
Tekoäly
ChatGPT:n ensimmäinen vuosipäivä: tekoälyn vuorovaikutuksen tulevaisuuden muokkaaminen

ChatGPT:n ensimmäistä vuotta ajatellen on selvää, että tämä työkalu on muuttanut merkittävästi tekoälyä. Vuoden 2022 lopussa lanseerattu ChatGPT erottui joukosta käyttäjäystävällisellä, keskustelutyylillään, joka sai vuorovaikutuksen tekoälyn kanssa tuntumaan enemmänkin ihmisen kuin koneen kanssa chattailulta. Tämä uusi lähestymistapa kiinnitti nopeasti yleisön huomion. Vain viisi päivää julkaisunsa jälkeen ChatGPT oli houkutellut jo miljoona käyttäjää. Vuoden 2023 alkuun mennessä tämä luku nousi noin 100 miljoonaan kuukausittaiseen käyttäjään, ja lokakuuhun mennessä alustalla oli noin 1.7 miljardia käyntiä maailmanlaajuisesti. Nämä luvut kertovat paljon sen suosiosta ja hyödyllisyydestä.
Kuluneen vuoden aikana käyttäjät ovat löytäneet kaikenlaisia luovia tapoja käyttää ChatGPT:tä yksinkertaisista tehtävistä, kuten sähköpostien kirjoittamisesta ja ansioluetteloiden päivittämisestä menestyvien yritysten perustamiseen. Mutta kyse ei ole vain siitä, kuinka ihmiset käyttävät sitä; itse tekniikka on kasvanut ja parantunut. Aluksi ChatGPT oli ilmainen palvelu, joka tarjosi yksityiskohtaisia tekstivastauksia. Nyt on ChatGPT Plus, joka sisältää ChatGPT-4:n. Tämä päivitetty versio on koulutettu lisäämään dataa, antaa vähemmän vääriä vastauksia ja ymmärtää monimutkaiset ohjeet paremmin.
Yksi suurimmista päivityksistä on, että ChatGPT voi nyt olla vuorovaikutuksessa useilla tavoilla – se voi kuunnella, puhua ja jopa käsitellä kuvia. Tämä tarkoittaa, että voit puhua sille sen mobiilisovelluksen kautta ja näyttää sille kuvia saadaksesi vastauksia. Nämä muutokset ovat avanneet uusia mahdollisuuksia tekoälylle ja muuttaneet ihmisten näkemystä ja ajattelua tekoälyn roolista elämässämme.
ChatGPT:n matka on varsin vaikuttava sen alusta teknologiademona nykyiseen asemaansa teknologiamaailman merkittävänä toimijana. Aluksi se nähtiin tapana testata ja parantaa teknologiaa saamalla palautetta yleisöltä. Mutta siitä tuli nopeasti olennainen osa tekoälymaisemaa. Tämä menestys osoittaa, kuinka tehokasta on hienosäätää suuria kielimalleja (LLM) sekä ohjatun oppimisen että ihmisten palautteen avulla. Tämän seurauksena ChatGPT pystyy käsittelemään monenlaisia kysymyksiä ja tehtäviä.
Kilpailu tehokkaimpien ja monipuolisimpien tekoälyjärjestelmien kehittämisestä on johtanut sekä avoimen lähdekoodin että ChatGPT:n kaltaisten patentoitujen mallien lisääntymiseen. Heidän yleisten kykyjensä ymmärtäminen vaatii kattavia vertailuarvoja useissa eri tehtävissä. Tämä osio tutkii näitä vertailuarvoja ja valaisee, kuinka eri mallit, mukaan lukien ChatGPT, asettuvat toisiaan vastaan.
LLM:ien arviointi: vertailuarvot
- MT-penkki: Tämä benchmark testaa monikäänteistä keskustelua ja opetuksen seuraamiskykyä kahdeksalla alalla: kirjoittaminen, roolileikit, tiedon poimiminen, päättely, matematiikka, koodaus, STEM-tieto sekä humanistiset ja yhteiskuntatieteet. Vahvempia LLM:itä, kuten GPT-4:ää, käytetään arvioijina.
- AlpacaEval: AlpacaFarm-arviointisarjaan perustuva LLM-pohjainen automaattinen arvioija vertaa malleja edistyneiden LLM-yritysten, kuten GPT-4:n ja Clauden, vastauksiin ja laskee ehdokasmallien voittoprosentin.
