IA 101
¿Cómo funciona la clasificación de imágenes?
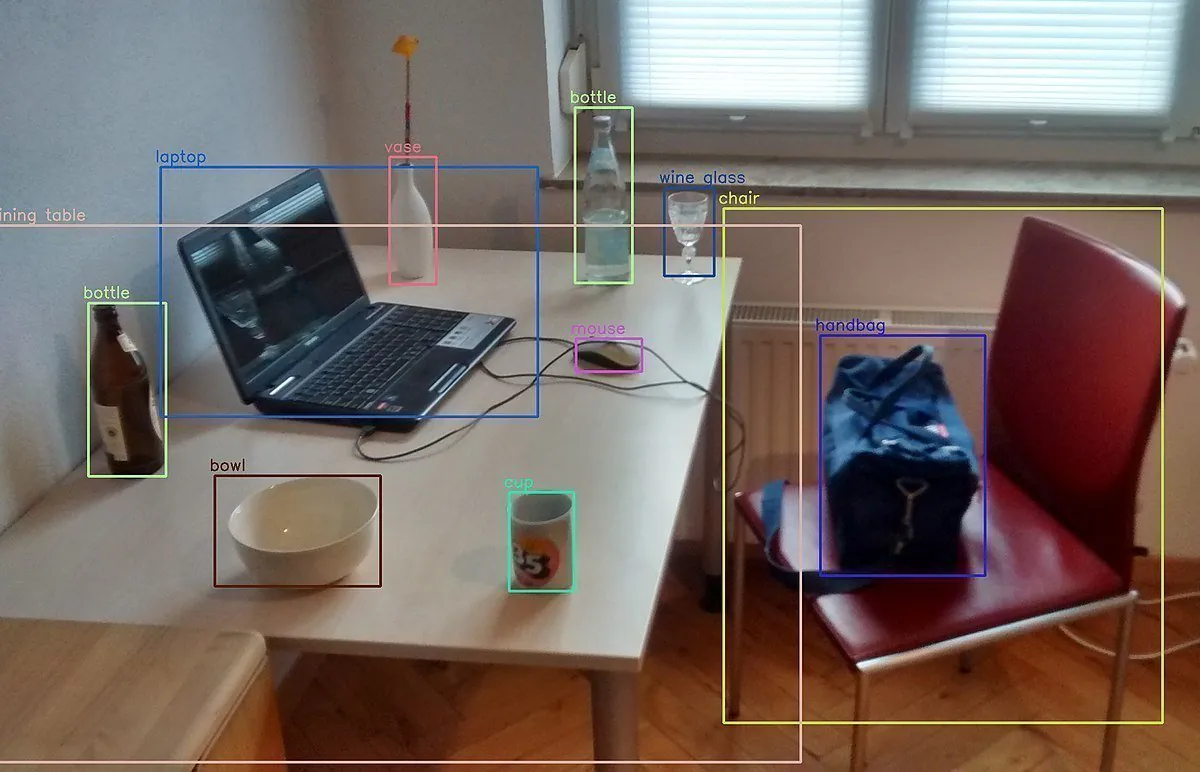
¿Cómo puede su teléfono determinar qué es un objeto solo tomando una foto de él? ¿Cómo los sitios web de redes sociales etiquetan automáticamente a las personas en las fotos? Esto se logra a través del reconocimiento y clasificación de imágenes impulsados por inteligencia artificial.
El reconocimiento y la clasificación de imágenes son lo que permite muchos de los logros más impresionantes de la inteligencia artificial. Sin embargo, ¿cómo aprenden los ordenadores a detectar y clasificar imágenes? En este artículo, cubriremos los métodos generales que utilizan los ordenadores para interpretar y detectar imágenes y luego examinaremos algunos de los métodos más populares para clasificar esas imágenes.
Clasificación a nivel de píxel vs. clasificación basada en objetos
Las técnicas de clasificación de imágenes se pueden dividir principalmente en dos categorías diferentes: clasificación basada en píxel y clasificación basada en objetos.
