Ángulo de Anderson
Un método de datos forenses para una nueva generación de deepfakes

Aunque la creación de deepfakes de personas privadas se ha convertido en una preocupación pública creciente y está siendo cada vez más prohibida en varias regiones, en realidad, probar que un modelo creado por un usuario, como uno que permite la venganza pornográfica, fue entrenado específicamente en imágenes de una persona en particular, sigue siendo extremadamente desafiante.
Para poner el problema en contexto: un elemento clave de un ataque de deepfake es falsamente afirmar que una imagen o video muestra a una persona específica. Simplemente afirmar que alguien en un video es la identidad #A, en lugar de solo un parecido, es suficiente para crear daño, y no se necesita inteligencia artificial en este escenario.
Sin embargo, si un atacante genera imágenes o videos de inteligencia artificial utilizando modelos entrenados en datos reales de personas, los sistemas de reconocimiento facial de los motores de búsqueda y las redes sociales vincularán automáticamente el contenido falso a la víctima, sin necesidad de nombres en publicaciones o metadatos. Los visuales generados por inteligencia artificial garantizan la asociación.
Cuanto más distintiva sea la apariencia de la persona, más inevitable se vuelve, hasta que el contenido fabricado aparece en búsquedas de imágenes y finalmente llega a la víctima.
Cara a cara
El medio más común de difusión de modelos enfocados en la identidad es actualmente a través de Adaptación de bajo rango (LoRA), donde el usuario entrena un pequeño número de imágenes durante unas horas contra los pesos de un modelo base mucho más grande, como Stable Diffusion (para imágenes estáticas, en su mayoría) o Hunyuan Video, para deepfakes de video.
Los objetivos más comunes de LoRAs, incluyendo la nueva generación de LoRAs basados en video, son celebridades femeninas, cuya fama las expone a este tipo de trato con menos crítica pública que en el caso de víctimas “desconocidas”, debido a la suposición de que tales obras derivadas están cubiertas bajo “uso justo” (al menos en EE. UU. y Europa).

Las celebridades femeninas dominan las listas de LoRA y Dreambooth en el portal civit.ai. El LoRA más popular actualmente tiene más de 66,000 descargas, lo que es considerable, considerando que este uso de la inteligencia artificial sigue siendo visto como una actividad “marginal”.
No hay un foro público similar para las víctimas no celebridades de deepfakes, que solo salen a la luz en los medios cuando se presentan casos de enjuiciamiento o las víctimas hablan en publicaciones populares.
Sin embargo, en ambos escenarios, los modelos utilizados para falsificar las identidades de los objetivos han “destilado” sus datos de entrenamiento tan completamente en el espacio latente del modelo que es difícil identificar las imágenes de origen que se utilizaron.
Si fuera posible hacerlo dentro de un margen de error aceptable, esto permitiría el enjuiciamiento de quienes comparten LoRAs, ya que no solo prueba la intención de falsificar la identidad de una persona en particular (es decir, la de una persona “desconocida” específica, incluso si el malhechor nunca la nombra durante el proceso de difamación), sino que también expone al que sube el contenido a cargos de infracción de derechos de autor, cuando corresponda.
Esto último sería útil en jurisdicciones donde la regulación legal de las tecnologías de deepfaking es deficiente o está rezagada.
Sobrexposición
El objetivo de entrenar un modelo base, como el modelo base de varios gigabytes que un usuario podría descargar de Hugging Face, es que el modelo se vuelva bien generalizado y maleable. Esto implica entrenarlo en un número adecuado de imágenes diversas y con ajustes adecuados, y finalizar el entrenamiento antes de que el modelo “se sobreadapte” a los datos.
Un modelo sobreadaptado ha visto los datos tantas veces (excesivas) durante el proceso de entrenamiento que tenderá a reproducir imágenes muy similares, lo que expone la fuente de los datos de entrenamiento.

