Κυβερνοασφάλεια
Γιατί οι επιθέσεις εικόνων ανταγωνιστών δεν είναι żουστέια
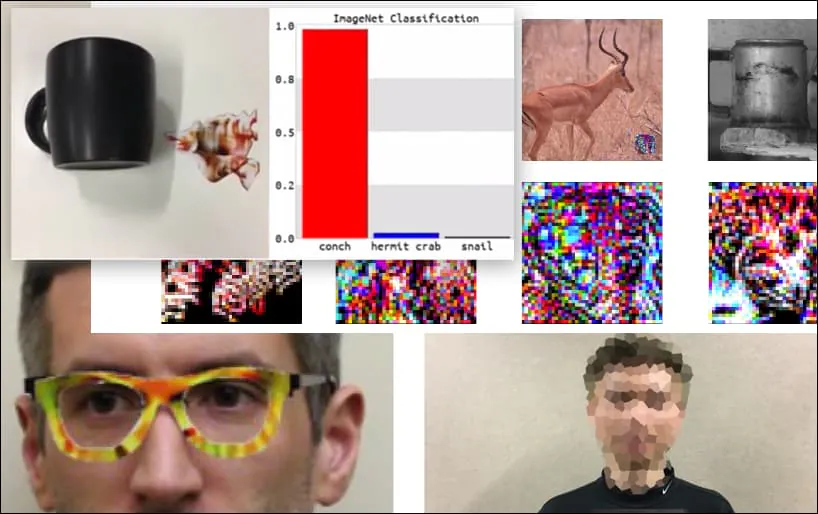
Η επίθεση σε συστήματα αναγνώρισης εικόνων με προσεκτικά σχεδιασμένες εικόνες ανταγωνιστών θεωρήθηκε ένα αστείο αλλά ασήμαντο concept τους τελευταίους πέντε χρόνια. Ωστόσο, νέα έρευνα από την Αυστραλία υποδηλώνει ότι η άνετη χρήση πολύ δημοφιλών συνόλων δεδομένων εικόνων για εμπορικά projects AI μπορεί να δημιουργήσει ένα νέο μόνιμο πρόβλημα ασφαλείας.
Για ένα paar χρόνια τώρα, μια ομάδα ακαδημαϊκών στο Πανεπιστήμιο του Αδελαΐδας προσπαθεί να εξηγήσει κάτι πολύ σημαντικό για το μέλλον των συστημάτων αναγνώρισης εικόνων με βάση το AI.
Είναι κάτι που θα ήταν δύσκολο (και πολύ ακριβό) να διορθωθεί τώρα, και το οποίο θα ήταν αισχρότατα ακριβό να θεραπεύσει μια φορά που οι τρέχουσες τάσεις στην έρευνα αναγνώρισης εικόνων θα έχουν αναπτυχθεί πλήρως σε εμπορικές και βιομηχανικές αναπτύξεις σε 5-10 χρόνια.