Los píxeles son las unidades básicas de una imagen, y el análisis de píxeles es la forma principal en que se realiza la clasificación de imágenes. Sin embargo, los algoritmos de clasificación pueden utilizar solo la información espectral dentro de los píxeles individuales para clasificar una imagen o examinar la información espacial (píxeles cercanos) junto con la información espectral. Los métodos de clasificación basados en píxeles utilizan solo la información espectral (la intensidad de un píxel), mientras que los métodos de clasificación basados en objetos tienen en cuenta tanto la información espectral de los píxeles como la información espacial.
Hay diferentes técnicas de clasificación utilizadas para la clasificación basada en píxeles. Estas incluyen la distancia mínima al promedio, la probabilidad máxima y la distancia mínima de Mahalanobis. Estos métodos requieren que se conozcan los promedios y varianzas de las clases, y todos operan examinando la “distancia” entre los promedios de las clases y los píxeles objetivo.
Los métodos de clasificación basados en píxeles están limitados por el hecho de que no pueden utilizar información de píxeles cercanos. En contraste, los métodos de clasificación basados en objetos pueden incluir otros píxeles y, por lo tanto, también utilizan la información espacial para clasificar los artículos. Tenga en cuenta que “objeto” se refiere solo a regiones contiguas de píxeles y no a si hay o no un objeto objetivo dentro de esa región de píxeles.
Preprocesamiento de datos de imagen para la detección de objetos
Los sistemas de clasificación de imágenes más recientes y confiables utilizan principalmente esquemas de clasificación a nivel de objeto, y para estos enfoques, los datos de imagen deben prepararse de maneras específicas. Los objetos / regiones necesitan ser seleccionados y preprocesados.
Antes de que una imagen y los objetos / regiones dentro de esa imagen puedan ser clasificados, los datos que componen esa imagen deben ser interpretados por la computadora. Las imágenes necesitan ser preprocesadas y preparadas para la entrada en el algoritmo de clasificación, y esto se hace a través de la detección de objetos. Esta es una parte crítica de la preparación de los datos y la preparación de las imágenes para entrenar el clasificador de aprendizaje automático.
La detección de objetos se realiza con una variedad de métodos y técnicas. Para comenzar, si hay múltiples objetos de interés o un solo objeto de interés, esto afecta cómo se maneja el preprocesamiento de la imagen. Si solo hay un objeto de interés, la imagen pasa por la localización de la imagen. Los píxeles que componen la imagen tienen valores numéricos que son interpretados por la computadora y utilizados para mostrar los colores y matices adecuados. Un objeto llamado cuadro delimitador se dibuja alrededor del objeto de interés, lo que ayuda a la computadora a saber qué parte de la imagen es importante y qué valores de píxeles definen el objeto. Si hay múltiples objetos de interés en la imagen, se utiliza una técnica llamada detección de objetos para aplicar estos cuadros delimitadores a todos los objetos dentro de la imagen.

Foto: Adrian Rosebrock a través de Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Intersection_over_Union_-_object_detection_bounding_boxes.jpg)
Otro método de preprocesamiento es la segmentación de imágenes. La segmentación de imágenes funciona dividiendo toda la imagen en segmentos según características similares. Diferentes regiones de la imagen tendrán valores de píxeles similares en comparación con otras regiones de la imagen, por lo que estos píxeles se agrupan en máscaras de imagen que corresponden a la forma y los límites de los objetos relevantes dentro de la imagen. La segmentación de imágenes ayuda a la computadora a aislar las características de la imagen que ayudarán a clasificar un objeto, al igual que los cuadros delimitadores, pero proporcionan etiquetas más precisas y a nivel de píxel.
Después de que se haya completado la detección de objetos o la segmentación de la imagen, se aplican etiquetas a las regiones en cuestión. Estas etiquetas se alimentan, junto con los valores de los píxeles que componen el objeto, en los algoritmos de aprendizaje automático que aprenderán patrones asociados con las diferentes etiquetas.
Algoritmos de aprendizaje automático
Una vez que los datos han sido preparados y etiquetados, los datos se alimentan en un algoritmo de aprendizaje automático, que se entrena con los datos. Cubriremos algunos de los algoritmos de clasificación de imágenes más comunes de aprendizaje automático a continuación.
K-Nearest Neighbors
K-Nearest Neighbors es un algoritmo de clasificación que examina los ejemplos de entrenamiento más cercanos y mira sus etiquetas para determinar la etiqueta más probable para un ejemplo de prueba determinado. Cuando se trata de clasificación de imágenes utilizando KNN, los vectores de características y las etiquetas de las imágenes de entrenamiento se almacenan y solo el vector de características se pasa al algoritmo durante la prueba. Los vectores de características de entrenamiento y prueba se comparan entre sí para similitud.