La identidad ‘Ann Graham Lotz’ se puede reproducir casi perfectamente en el modelo Stable Diffusion V1.5. La reconstrucción es casi idéntica a los datos de entrenamiento (a la izquierda en la imagen de arriba). Fuente: https://arxiv.org/pdf/2301.13188
Sin embargo, los modelos sobreadaptados suelen ser descartados por sus creadores en lugar de distribuirse, ya que no son aptos para su propósito. Por lo tanto, esto es una “gangosa forense” poco probable. En cualquier caso, el principio se aplica más al entrenamiento costoso y de gran volumen de los modelos base, donde versiones múltiples de la misma imagen que han entrado en un conjunto de datos grande pueden hacer que ciertas imágenes de entrenamiento sean fáciles de invocar (ver imagen y ejemplo de arriba).
Las cosas son un poco diferentes en el caso de los modelos LoRA y Dreambooth (aunque Dreambooth ha caído en desgracia debido a sus grandes tamaños de archivo). Aquí, el usuario selecciona un número muy limitado de imágenes diversas de un sujeto y las utiliza para entrenar un LoRA.

A la izquierda, salida de un LoRA de video Hunyuan. A la derecha, los datos que hicieron posible la semejanza (imágenes utilizadas con el permiso de la persona representada).
Frecuentemente, el LoRA tendrá una palabra de activación entrenada, como [nombre de la celebridad]. Sin embargo, muy a menudo, el sujeto entrenado específicamente aparecerá en la salida generada incluso sin tales prompts, porque incluso un LoRA bien equilibrado (es decir, no sobreadaptado) está algo “fijado” en el material en el que se entrenó y tenderá a incluirlo en cualquier salida.
Esta predisposición, combinada con el número limitado de imágenes que son óptimas para un conjunto de datos LoRA, expone el modelo al análisis forense, como veremos.
Desenmascarando los datos
Estos asuntos se abordan en un nuevo artículo de Dinamarca, que ofrece una metodología para identificar imágenes de origen (o grupos de imágenes de origen) en un ataque de inferencia de membresía de caja negra (MIA). La técnica implica al menos en parte el uso de modelos personalizados entrenados para ayudar a exponer los datos de origen generando sus propios “deepfakes”:

Ejemplos de imágenes ‘falsas’ generadas por el nuevo enfoque, a niveles cada vez mayores de orientación de clasificador libre (CFG), hasta el punto de destrucción. Fuente: https://arxiv.org/pdf/2502.11619
Aunque el trabajo, titulado Ataques de inferencia de membresía para imágenes de rostro contra modelos de difusión latente afinados, es una contribución interesante a la literatura sobre este tema en particular, también es un artículo inaccesible y escrito de manera concisa que necesita una considerable decodificación. Por lo tanto, cubriremos al menos los principios básicos detrás del proyecto aquí y una selección de los resultados obtenidos.
En efecto, si alguien ajusta un modelo de inteligencia artificial en tus imágenes, el método de los autores puede ayudar a probarlo buscando signos de memorización en las imágenes generadas del modelo.
En primer lugar, un modelo de inteligencia artificial objetivo se ajusta en un conjunto de datos de imágenes de rostro, lo que lo hace más probable que reproduzca detalles de esas imágenes en sus salidas. Posteriormente, se entrena un modo de ataque de clasificador utilizando imágenes de inteligencia artificial generadas por el modelo objetivo como ejemplos “positivos” (miembros sospechosos del conjunto de entrenamiento) y otras imágenes de un conjunto de datos diferente como ejemplos “negativos” (no miembros).
Al aprender las sutiles diferencias entre estos grupos, el modelo de ataque puede predecir si una imagen determinada fue parte del conjunto de datos original utilizado para ajustar el modelo objetivo.
El ataque es más efectivo en casos donde el modelo de inteligencia artificial se ha ajustado extensivamente, lo que significa que cuanto más se especialice el modelo, más fácil es detectar si ciertas imágenes se utilizaron. Esto se aplica generalmente a los LoRAs diseñados para recrear a celebridades o personas privadas.
Los autores también encontraron que agregar marcas de agua visibles a las imágenes de entrenamiento facilita la detección, aunque las marcas de agua ocultas no ayudan mucho.
