassakin epäonnistumistapauksessa, mutta lisäkysymykset osoittavat helposti, että GPT-3 ei tiedä näistä tapahtumista. Lähde: https://beta.openai.com/playground
Koulutettu malli voi käyttää vain “totuuksia”, jotka se on sisäistänyt koulutuksen aikana, ja on vaikea saada tarkka ja ja asiaankuuluvia lainauksia oletusarvoisesti, kun yritetään saada malli vahvistamaan väitteensä. Oikea vaara saada lainauksia oletusarvoisesta GPT-3:sta (esimerkiksi) on, että se toisinaan tuottaa oikein lainauksia, mikä johtaa väärään luottamukseen tämän kyvyn osalla:

Ylhäällä, kolme oikein saatuja lainauksia vuoden 2021 davinci-instruct-text GPT-3:sta. Keskellä, GPT-3 ei pysty siteeraamaan yhtä Einsteinin kuuluisimmista lainauksista (“Jumala ei pela diketta maailmankaikkeuden kanssa”), vaikka pyynnössä ei ollut salakirjauksia. Alhaalla, GPT-3 antaa skandaalisen ja kuvitteellisen lainauksen Albert Einsteinille, ilmeisesti ylijäämä aiemmista kysymyksistä Winston Churchillistä samassa istunnossa. Lähde: Kirjoittajan oma artikkeli vuodelta 2021 https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Toivoen pystyvänsä ratkaisemaan tämän yleisen puutteen NLG-malleissa, Google DeepMind ehdotti hiljattain GopherCite, 280 miljardin parametrin mallia, joka pystyy siteeraamaan tarkkaa ja oikeaa näyttöä väittämistensä tueksi.



Kolme esimerkkiä GopherCiten tukemasta väittämistään oikeilla lainauksilla. Lähde: https://arxiv.org/pdf/2203.11147.pdf
GopherCite käyttää vahvistusoppimista ihmisten preferensseistä (RLHP) kouluttaakseen kyselymalleja, jotka pystyvät siteeraamaan oikeita lainauksia todisteena. Lainaukset haetaan suoraan useista asiakirjalähteistä, jotka ovat peräisin hakukoneista tai asiakirjasta, jonka käyttäjä on antanut.
GopherCiten suorituskyky mitattiin ihmisten arvioimalla mallin vastauksia, jotka havaittiin olevan “korkealaatuisia” 80 %:ssa tapauksista Google NaturalQuestions-aineistossa ja 67 %:ssa tapauksista ELI5-aineistossa.
Siteeraus valehtelusta
Kuitenkin, kun GopherCite testattiin Oxfordin yliopiston TruthfulQA -mittarin kanssa, sen vastauksia havaittiin harvoin olevan totuudenmukaisia verrattuna ihmisten kokoamiin “oikein” vastauksiin.
Sen syy on, että “tuetun vastauksen” käsite ei määrittele objektiivisesti itse totuutta, koska lainauslähteiden hyödyllisyys voi olla vaarantunut muilla tekijöillä, kuten mahdollisuudella, että lainauksen kirjoittaja itse “hallusinoi” (esim. kirjoittaa kuvitteellisista maailmoista, tuottaa mainosmateriaalia tai muuten epäaidosti).



