Inteligencia Artificial
Verificación facial 'creativa' con redes adversarias generativas

Un nuevo artículo de la Universidad de Stanford ha propuesto un método incipiente para engañar a los sistemas de autenticación facial en plataformas como las aplicaciones de citas, mediante el uso de un Red de Publicidad Generativa (GAN) para crear imágenes faciales alternativas que contengan la misma información de identificación esencial que una cara real.
El método eludió con éxito los procesos de verificación facial en las aplicaciones de citas Tinder y Bumble, en un caso incluso hizo pasar una cara (masculina) con cambio de género como auténtica para la identidad original (femenina).

Varias identidades generadas que presentan la codificación específica del autor del artículo (que aparece en la primera imagen de arriba). Fuente: https://arxiv.org/pdf/2203.15068.pdf
Según el autor, la obra representa el primer intento de eludir la verificación facial con el uso de imágenes generadas que han sido imbuidas de rasgos de identidad específicos, pero que intentan representar una identidad alternativa o sustancialmente alterada.
La técnica se probó en un sistema local personalizado de verificación de rostros y luego funcionó bien en pruebas de caja negra contra dos aplicaciones de citas que realizan verificación facial en imágenes cargadas por usuarios.
El nuevo edificio corporativo de se titula Omisión de verificación facial, y proviene de Sanjana Sarda, investigadora del Departamento de Ingeniería Eléctrica de la Universidad de Stanford.
Controlar el espacio de la cara
Aunque se 'inyectan' características específicas de la identificación (es decir, de rostros, las señales de tráfico, etc.) en imágenes artesanales es un elemento básico de ataques adversosEl nuevo estudio sugiere algo diferente: que el sector de investigación capacidad de crecimiento a control el espacio latente de las GAN eventualmente permitirá el desarrollo de arquitecturas que pueden crear consistente identidades alternativas a la de un usuario y, en efecto, permitir la extracción de características de identidad de imágenes disponibles en la web de un usuario desprevenido para cooptarlas en una identidad 'fantasmal' creada.
La consistencia y la navegabilidad han sido los principales desafíos del espacio latente de la GAN desde el inicio de las Redes Generativas Antagónicas. Una GAN que ha asimilado con éxito una colección de imágenes de entrenamiento en su espacio latente no ofrece un mapa sencillo para transferir características de una clase a otra.
Si bien las técnicas y herramientas como el mapeo de activación de clase ponderado por gradiente (Graduado-CAM) puede ayudar a establecer direcciones latentes entre las clases establecidas y permitir transformaciones (ver imagen a continuación), el desafío adicional de enredo Suele ser un recorrido "aproximado", con un control fino y limitado de la transición.
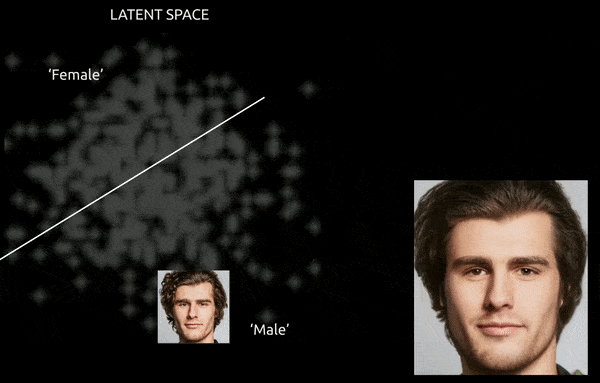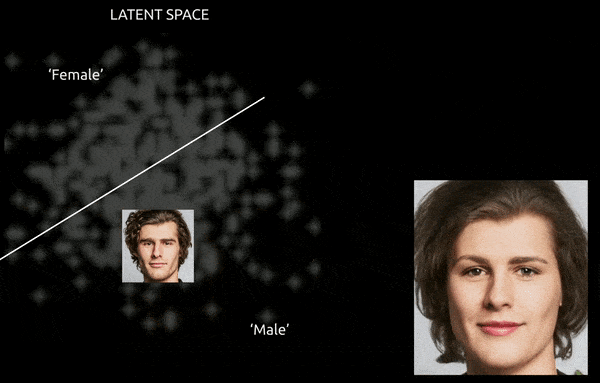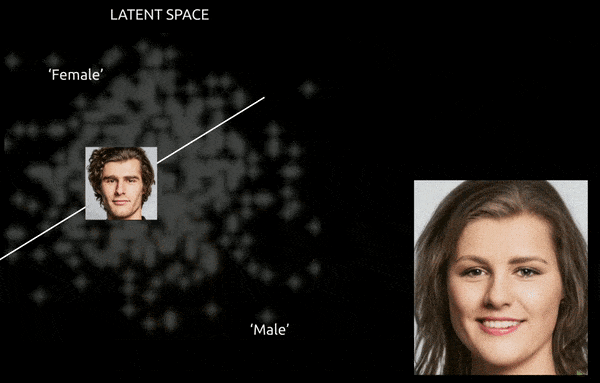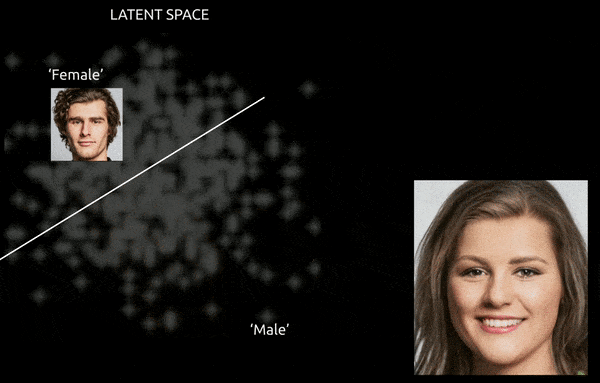
Un viaje aproximado entre vectores codificados en el espacio latente de una GAN, que empuja una identidad masculina derivada de datos hacia las codificaciones "femeninas" en el otro lado de uno de los muchos hiperplanos lineales en el espacio latente complejo y arcano. Imagen derivada del material en https://www.youtube.com/watch?v=dCKbRCUyop8
La capacidad de 'congelar' y proteger características específicas de la identidad mientras se las traslada a codificaciones transformadoras en otra parte del espacio latente potencialmente hace posible la creación de un individuo consistente (e incluso animable) cuya identidad es leída por los sistemas de máquina como si fuera otra persona.
Método
El autor usó dos conjuntos de datos como base para los experimentos: un conjunto de datos de usuario humano que consta de 310 imágenes de su rostro que abarcan un período de cuatro años, con iluminación, edad y ángulos de visión variables, con rostros recortados extraídos a través de Caffe; y las 108,501 imágenes racialmente equilibradas en el cara justa conjunto de datos, extraído y recortado de manera similar.
El modelo de verificación facial local se derivó de una implementación base de facenet y cara profunda, pre-entrenado en Inicio de ConvNet, con cada imagen representada por un vector de 128 dimensiones.
El enfoque utiliza imágenes faciales de un subconjunto entrenado de FairFace. Para pasar la verificación facial, la distancia calculada causada por la imagen... norma frobenius se compensa con el usuario de destino en la base de datos. Cualquier imagen por debajo del umbral de 0.7 equivale a la misma identidad; de lo contrario, se considera que la verificación ha fallado.
Se ajustó un modelo StyleGAN con el conjunto de datos personales de la autora, lo que generó un modelo que generaría variaciones reconocibles de su identidad, aunque ninguna de estas imágenes generadas era idéntica a los datos de entrenamiento. Esto se logró mediante congelación las primeras cuatro capas en el discriminador, para evitar el sobreajuste de los datos y producir resultados variados.
Aunque se obtuvieron diversas imágenes con el modelo base StyleGAN, la baja resolución y la fidelidad provocaron un segundo intento con StarGANV2, que permite el entrenamiento de imágenes semilla hacia una cara objetivo.
El modelo StarGAN V2 se entrenó previamente durante aproximadamente 10 horas utilizando el conjunto de validación FairFace, en un tamaño de lote de cuatro y un tamaño de validación de 8. En el enfoque más exitoso, se utilizó el conjunto de datos personales del autor como fuente con los datos de entrenamiento como referencia.
Experimentos de verificación
Se construyó un modelo de verificación facial a partir de un subconjunto de 1000 imágenes, con la intención de verificar una imagen arbitraria del conjunto. Las imágenes que superaron la verificación se compararon posteriormente con la identificación del autor.