Πριν να το εξηγήσουμε, ας δούμε ένα λουλούδι που ταξινομείται ως Πρόεδρος Μπαράκ Ομπάμα, από ένα από τα έξι βίντεο που η ομάδα έχει δημοσιεύσει στη σελίδα του project:
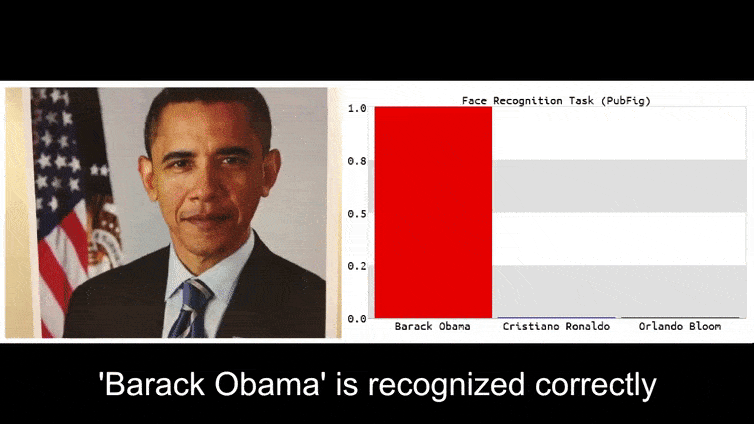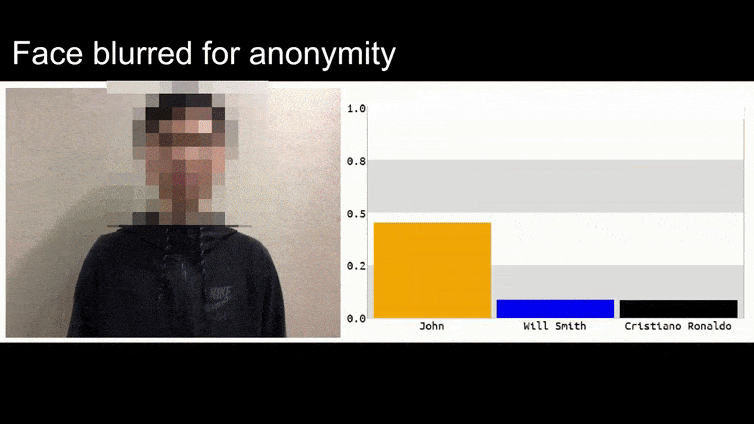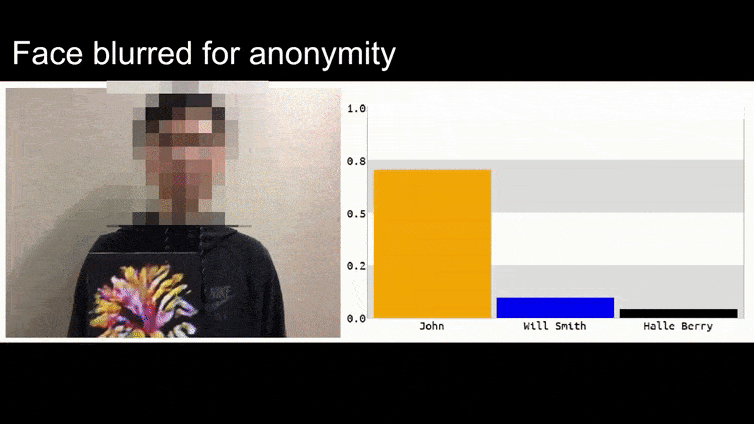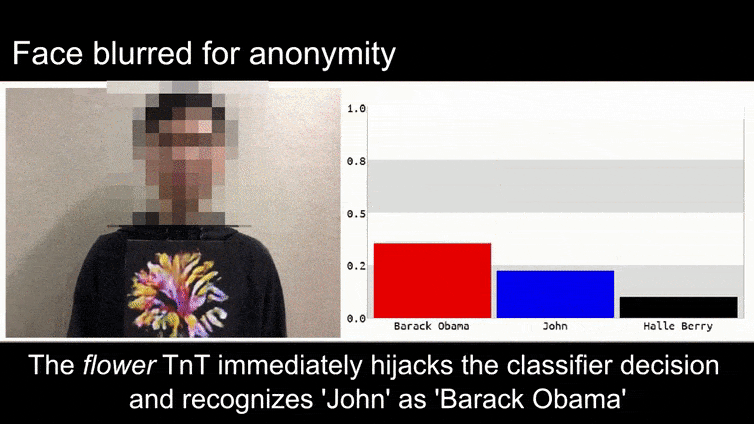
Πηγή: https://www.youtube.com/watch?v=Klepca1Ny3c
Στην παραπάνω εικόνα, ένα σύστημα αναγνώρισης προσώπου που ξέρει rõ πώς να αναγνωρίζει τον Μπαράκ Ομπάμα, αποτυγχάνει να αναγνωρίσει ότι ένας ανώνυμος άνθρωπος που κρατάει μια σχεδιασμένη, εκτυπωμένη εικόνα ανταγωνιστή ενός λουλουδιού είναι ο Μπαράκ Ομπάμα. Το σύστημα δεν ενδιαφέρεται ότι το “ψεύτικο πρόσωπο” είναι στο στήθος του ανθρώπου, αντί να είναι στους ώμους του.
