Inteligencia artificial
La IA ayuda a los oradores nerviosos a ‘leer la sala’ durante las videoconferencias

En 2013, una encuesta sobre fobias comunes determinó que la perspectiva de hablar en público era peor que la perspectiva de la muerte para la mayoría de los encuestados. El síndrome se conoce como glossophobia.
La migración impulsada por COVID desde las reuniones “en persona” a las conferencias de Zoom en línea en plataformas como Zoom y Google Spaces, sorprendentemente, no ha mejorado la situación. Cuando la reunión contiene un gran número de participantes, nuestras habilidades naturales de evaluación de amenazas se ven afectadas por las filas y los iconos de participantes de baja resolución, y la dificultad para leer señales visuales sutiles de expresión facial y lenguaje corporal. Skype, por ejemplo, se ha encontrado que es una mala plataforma para transmitir señales no verbales.
Los efectos en el rendimiento de la oratoria pública de la percepción de interés y respuesta están bien documentados por ahora, y son intuitivamente obvios para la mayoría de nosotros. La respuesta opaca del público puede hacer que los oradores titubeen y se retracten a habla de relleno, sin saber si sus argumentos están encontrando acuerdo, desdén o desinterés, lo que a menudo hace que la experiencia sea incómoda tanto para el orador como para sus oyentes.
Bajo la presión del cambio inesperado hacia la videoconferencia en línea inspirado en las restricciones y precauciones de COVID, el problema es arguablemente peor, y se han sugerido varios esquemas de retroalimentación de la audiencia en las comunidades de visión por computadora y afecto durante los últimos dos años.
Soluciones enfocadas en hardware
La mayoría de estos, sin embargo, involucran equipo adicional o software complejo que puede generar problemas de privacidad o logística – estilos de enfoque relativamente costosos o con restricciones de recursos que preceden a la pandemia. En 2001, MIT propuso el Galvactivator, un dispositivo que se lleva en la mano que infiere el estado emocional del participante de la audiencia, probado durante un simposio de un día.

Desde 2001, el Galvactivator de MIT, que medía la respuesta de conductividad de la piel para intentar entender el sentimiento y la participación de la audiencia. Fuente: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Se ha dedicado mucha energía académica a la posible implementación de ‘pulsadores’ como un Sistema de Respuesta de la Audiencia (ARS), una medida para aumentar la participación activa de las audiencias (lo que aumenta automáticamente la participación, ya que obliga al espectador a asumir el papel de un nodo de retroalimentación activo), pero que también se ha considerado como un medio de aliento para los oradores.
Otros intentos de ‘conectar’ al orador y la audiencia han incluido monitoreo de frecuencia cardíaca, el uso de equipo complejo que se lleva en el cuerpo para aprovechar la electroencefalografía, ‘medidores de aplausos’, reconocimiento de emociones basado en visión por computadora para trabajadores de escritorio, y el uso de emoticonos enviados por la audiencia durante la oración del orador.

Desde 2017, el EngageMeter, un proyecto de investigación académica conjunto de LMU Munich y la Universidad de Stuttgart. Fuente: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Como una sub-búsqueda del área lucrativa de análisis de audiencia, el sector privado ha tomado un interés particular en la estimación y seguimiento de la mirada – sistemas donde cada miembro de la audiencia (que a su vez puede tener que hablar), está sujeto a seguimiento ocular como un índice de compromiso y aprobación.
La mayoría de estos métodos son bastante de alta fricción. Muchos de ellos requieren equipo adicional o software complejo que puede generar problemas de privacidad o logística – enfoques relativamente costosos o con restricciones de recursos que preceden a la pandemia.
Por lo tanto, el desarrollo de sistemas minimalistas basados en poco más que herramientas comunes para videoconferencia ha sido de interés en los últimos 18 meses.