- Avaa LLM-tulostaulukko: Kielimallin arviointivaljaiden avulla tämä tulostaulukko arvioi LLM:itä seitsemällä avainkriteerillä, mukaan lukien päättelyhaasteet ja yleistietotestit, sekä nolla- että muutaman otoksen asetuksissa.
- BIG-penkki: Tämä yhteistyöhön perustuva vertailukohta kattaa yli 200 uutta kielitehtävää, jotka kattavat monenlaisia aiheita ja kieliä. Sen tarkoituksena on tutkia LLM:itä ja ennustaa heidän tulevaisuuden kykyjään.
- ChatEval: Monen toimijan keskustelukehys, jonka avulla tiimit voivat itsenäisesti keskustella ja arvioida eri malleista saatujen vastausten laatua avoimiin kysymyksiin ja perinteisiin luonnollisen kielen luontitehtäviin.
Vertaileva suorituskyky
Yleisten vertailuarvojen osalta avoimen lähdekoodin LLM:t ovat edistyneet huomattavasti. Laama-2-70Besimerkiksi saavutti vaikuttavia tuloksia, varsinkin kun sitä oli hienosäädetty ohjetiedoilla. Sen muunnos, Llama-2-chat-70B, loisti AlpacaEvalissa 92.66 %:n voittoprosentilla, ohittaen GPT-3.5-turbon. GPT-4 on kuitenkin edelleen edelläkävijä 95.28 %:n voittoprosentilla.
Zephyr-7B, pienempi malli, osoitti ominaisuuksia, jotka ovat verrattavissa suurempiin 70B LLM:iin, erityisesti AlpacaEvalissa ja MT-Benchissä. Samaan aikaan WizardLM-70B, joka on hienosäädetty monipuolisella ohjetiedolla, sai korkeimman pistemäärän MT-Benchin avoimen lähdekoodin LLM:istä. Se jäi kuitenkin edelleen GPT-3.5-turbon ja GPT-4:n jälkeen.
Mielenkiintoinen artikkeli, GodziLLa2-70B, saavutti kilpailupisteen Open LLM -tulostaulukossa, esitellen kokeellisten mallien potentiaalia, jossa yhdistetään erilaisia tietojoukkoja. Samoin tyhjästä kehitetty Yi-34B erottui pisteistä, jotka olivat verrattavissa GPT-3.5-turboon ja vain hieman GPT-4:ää jäljessä.
UltraLlama, joka on hienosäädetty monipuoliseen ja korkealaatuiseen dataan, vastasi GPT-3.5-turboa ehdotetuissa vertailuissa ja jopa ylitti sen maailman- ja ammatillisen tietämyksen alueilla.
Scaling Up: The Rise of Giant LLMs
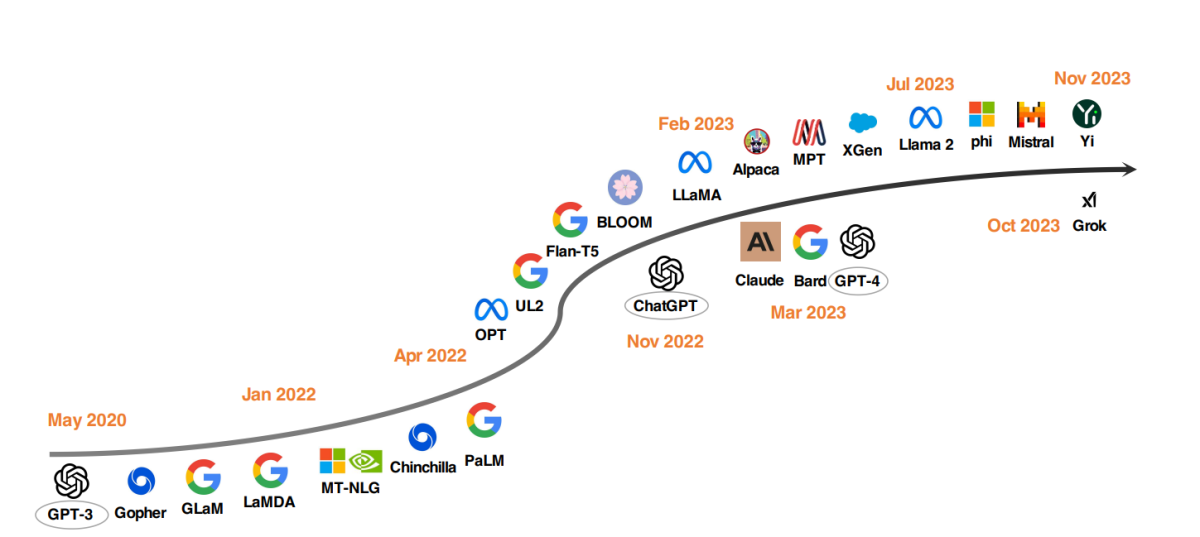
Suosituimmat LLM-mallit vuodesta 2020
Merkittävä suuntaus LLM:n kehityksessä on ollut malliparametrien skaalaus. Mallit, kuten Gopher, GLaM, LaMDA, MT-NLG ja PaLM, ovat työntäneet rajoja, ja ne ovat huipentuneet malleihin, joissa on jopa 540 miljardia parametria. Nämä mallit ovat osoittaneet poikkeuksellisia ominaisuuksia, mutta niiden suljetun lähdekoodin luonne on rajoittanut niiden laajempaa käyttöä. Tämä rajoitus on lisännyt kiinnostusta avoimen lähdekoodin LLM:ien kehittämiseen, mikä on yleistymässä.