Αν και είναι εντυπωσιακό ότι οι ερευνητές έχουν能够 να επιτύχουν αυτό το είδος αναγνώρισης ταυτότητας με τη δημιουργία μιας συνεκτικής εικόνας (ένα λουλούδι) αντί για το συνηθισμένο τυχαίο θόρυβο, φαίνεται ότι αστείες εκμεταλλεύσεις σαν αυτή εμφανίζονται αρκετά συχνά στην έρευνα ασφαλείας για την όραση υπολογιστή. Για παράδειγμα, τα γυαλιά με περίεργο σχέδιο που μπορούσαν να απομακρύνουν την αναγνώριση προσώπου το 2016, ή ειδικά σχεδιασμένες εικόνες ανταγωνιστών που προσπαθούν να ξαναγράψουν σημάδια δρόμου.
Αν σας ενδιαφέρει, το μοντέλο Convolutional Neural Network (CNN) που επιτίθεται στο παραπάνω παράδειγμα είναι VGGFace (VGG-16), εκπαιδευμένο στο dataset PubFig του Πανεπιστημίου Κολούμπια. Άλλα δείγματα επιθέσεων που αναπτύχθηκαν από τους ερευνητές χρησιμοποιούσαν διαφορετικά πόρους σε διαφορετικές συνδυασίες.

Ένα πληκτρολόγιο ταξινομείται ως κογχύλι, σε ένα μοντέλο WideResNet50 στο ImageNet. Οι ερευνητές έχουν επίσης διασφαλίσει ότι το μοντέλο δεν έχει προκατάληψη προς τα κογχύλια. Δείτε το πλήρες βίντεο για επεκτάσεις και πρόσθετες αποδείξεις στο https://www.youtube.com/watch?v=dhTTjjrxIcU
Η αναγνώριση εικόνων ως một αναδυόμενη διαδικασία επίθεσης
Οι πολλές εντυπωσιακές επιθέσεις που περιγράφουν και εικονογραφούν οι ερευνητές δεν είναι κριτικές σε συγκεκριμένα σύνολα δεδομένων ή συγκεκριμένες αρχιτεκτονικές μηχανικής μάθησης που τις χρησιμοποιούν. Ούτε μπορούν να απομακρυνθούν εύκολα με την αλλαγή συνόλων δεδομένων ή μοντέλων, την επαναεκπαίδευση μοντέλων, ή οποιαδήποτε άλλη “εύκολη” θεραπεία που κάνει τους praktikous της ML να Ridicule τις σποραδικές αποδείξεις αυτού του είδους trickery.
Αντίθετα, οι εκμεταλλεύσεις της ομάδας του Αδελαΐδας εξηγούν μια κεντρική αδυναμία στην整个 τρέχουσα αρχιτεκτονική της ανάπτυξης AI αναγνώρισης εικόνων, μια αδυναμία που θα μπορούσε να εκθέσει πολλά μελλοντικά συστήματα αναγνώρισης εικόνων σε ευκολική χειραγώγηση από επιτιθέμενους και να θέσει οποιαδήποτε μελλοντική αμυντική μέτρα σε δυσχερή θέση.
Φανταστείτε τις τελευταίες επιθέσεις εικόνων ανταγωνιστών (όπως το λουλούδι παραπάνω) να προστίθενται ως “zero-day exploits” στα συστήματα ασφαλείας του μέλλοντος, όπως και τα τρέχοντα anti-malware και antivirus frameworks ενημερώνουν τις ορισμοί ιών κάθε μέρα.