Informar la aprobación de la audiencia de manera discreta
Con este fin, una nueva colaboración de investigación entre la Universidad de Tokio y la Universidad Carnegie Mellon ofrece un sistema novel que puede aprovechar las herramientas de videoconferencia estándar (como Zoom) utilizando solo un sitio web habilitado para webcam en el que se ejecuta software de estimación de mirada y pose ligero. De esta manera, incluso la necesidad de plugins de navegador local se evita.
Los movimientos de asentimiento y la atención estimada del usuario se traducen en datos representativos que se visualizan de regreso al orador, lo que permite una especie de ‘prueba de litio’ en vivo de la medida en que el contenido está comprometiendo a la audiencia – y también al menos un indicador vago de períodos de discurso donde el orador puede estar perdiendo el interés de la audiencia.
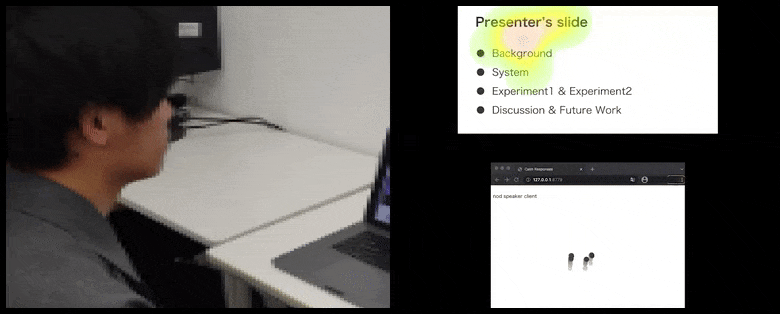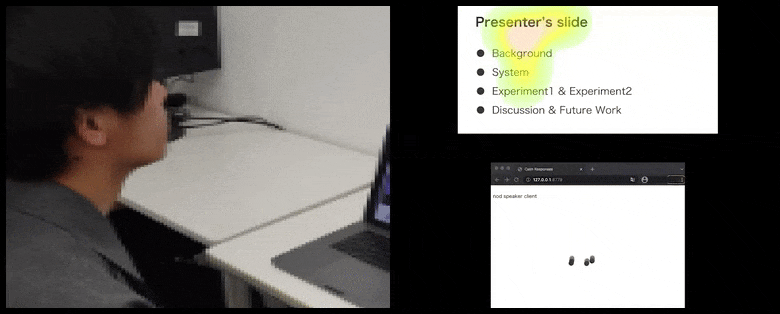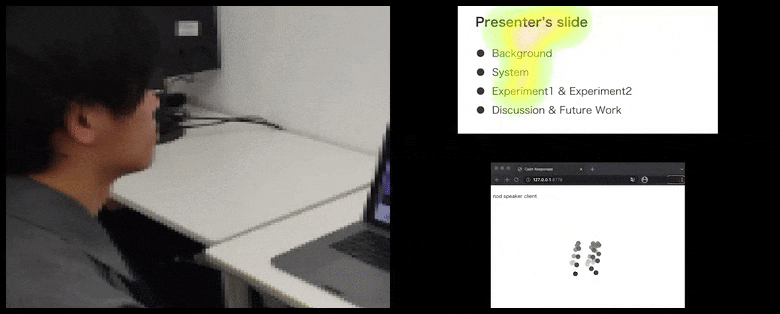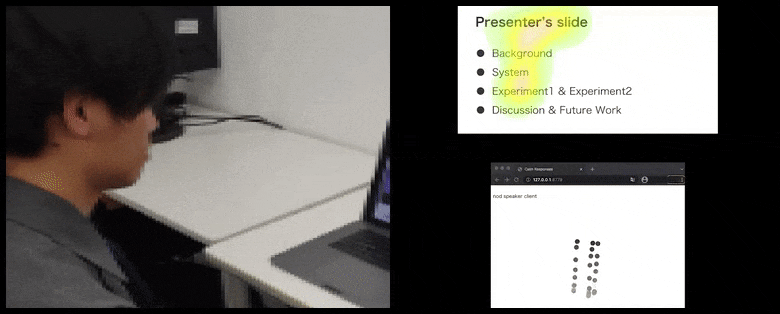
Con CalmResponses, la atención y el asentimiento del usuario se agregan a un grupo de retroalimentación de la audiencia y se traducen en una representación visual que puede beneficiar al orador. Ver el video incrustado al final del artículo para más detalles y ejemplos. Fuente: https://www.youtube.com/watch?v=J_PhB4FCzk0
En muchas situaciones académicas, como conferencias en línea, los estudiantes pueden ser completamente invisibles para el orador, ya que no han activado sus cámaras debido a la autoconciencia sobre su fondo o apariencia actual. CalmResponses puede abordar este obstáculo espinoso para la retroalimentación del orador al informar lo que sabe sobre cómo el orador está mirando el contenido, y si están asintiendo, sin necesidad de que el espectador active su cámara.