Los algoritmos de clasificación basados en KNN son extremadamente simples y manejan múltiples clases con facilidad. Sin embargo, KNN calcula la similitud en función de todas las características por igual. Esto significa que puede ser propenso a malclasificaciones cuando se proporcionan imágenes donde solo un subconjunto de las características es importante para la clasificación de la imagen.
Máquinas de vectores de soporte
Las máquinas de vectores de soporte son un método de clasificación que coloca puntos en el espacio y luego dibuja líneas divisorias entre los puntos, colocando objetos en diferentes clases según qué lado de la plano divisorio caen los puntos. Las máquinas de vectores de soporte pueden realizar clasificaciones no lineales a través del uso de una técnica llamada truco del kernel. Si bien los clasificadores SVM suelen ser muy precisos, una desventaja sustancial de los clasificadores SVM es que tienden a estar limitados por el tamaño y la velocidad, con la velocidad que sufre a medida que aumenta el tamaño.
Perceptrones multicapacidad (Redes neuronales)
Los perceptrones multicapacidad, también llamados modelos de redes neuronales, son algoritmos de aprendizaje automático inspirados en el cerebro humano. Los perceptrones multicapacidad están compuestos por varias capas que están unidas entre sí, al igual que las neuronas en el cerebro humano están conectadas entre sí. Las redes neuronales hacen suposiciones sobre cómo las características de entrada están relacionadas con las clases de los datos y estas suposiciones se ajustan durante el entrenamiento. Los modelos de red neuronal simples como el perceptrón multicapacidad pueden aprender relaciones no lineales, y como resultado, pueden ser mucho más precisos que otros modelos. Sin embargo, los modelos MLP sufren de algunos problemas notables como la presencia de funciones de pérdida no convexa.
Algoritmos de aprendizaje profundo (CNN)

Foto: APhex34 a través de Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Typical_cnn.png)
El algoritmo de clasificación de imágenes más comúnmente utilizado en la actualidad es la Red Neuronal Convolucional (CNN). Las CNN son versiones personalizadas de las redes neuronales que combinan las redes neuronales multicapacidad con capas especializadas que pueden extraer las características más importantes y relevantes para la clasificación de un objeto. Las CNN pueden descubrir, generar y aprender automáticamente las características de las imágenes. Esto reduce en gran medida la necesidad de etiquetar y segmentar manualmente las imágenes para prepararlas para los algoritmos de aprendizaje automático. También tienen una ventaja sobre las redes MLP porque pueden manejar funciones de pérdida no convexas.
Las Redes Neuronales Convolucionales obtienen su nombre del hecho de que crean “convoluciones”. Las CNN operan tomando un filtro y deslizándolo sobre una imagen. Puedes pensar en esto como ver secciones de un paisaje a través de una ventana móvil, concentrándote solo en las características que son visibles a través de la ventana en cualquier momento. El filtro contiene valores numéricos que se multiplican con los valores de los píxeles en sí. El resultado es un nuevo marco, o matriz, lleno de números que representan la imagen original. Este proceso se repite para un número determinado de filtros, y luego los marcos se unen en una nueva imagen que es ligeramente más pequeña y menos compleja que la original. Se utiliza una técnica llamada pooling para seleccionar solo los valores más importantes dentro de la imagen, y el objetivo es que las capas convolucionales extraigan eventualmente solo las partes más destacadas de la imagen que ayudarán a la red neuronal a reconocer los objetos en la imagen.
Las Redes Neuronales Convolucionales están compuestas por dos partes diferentes. Las capas convolucionales son las que extraen las características de la imagen y las convierten en un formato que las capas de la red neuronal pueden interpretar y aprender. Las capas convolucionales tempranas son responsables de extraer los elementos más básicos de la imagen, como líneas y límites simples. Las capas convolucionales medias comienzan a capturar formas más complejas, como curvas y esquinas simples. Las capas convolucionales más profundas extraen las características de alto nivel de la imagen, que son las que se pasan a la parte de la red neuronal de la CNN, y son las que el clasificador aprende.