Samanaikaisesti mallien koon kasvattamisen kanssa tutkijat ovat tutkineet vaihtoehtoisia strategioita. Sen sijaan, että malleista olisi vain tehty suurempia, he ovat keskittyneet parantamaan pienempien mallien esikoulutusta. Esimerkkejä ovat Chinchilla ja UL2, jotka ovat osoittaneet, että enemmän ei aina ole parempi; älykkäämmät strategiat voivat myös tuottaa tehokkaita tuloksia. Lisäksi on kiinnitetty paljon huomiota kielimallien ohjeiden virittämiseen, ja projektit, kuten FLAN, T0 ja Flan-T5, ovat edistäneet merkittävästi tätä aluetta.
ChatGPT-katalysaattori
OpenAI:n esittely ChatGPT merkitsi käännekohtaa NLP-tutkimuksessa. Kilpaillakseen OpenAI:n kanssa yritykset, kuten Google ja Anthropic, lanseerasivat omat mallinsa, vastaavasti Bard ja Claude. Vaikka näiden mallien suorituskyky on verrattavissa ChatGPT:hen monissa tehtävissä, ne ovat silti jäljessä OpenAI:n uusimmasta mallista, GPT-4:stä. Näiden mallien menestys johtuu ensisijaisesti ihmispalautteen avulla tapahtuvasta vahvistuksesta oppimisesta (RLHF), tekniikasta, joka saa yhä enemmän tutkimuskohdetta lisäparannuksiin.
Huhuja ja spekulaatioita OpenAI:n Q* (Q-Star) ympärillä
Viimeaikaiset selvitykset viittaavat siihen, että OpenAI:n tutkijat ovat saattaneet saavuttaa merkittävää edistystä tekoälyssä kehittämällä uuden mallin nimeltä Q* (lausuttu Q-tähti). Väitetään, että Q* pystyy suorittamaan peruskoulutason matematiikkaa, mikä on herättänyt keskustelua asiantuntijoiden keskuudessa sen mahdollisuuksista virstanpylvänä kohti tekoälyä (AGI). Vaikka OpenAI ei ole kommentoinut näitä raportteja, Q*:n huhutut kyvyt ovat herättäneet huomattavaa jännitystä ja spekulaatiota sosiaalisessa mediassa ja tekoälyn harrastajien keskuudessa.
Q*:n kehitys on huomionarvoista, koska olemassa olevat kielimallit, kuten ChatGPT ja GPT-4, pystyvät suorittamaan joitain matemaattisia tehtäviä, mutta eivät ole erityisen taitavia käsittelemään niitä luotettavasti. Haasteena on tekoälymallien tarve tunnistaa kuvioita, kuten ne tällä hetkellä tekevät syvän oppimisen ja muuntajien avulla, vaan myös järkeillä ja ymmärtää abstrakteja käsitteitä. Matematiikka, joka on päättelyn vertailukohta, vaatii tekoälyä suunnittelemaan ja toteuttamaan useita vaiheita, mikä osoittaa syvän käsityksen abstrakteista käsitteistä. Tämä kyky merkitsisi merkittävää harppausta tekoälyn ominaisuuksissa, mikä mahdollisesti ulottuisi matematiikan ulkopuolelle muihin monimutkaisiin tehtäviin.