El artículo se titula CalmResponses: Displaying Collective Audience Reactions in Remote Communication, y es un trabajo conjunto entre dos investigadores de UoT y uno de Carnegie Mellon.
Los autores ofrecen una demostración en vivo en la web, y han publicado el código fuente en GitHub.
El marco de CalmResponses
El interés de CalmResponses en el asentimiento, en lugar de otras posibles disposiciones de la cabeza, se basa en la investigación (alguna de la cual se remonta a la era de Darwin) que indica que más del 80% de todos los movimientos de cabeza de los oyentes están compuestos por asentimiento (incluso cuando están expresando desacuerdo). Al mismo tiempo, los movimientos de la mirada han demostrado ser muy numerosos estudios un índice confiable de interés o compromiso.
CalmResponses se implementa con HTML, CSS y JavaScript, y comprende tres subsistemas: un cliente de audiencia, un cliente de orador y un servidor. El cliente de audiencia pasa los datos de mirada o movimiento de cabeza del usuario desde la cámara web a través de WebSockets sobre la plataforma de aplicación en la nube Heroku.

El asentimiento de la audiencia se visualiza en el lado derecho en un movimiento animado bajo CalmResponses. En este caso, la visualización del movimiento está disponible no solo para el orador, sino para toda la audiencia. Fuente: https://arxiv.org/pdf/2204.02308.pdf
Para la sección de seguimiento de la mirada del proyecto, los investigadores utilizaron WebGazer, un marco de seguimiento de mirada basado en JavaScript y ligero que puede ejecutarse con baja latencia directamente desde un sitio web (ver enlace anterior para la implementación web de los investigadores).
Dado que la necesidad de una implementación simple y una reconocimiento de respuesta agregada supera la necesidad de alta precisión en la estimación de mirada y pose, los datos de entrada de pose se suavizan según los valores medios antes de ser considerados para la estimación de respuesta general.
La acción de asentimiento se evalúa a través de la biblioteca de JavaScript clmtrackr, que ajusta modelos faciales a caras detectadas en imágenes o videos a través de desplazamiento de puntos de referencia regularizado. Con fines de economía y baja latencia, solo se monitorea activamente la marca detectada para la nariz, ya que esto es suficiente para rastrear acciones de asentimiento.
El movimiento de la punta de la nariz del usuario crea un rastro que contribuye al grupo de respuesta de la audiencia relacionada con el asentimiento, visualizado de manera agregada para todos los participantes.
Mapa de calor
Mientras que la actividad de asentimiento se representa mediante puntos dinámicos en movimiento (ver imágenes arriba y video al final), la atención visual se informa en términos de un mapa de calor que muestra al orador y la audiencia dónde se centra el locus general de atención en la pantalla de presentación compartida o el entorno de videoconferencia.

Todos los participantes pueden ver dónde se centra la atención general del usuario. El artículo no menciona si esta funcionalidad está disponible cuando el usuario puede ver una ‘galería’ de otros participantes, lo que podría revelar un enfoque engañoso en un participante en particular, por varias razones.