GopherCite -tapaukset, joissa uskottavuus ei välttämättä ole sama kuin “totuus”.
Tehokkaasti, on tarpeen erottaa “tuetun” ja “totuudenmukaisen” välillä. Ihmiskulttuuri on tällä hetkellä paljon edellä koneoppimista menetelmien ja kehyksien kehittämisessä, joilla voidaan saavuttaa objektiivisia totuuden määritelmiä, ja jopa siellä, missä “tärkeän” totuuden luonnollinen tila näyttää olevan kiistely ja marginaalinen kieltäytyminen.
Ongelma on rekursiivinen NLG-arkkitehtuureissa, jotka pyrkivät kehittämään määrättyjä “vahvistamismekanismeja”: ihmisten johtama konsensus on pakotettu palvelukseen totuuden mittapuuna ulkoistetuilla, AMT -tyyppisillä malleilla, joissa ihmisen arvioijat (ja muut ihmiset, jotka välittävät riitoja heidän välillään) ovat itsessään osapuolisia ja puolueellisia.
Esimerkiksi alkuperäiset GopherCite-kokeet käyttivät “super-arvioijamallia” valitsemaan parhaat ihmiset arvioimaan mallin tulostetta, valitsemalla vain ne arvioijat, jotka saivat vähintään 85 %:n vertailukohtaisesti laadunvarmistusjoukkoon. Lopulta 113 super-arvioijaa valittiin tehtävään.
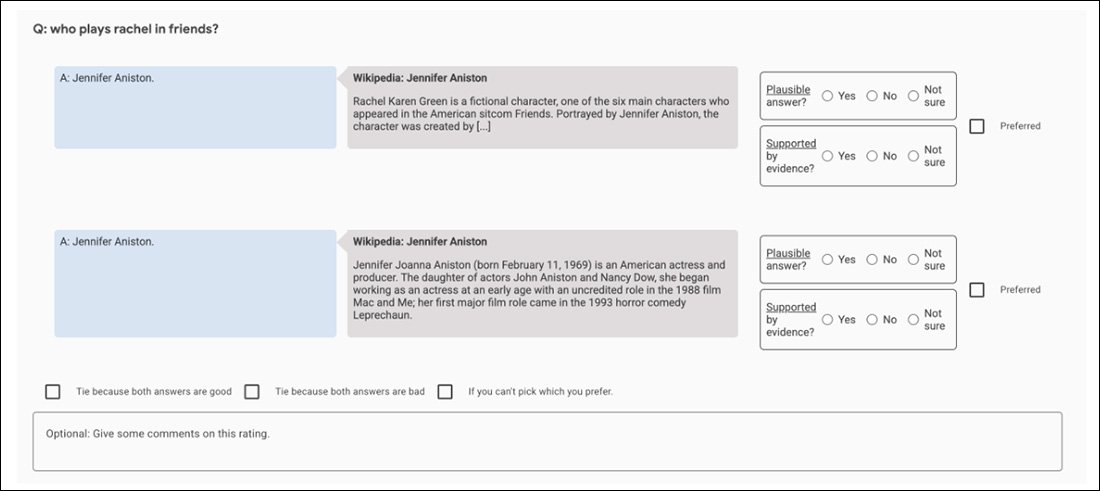
Vertailuohjelman näyttö, jota käytettiin GopherCiten tulosten arviointiin.
Perusteltavasti, tämä on täydellinen kuva voittamattomasta fraktaalista jahdista: laadunvarmistusjoukko, jota käytetään arvioijoiden arviointiin, on itsessään toinen “ihmisten määrittelemä” totuuden mittapuusta, kuten myös Oxford TruthfulQA -joukko, jossa GopherCite on havaittu puutteelliseksi.
Sisällön “tuetun” ja “todistetun” osalta kaikki, mitä NLG-järjestelmät voivat toivoa syntetisoida koulutusaineistosta, on ihmisten epävarmuus ja monimuotoisuus, joka on itsessään epämääräinen ja ratkaisematon ongelma. Meillä on luonnollinen taipumus siteerata lähteitä, jotka tukevat näkemyksiämme, ja puhua asiantuntevasti ja vakuuttavasti tapauksissa, joissa tietolähteemme voi olla vanhentunutta, täysin epätarkkaa tai muuten väärää; ja taipumus levittää nämä näkemykset suoraan villiin, mittakaavassa ja tehokkuudessa, jota ei ole koskaan aiemmin nähty, suoraan tietojen keräämisen kehyksiin, jotka ravitsevat uusia NLG-kehyksiä.
Siten vaara, joka liittyy NLG-järjestelmien kehittämiseen, joka tukee siteerauksia, näyttää olevan sidottu lähteistöateriaalin ennalta-arvattavaan luonteeseen. Kaikki mekanismit (kuten suoran lainauksen ja siteerauksen) jotka lisäävät käyttäjien luottamusta NLG-tuloksiin, ovat tämänhetkisellä tasolla vaarallisia, mutta eivät välttämättä vaikuta tulosten totuudenmukaisuuteen.
Näin ollen tällaiset tekniikat ovat todennäköisesti tarpeen, kun NLP lopulta luo kaunokirjallisuuden “kaleidoskoopit” Orwellin Nineteen Eighty-Fourista; mutta ne edustavat vaarallista jäljittelyä objektiivisen dokumenttianalyysin, AI-keskeisen journalismin ja muiden mahdollisten “tosi”-sovellusten osalta koneellista tiivistämistä ja spontaania tai ohjattua tekstigeneraatiota.
Julkaistu ensimmäisen kerran 5. huhtikuuta 2022. Päivitetty kello 15.29 EET oikaistaakseni termin.