A la izquierda, el autor del artículo, una fotografía real; en el medio, una imagen arbitraria que no pasó la verificación; a la derecha, una imagen no relacionada del conjunto de datos que pasó la verificación como el autor.
El objetivo de los experimentos era crear una brecha lo más amplia posible entre la identidad visual percibida y conservar los rasgos definitorios de la identidad objetivo. Esto fue evaluado con Distancia de Mahalanobis, una métrica utilizada en el procesamiento de imágenes para la búsqueda de patrones y plantillas.
Para el modelo generativo de referencia, los resultados de baja resolución obtenidos muestran una diversidad limitada, a pesar de pasar la verificación facial local. StarGAN V2 demostró ser más capaz de crear diversas imágenes que pudieron autenticarse.

Todas las imágenes representadas pasaron la verificación facial local. Arriba están las generaciones de referencia StyleGAN de baja resolución, abajo, las generaciones StarGAN V2 de mayor resolución y calidad.
Las tres imágenes finales ilustradas arriba utilizaron el propio conjunto de datos faciales del autor como fuente y referencia, mientras que las imágenes anteriores utilizaron datos de entrenamiento como referencia y el conjunto de datos del autor como fuente.
Las imágenes generadas se probaron con los sistemas de verificación facial de las apps de citas Bumble y Tinder, tomando como referencia la identidad del autor, y pasaron la verificación. Una versión masculina del rostro del autor también pasó el proceso de verificación de Bumble, aunque fue necesario ajustar la iluminación de la imagen generada antes de que fuera aceptada. Tinder no aceptó la versión masculina.

Versiones “masculinas” de la identidad (femenina) de la autora.
Conclusión
Estos son experimentos fundamentales en la proyección de identidad, en el contexto de la manipulación del espacio latente mediante GAN, lo cual sigue siendo un desafío extraordinario en la síntesis de imágenes y la investigación de deepfakes. No obstante, este trabajo abre la posibilidad de integrar características altamente específicas de forma consistente en diversas identidades y de crear identidades alternativas que se interpreten como otras.
Publicado por primera vez el 30 de marzo de 2022.