Pruebas
Se formularon dos entornos de prueba para CalmResponses en la forma de un estudio de ablation tácito, utilizando tres conjuntos variados de circunstancias: en ‘Condición B’ (línea de base), los autores replicaron una conferencia en línea típica de estudiantes, donde la mayoría de los estudiantes mantuvieron sus cámaras web apagadas, y el orador no tenía la capacidad de ver las caras de la audiencia; en ‘Condición CR-E’, el orador podía ver la retroalimentación de la mirada (mapas de calor); en ‘Condición CR-N’, el orador podía ver tanto la actividad de asentimiento como la de mirada de la audiencia.
El primer escenario experimental comprendió la condición B y la condición CR-E; el segundo comprendió la condición B y la condición CR-N. Se obtuvo retroalimentación de los oradores y la audiencia.
En cada experimento, se evaluaron tres factores: evaluación objetiva y subjetiva de la presentación (incluyendo un cuestionario de autoinforme del orador sobre sus sentimientos sobre cómo fue la presentación); el número de eventos de ‘habla de relleno’, indicativo de inseguridad y prevaricación momentánea; y comentarios cualitativos. Estos criterios son comunes estimadores de la calidad del habla y la ansiedad del orador.
El grupo de prueba consistió en 38 personas de entre 19 y 44 años, que comprendían 29 hombres y nueve mujeres con una edad promedio de 24,7, todos japoneses o chinos, y todos fluentes en japonés. Se dividieron aleatoriamente en cinco grupos de 6-7 participantes, y ninguno de los sujetos se conocía personalmente.
Las pruebas se realizaron en Zoom, con cinco oradores que dieron presentaciones en el primer experimento y seis en el segundo.

Condiciones de relleno marcadas como cajas naranjas. En general, el contenido de relleno disminuyó en proporción razonable a la retroalimentación aumentada de la audiencia del sistema.
Los investigadores observan que la reducción de relleno de un orador fue notable, y que en ‘Condición CR-N’, el orador rara vez pronunció frases de relleno. Ver el artículo para los resultados muy detallados y granulares informados; sin embargo, los resultados más marcados fueron en la evaluación subjetiva de los oradores y los participantes de la audiencia.
Los comentarios de la audiencia incluyeron:
‘Me sentí involucrado en las presentaciones” [AN2], “No estaba seguro de que los discursos de los oradores mejoraran, pero sentí una sensación de unidad de la visualización de los movimientos de cabeza de los demás.’ [AN6]
‘No estaba seguro de que los discursos de los oradores mejoraran, pero sentí una sensación de unidad de la visualización de los movimientos de cabeza de los demás.’
Los investigadores observan que el sistema introduce una nueva especie de pausa artificial en la presentación del orador, ya que el orador tiende a referirse al sistema visual para evaluar la retroalimentación de la audiencia antes de proceder.
También observan un tipo de ‘efecto de bata blanca’, difícil de evitar en circunstancias experimentales, donde algunos participantes se sintieron limitados por las posibles implicaciones de seguridad de ser monitoreados para datos biométricos.
Conclusión
Una ventaja notable en un sistema como este es que todas las tecnologías no estándar necesarias para este enfoque desaparecen completamente después de su uso. No hay plugins de navegador residuales que deban desinstalarse, o que puedan generar dudas en la mente de los participantes sobre si deben permanecer en sus respectivos sistemas; y no hay necesidad de guiar a los usuarios a través del proceso de instalación (aunque el marco web requiere un minuto o dos de calibración inicial por parte del usuario), o de navegar la posibilidad de que los usuarios no tengan los permisos adecuados para instalar software local, incluidos complementos y extensiones basados en el navegador.
Aunque los movimientos faciales y oculares evaluados no son tan precisos como podrían ser en circunstancias en las que se utilizan marcos de aprendizaje automático locales dedicados (como la serie YOLO), este enfoque casi sin fricción para la evaluación de la audiencia proporciona la precisión adecuada para el análisis de sentimiento y postura general en escenarios de videoconferencia típicos. Por encima de todo, es muy barato.
Ver el video del proyecto asociado a continuación para más detalles y ejemplos.
Publicado por primera vez el 11 de abril de 2022.