Asiantuntijat kuitenkin varovat liioittelemasta tätä kehitystä. Vaikka tekoälyjärjestelmä, joka ratkaisee luotettavasti matemaattisia ongelmia, olisi vaikuttava saavutus, se ei välttämättä merkitse superälykkään tekoälyn tai AGI:n tuloa. Nykyinen tekoälytutkimus, mukaan lukien OpenAI:n ponnistelut, on keskittynyt perusongelmiin vaihtelevalla menestyksellä monimutkaisemmissa tehtävissä.
Mahdolliset sovellusten edistysaskeleet, kuten Q*, ovat valtavat, ja ne vaihtelevat henkilökohtaisesta tutoroinnista tieteellisen tutkimuksen ja suunnittelun avustamiseen. On kuitenkin myös tärkeää hallita odotuksia ja tunnistaa tällaisiin edistysaskeliin liittyvät rajoitukset ja turvallisuusongelmat. Huoli tekoälyn aiheuttamasta eksistentiaalisista riskeistä, OpenAI:n perushuolesta, on edelleen ajankohtainen, varsinkin kun tekoälyjärjestelmät alkavat olla enemmän vuorovaikutuksessa todellisen maailman kanssa.
Avoimen lähdekoodin LLM-liike
Tehostaakseen avoimen lähdekoodin LLM-tutkimusta Meta julkaisi Llama-sarjan mallit, mikä laukaisi Llamaan perustuvan uuden kehityksen aallon. Tämä sisältää mallit, jotka on hienosäädetty ohjetiedoilla, kuten Alpaca, Vicuna, Lima ja WizardLM. Tutkimus haaroittuu myös agenttien kykyjen, loogisen päättelyn ja pitkän kontekstin mallintamiseen laama-pohjaisessa kehyksessä.
Lisäksi on olemassa kasvava trendi kehittää tehokkaita LLM-yrityksiä tyhjästä, ja niissä on projekteja, kuten MPT, Falcon, XGen, Phi, Baichuan, mistraali, grok, ja Yi. Nämä ponnistelut heijastavat sitoutumista demokratisoida suljetun lähdekoodin LLM:ien ominaisuudet ja tehdä edistyneistä tekoälytyökaluista helpommin saavutettavia ja tehokkaampia.
ChatGPT:n ja avoimen lähdekoodin mallien vaikutus terveydenhuollossa
Tarkastelemme tulevaisuutta, jossa LLM:t auttavat kliinisen muistiinpanon tekemisessä, korvausten täyttämisessä ja lääkäreiden tukemisessa diagnoosin ja hoidon suunnittelussa. Tämä on kiinnittänyt sekä teknologiajättien että terveydenhuoltolaitosten huomion.
Microsoftin keskusteluja Epicin kanssa, johtava sähköisten terveyskertomusohjelmistojen toimittaja, viestii LLM:ien integroimisesta terveydenhuoltoon. Aloitteita on jo tehty UC San Diego Healthissa ja Stanfordin yliopiston lääketieteellisessä keskuksessa. Samoin Googlen kumppanuuksia Mayo Clinicin ja Amazon Web Servicesin kanssaTekoälyn kliinisen dokumentointipalvelun HealthScribe julkaisu merkitsee merkittäviä edistysaskeleita tähän suuntaan.
Nämä nopeat käyttöönotot herättävät kuitenkin huolta lääkkeiden hallinnan luovuttamisesta yritysten eduille. Näiden LLM:ien omistusoikeus tekee niistä vaikea arvioida. Niiden mahdollinen muuttaminen tai lopettaminen kannattavuussyistä voi vaarantaa potilaan hoidon, yksityisyyden ja turvallisuuden.
Kiireellinen tarve on avoin ja osallistava lähestymistapa LLM-kehitykseen terveydenhuollossa. Terveydenhuoltolaitosten, tutkijoiden, lääkäreiden ja potilaiden on tehtävä maailmanlaajuista yhteistyötä rakentaakseen avoimen lähdekoodin LLM:itä terveydenhuoltoon. Tämä lähestymistapa, joka on samanlainen kuin Trillion Parameter Consortium, mahdollistaisi laskennallisten, taloudellisten resurssien ja asiantuntemuksen yhdistämisen.











