IA 101
¿Qué es el Teorema de Bayes?
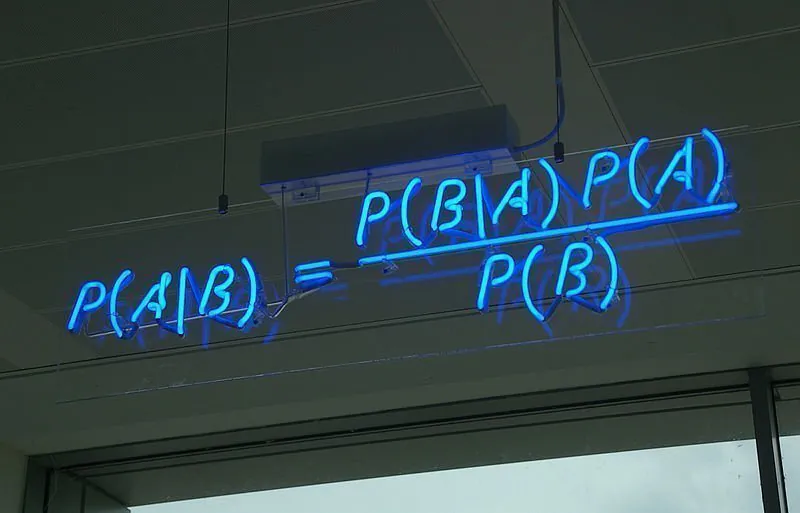
Si ha estado aprendiendo sobre ciencia de datos o aprendizaje automático, es probable que haya escuchado el término “Teorema de Bayes” antes, o un “clasificador de Bayes”. Estos conceptos pueden ser un poco confusos, especialmente si no está acostumbrado a pensar en probabilidad desde una perspectiva tradicional de estadísticas frecuentistas. Este artículo intentará explicar los principios detrás del Teorema de Bayes y cómo se utiliza en el aprendizaje automático.
¿Qué es el Teorema de Bayes?
El Teorema de Bayes es un método de cálculo de probabilidad condicional. El método tradicional de calcular la probabilidad condicional (la probabilidad de que un evento ocurra dado el ocurrencia de un evento diferente) es utilizar la fórmula de probabilidad condicional, calculando la probabilidad conjunta de que el evento uno y el evento dos ocurran al mismo tiempo, y luego dividirla por la probabilidad de que el evento dos ocurra. Sin embargo, la probabilidad condicional también se puede calcular de una manera ligeramente diferente utilizando el Teorema de Bayes.
Al calcular la probabilidad condicional con el teorema de Bayes, se utilizan los siguientes pasos:
- Determinar la probabilidad de que la condición B sea verdadera, asumiendo que la condición A es verdadera.
- Determinar la probabilidad de que el evento A sea verdadero.
- Multiplicar las dos probabilidades juntas.
- Dividir por la probabilidad de que el evento B ocurra.
Esto significa que la fórmula para el Teorema de Bayes se puede expresar de la siguiente manera:
P(A|B) = P(B|A)*P(A) / P(B)
Calcular la probabilidad condicional de esta manera es especialmente útil cuando la probabilidad condicional inversa se puede calcular fácilmente, o cuando calcular la probabilidad conjunta sería demasiado desafiante.
Ejemplo del Teorema de Bayes
Esto puede ser más fácil de interpretar si pasamos algún tiempo mirando un ejemplo de cómo aplicar el razonamiento bayesiano y el Teorema de Bayes. Supongamos que estuviera jugando un juego simple donde varios participantes le cuentan una historia y debe determinar quién de los participantes le está mintiendo. Llenemos la ecuación para el Teorema de Bayes con las variables en este escenario hipotético.
Estamos tratando de predecir si cada individuo en el juego está mintiendo o diciendo la verdad, así que si hay tres jugadores aparte de usted, las variables categóricas se pueden expresar como A1, A2 y A3. La evidencia de sus mentiras o verdades es su comportamiento. Al igual que cuando se juega al póker, buscaría ciertos “indicios” de que una persona está mintiendo y los utilizaría como fragmentos de información para informar su suposición. O si se le permitiera hacerles preguntas, sería cualquier evidencia de que su historia no suma. Podemos representar la evidencia de que una persona está mintiendo como B.
Para ser claro, estamos tratando de predecir la probabilidad (A está mintiendo / diciendo la verdad | dada la evidencia de su comportamiento). Para hacer esto, nos gustaría determinar la probabilidad de B dado A, o la probabilidad de que su comportamiento ocurra dado que la persona está mintiendo o diciendo la verdad. Estás tratando de determinar bajo qué condiciones el comportamiento que estás viendo tendría más sentido. Si hay tres comportamientos que estás presenciando, harías el cálculo para cada comportamiento. Por ejemplo, P(B1, B2, B3 * A). Luego harías esto para cada ocurrencia de A / para cada persona en el juego aparte de usted. Esa es esta parte de la ecuación de arriba:
P(B1, B2, B3, |A) * P|A
Finalmente, solo dividimos eso por la probabilidad de B.
Si recibimos alguna evidencia sobre las probabilidades reales en esta ecuación, recrearíamos nuestro modelo de probabilidad, teniendo en cuenta la nueva evidencia. Esto se llama actualizar nuestros priores, ya que actualizamos nuestras suposiciones sobre la probabilidad previa de que ocurran los eventos observados.
Aplicaciones de aprendizaje automático para el teorema de Bayes
El uso más común del teorema de Bayes cuando se trata de aprendizaje automático es en la forma del algoritmo Naive Bayes.
Naive Bayes se utiliza para la clasificación de conjuntos de datos binarios y multiclase, Naive Bayes obtiene su nombre porque los valores asignados a las pruebas de los testigos / atributos – Bs en P(B1, B2, B3 * A) – se asumen que son independientes entre sí. Se asume que estos atributos no se afectan entre sí para simplificar el modelo y hacer que los cálculos sean posibles, en lugar de intentar la tarea compleja de calcular las relaciones entre cada uno de los atributos. A pesar de este modelo simplificado, Naive Bayes tiende a funcionar bastante bien como algoritmo de clasificación, incluso cuando esta suposición probablemente no sea cierta (lo que es la mayoría de las veces).
También hay variantes comunes del clasificador Naive Bayes, como Multinomial Naive Bayes, Bernoulli Naive Bayes y Gaussian Naive Bayes.
Los algoritmos Multinomial Naive Bayes a menudo se utilizan para clasificar documentos, ya que es efectivo para interpretar la frecuencia de las palabras dentro de un documento.
Los algoritmos Bernoulli Naive Bayes operan de manera similar a Multinomial Naive Bayes, pero las predicciones renderizadas por el algoritmo son booleanas. Esto significa que al predecir una clase, los valores serán binarios, no o sí. En el dominio de la clasificación de texto, un algoritmo Bernoulli Naive Bayes asignaría los parámetros un sí o no según si una palabra se encuentra o no dentro del documento de texto.
Si el valor de los predictores / características no es discreto, sino continuo, se puede utilizar Gaussian Naive Bayes. Se asume que los valores de las características continuas se han muestreado de una distribución gaussiana.