Impresionantemente, el enfoque se prueba en un entorno de caja negra, lo que significa que funciona sin acceso a los detalles internos del modelo, solo a sus salidas.
El método llegado es computacionalmente intenso, como admiten los autores; sin embargo, el valor de este trabajo está en indicar la dirección para investigaciones adicionales y en demostrar que los datos pueden extraerse de manera realista a una tolerancia aceptable; por lo tanto, dado su carácter seminal, no necesita ejecutarse en un teléfono inteligente en esta etapa.
Método/Datos
Se utilizaron varios conjuntos de datos de la Universidad Técnica de Dinamarca (DTU, la institución anfitriona de los tres investigadores) en el estudio, para ajustar el modelo objetivo y para entrenar y probar el modo de ataque.
Los conjuntos de datos utilizados se derivaron de DTU Orbit:
DseenDTU El conjunto de imágenes base.
DDTU Imágenes extraídas de DTU Orbit.
DseenDTU Una partición de DDTU utilizada para ajustar el modelo objetivo.
DunseenDTU Una partición de DDTU que no se utilizó para ajustar ningún modelo de generación de imágenes y se utilizó en su lugar para probar o entrenar el modelo de ataque.
wmDseenDTU Una partición de DDTU con marcas de agua visibles utilizada para ajustar el modelo objetivo.
hwmDseenDTU Una partición de DDTU con marcas de agua ocultas utilizada para ajustar el modelo objetivo.
DgenDTU Imágenes generadas por un modelo de difusión latente (LDM) que se ha ajustado en el conjunto de imágenes DseenDTU.
Los conjuntos de datos utilizados para ajustar el modelo objetivo consisten en pares de imagen-texto con subtítulos proporcionados por el modelo de subtítulos BLIP (quizás no por casualidad, uno de los modelos más populares sin censura en la comunidad de inteligencia artificial casual).
BLIP se configuró para anteponer la frase ‘una imagen de DTU de un’ a cada descripción.
Además, se utilizaron varios conjuntos de datos de la Universidad de Aalborg (AAU) en las pruebas, todos derivados del corpus VBN de AAU:
DAAU Imágenes extraídas de AAU vbn.
DseenAAU Una partición de DAAU utilizada para ajustar el modelo objetivo.
DunseenAAU Una partición de DAAU que no se utilizó para ajustar ningún modelo de generación de imágenes y se utilizó en su lugar para probar o entrenar el modelo de ataque.
DgenAAU Imágenes generadas por un LDM ajustado en el conjunto de imágenes DseenAAU.
Equivalentemente a los conjuntos anteriores, se utilizó la frase ‘una imagen de AAU de un’. Esto garantizó que todas las etiquetas en el conjunto de datos de DTU siguieran el formato ‘una imagen de DTU de un (…)’, lo que refuerza las características básicas del conjunto de datos durante el ajuste.
Pruebas
Se realizaron múltiples experimentos para evaluar cómo funcionaban los ataques de inferencia de membresía contra el modelo objetivo. Cada prueba apuntó a determinar si era posible llevar a cabo un ataque exitoso dentro del esquema mostrado a continuación, donde el modelo objetivo se ajusta en un conjunto de datos de imágenes obtenido sin autorización.

Esquema para el enfoque.
Con el modelo ajustado consultado para generar imágenes de salida, estas imágenes se utilizan como ejemplos positivos para entrenar el modelo de ataque, mientras que se incluyen imágenes adicionales no relacionadas como ejemplos negativos.
El modelo de ataque se entrena utilizando aprendizaje supervisado y se prueba en nuevas imágenes para determinar si fueron originalmente parte del conjunto de datos utilizado para ajustar el modelo objetivo. Para evaluar la precisión del ataque, se reserva el 15% de los datos de prueba para validación.
Como el modelo objetivo se ajusta en un conjunto de datos conocido, el estado de membresía real de cada imagen ya está establecido al crear los datos de entrenamiento para el modelo de ataque. Este entorno controlado permite una evaluación clara de la efectividad del modelo de ataque para distinguir entre imágenes que fueron parte del conjunto de datos de ajuste y aquellas que no lo fueron.
Para estas pruebas, se utilizó el modelo Stable Diffusion V1.5. Aunque este modelo es bastante antiguo y se utiliza mucho en la investigación debido a la necesidad de pruebas consistentes y al extenso corpus de trabajos previos que lo utilizan, este es un caso de uso apropiado; V1.5 siguió siendo popular para la creación de LoRAs en la comunidad de aficionados a Stable Diffusion durante mucho tiempo, a pesar de múltiples versiones posteriores, y incluso a pesar del surgimiento de Flux – porque el modelo es completamente sin censura.
El modelo de ataque de los investigadores se basó en Resnet-18, con los pesos preentrenados del modelo retenidos. La capa de 1000 neuronas de ResNet-18 se reemplazó con una capa completamente conectada con dos neuronas. La pérdida de entrenamiento se utilizó cruzada y se utilizó el optimizador Adam.
Para cada prueba, el modelo de ataque se entrenó cinco veces utilizando diferentes semillas aleatorias para calcular intervalos de confianza del 95% para las métricas clave. Se utilizó la clasificación zero-shot con el modelo CLIP como línea de base.
(Tenga en cuenta que la tabla de resultados principales original en el artículo es concisa y difícil de entender. Por lo tanto, la he reformulado a continuación de una manera más fácil de entender. Haga clic en la imagen para verla en mejor resolución)
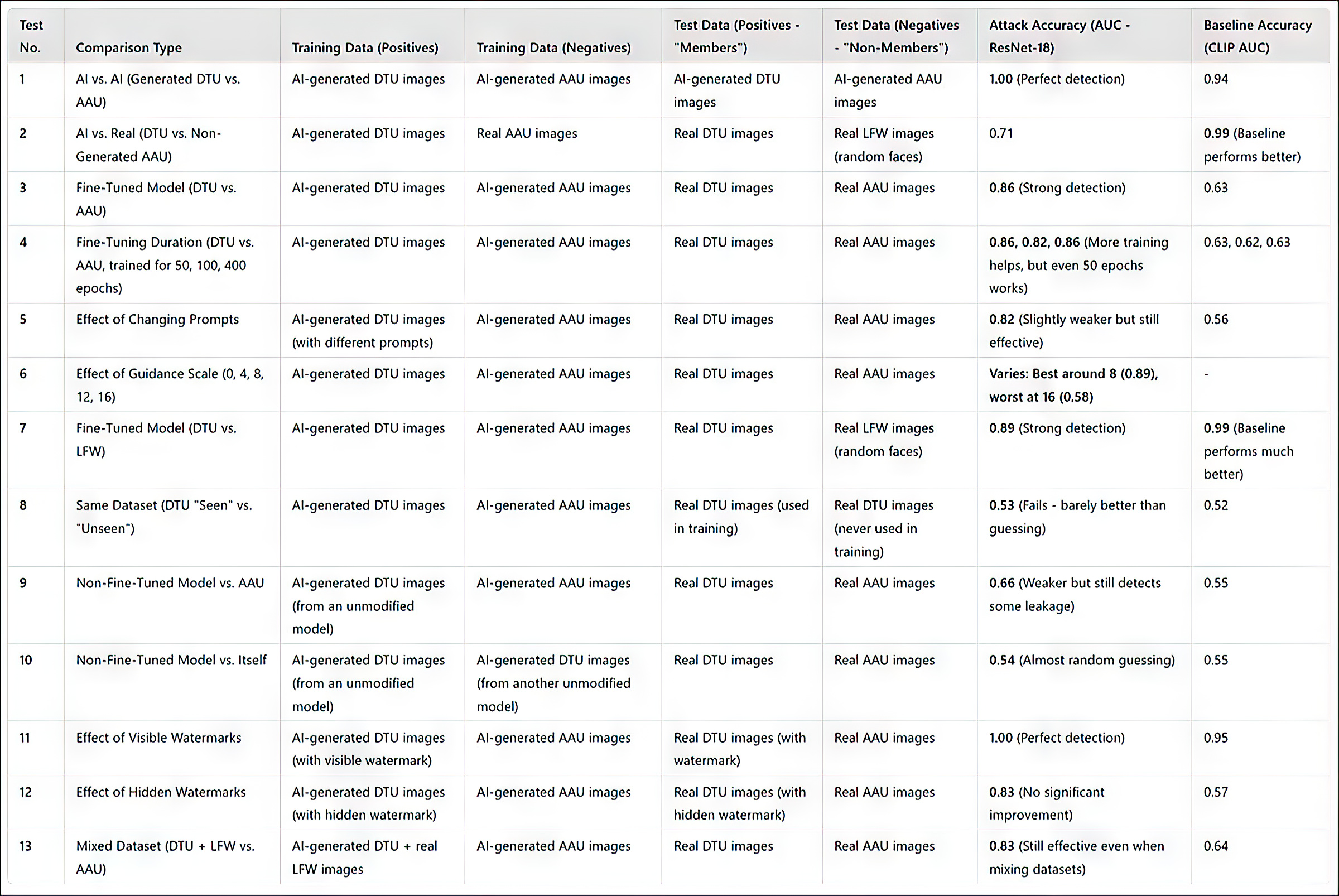
Resumen de los resultados de todas las pruebas. Haga clic en la imagen para ver una resolución más alta
El método de ataque de los investigadores resultó ser más efectivo cuando se dirigía a modelos ajustados, particularmente aquellos entrenados en un conjunto específico de imágenes, como el rostro de una persona. Sin embargo, aunque el ataque puede determinar si un conjunto de datos se utilizó, lucha por identificar imágenes individuales dentro de ese conjunto de datos.
En términos prácticos, lo último no es necesariamente un obstáculo para utilizar un enfoque como este de manera forense; mientras que hay relativamente poco valor en establecer que un conjunto de datos famoso como ImageNet se utilizó en un modelo, un atacante a una persona privada (no una celebridad) tenderá a tener muy poca elección de datos de origen y necesitará explotar completamente los grupos de datos disponibles, como álbumes de redes sociales y otras colecciones en línea. Estos efectivamente crean un ‘hash’ que puede ser descubierto por los métodos descritos.
El artículo señala que otra forma de mejorar la precisión es utilizar imágenes generadas por inteligencia artificial como ‘no miembros’, en lugar de confiar únicamente en imágenes reales. Esto evita tasas de éxito artificialmente altas que podrían engañar los resultados.
Un factor adicional que influye significativamente en la detección, señalan los autores, es la marca de agua. Cuando las imágenes de entrenamiento contienen marcas de agua visibles, el ataque se vuelve muy efectivo, mientras que las marcas de agua ocultas ofrecen poca o ninguna ventaja.

La figura de la derecha muestra la marca de agua ‘oculta’ real utilizada en las pruebas.
Finalmente, el nivel de orientación en la generación de texto a imagen también juega un papel, con el equilibrio ideal encontrado en una escala de orientación de alrededor de 8. Incluso cuando no se utiliza un prompt directo, un modelo ajustado sigue tendiendo a producir salidas que se asemejan a sus datos de entrenamiento, lo que refuerza la efectividad del ataque.
Conclusión
Es una lástima que este artículo interesante se haya escrito de una manera tan inaccesible, ya que debería ser de interés para defensores de la privacidad y investigadores de inteligencia artificial casuales por igual.
Aunque los ataques de inferencia de membresía pueden resultar ser una herramienta forense interesante y fructífera, es más importante, quizás, que esta rama de investigación desarrolle principios generales aplicables, para evitar que termine en el mismo juego de “golpea y corre” que ha ocurrido con la detección de deepfakes en general, cuando la publicación de un modelo más nuevo afecta negativamente la detección y sistemas forenses similares.
Como hay alguna evidencia de un principio rector de nivel superior que se ha aclarado en esta nueva investigación, podemos esperar ver más trabajo en esta dirección.
Publicado por primera vez el viernes 21 de febrero de 2025