Η δυνατότητα για νέες επιθέσεις εικόνων ανταγωνιστών θα ήταν ατελείωτη, επειδή η θεμελιώδης αρχιτεκτονική του συστήματος δεν προέβλεψε προβλήματα κατά την ροή, όπως συνέβη με το διαδίκτυο, το Millennium Bug και την πύργο της Πίζας.
Ποια είναι, τότε, ο τρόπος με τον οποίο ρίχνουμε το σκηνικό για αυτό;
Λήψη δεδομένων για μια επίθεση
Εικόνες ανταγωνιστών όπως το παράδειγμα “λουλούδι” παραπάνω παράγονται με την πρόσβαση στα σύνολα δεδομένων εικόνων που εκπαιδεύουν τα μοντέλα υπολογιστή. Δεν χρειάζεστε “πривιλεγированную” πρόσβαση στα δεδομένα εκπαίδευσης (ή αρχιτεκτονικές μοντέλων),既然 τα πιο δημοφιλή σύνολα δεδομένων (και πολλά εκπαιδευμένα μοντέλα) είναι ευρέως διαθέσιμα σε ένα robust και συνεχώς ενημερωμένο torrent scene.
Για παράδειγμα, το γίγας του dataset της όρασης υπολογιστή, το ImageNet, είναι διαθέσιμο στο Torrent σε όλες τις πολλές ιтерασιόν του, παρακάμπτοντας τις συνήθεις περιορισμούς του, και καθιστώντας διαθέσιμα κρίσιμα δευτερεύοντα στοιχεία, όπως σύνολα επικύρωσης.

Πηγή: https://academictorrents.com
Αν έχετε τα δεδομένα, μπορείτε (όπως παρατηρούν οι ερευνητές του Αδελαΐδας) να “reverse-engineer” οποιοδήποτε δημοφιλές σύνολο δεδομένων, όπως CityScapes, ή CIFAR.
Στην περίπτωση του PubFig, του συνόλου δεδομένων που επέτρεψε το “λουλούδι του Ομπάμα” στο προηγούμενο παράδειγμα, το Πανεπιστήμιο Κολούμπια έχει αντιμετωπίσει μια αυξανόμενη τάση σε προβλήματα πνευματικών δικαιωμάτων γύρω από την αναδιανομή συνόλων δεδομένων εικόνων,指示ζοντας στους ερευνητές πώς να αναπαράγουν το σύνολο δεδομένων μέσω επιμελημένων συνδέσμων, αντί να το κάνουν απευθείας διαθέσιμο, παρατηρώντας ‘Αυτό φαίνεται να είναι ο τρόπος με τον οποίο άλλες μεγάλες βάσεις δεδομένων του ιστου似乎 να εξελίσσονται’.
Στις περισσότερες περιπτώσεις, αυτό δεν είναι απαραίτητο: το Kaggle εκτιμά ότι τα δέκα πιο δημοφιλή σύνολα δεδομένων εικόνων στην όραση υπολογιστή είναι: CIFAR-10 και CIFAR-100 (και τα δύο διαθέσιμα κατευθείαν); CALTECH-101 και 256 (και τα δύο διαθέσιμα, και και τα δύο τώρα διαθέσιμα ως torrents); MNIST (επίσημα διαθέσιμα, επίσης σε torrents); ImageNet (βλ. παραπάνω); Pascal VOC (διαθέσιμο, επίσης σε torrents); MS COCO (διαθέσιμο, και σε torrents); Sports-1M (διαθέσιμο); και YouTube-8M (διαθέσιμο).
Αυτή η διαθεσιμότητα αντιπροσωπεύει επίσης το ευρύτερο φάσμα διαθέσιμων συνόλων δεδομένων εικόνων υπολογιστή,既然 η αφάνεια είναι ο θάνατος σε μια κουλτούρα ανοιχτής πηγής “δημοσίευσης ή αφανισμού”.
Σε κάθε περίπτωση, η σπανιότητα διαχειρίσιμων νέων συνόλων δεδομένων, το υψηλό κόστος ανάπτυξης συνόλων εικόνων, η εξάρτηση από “παλιά αγαπημένα” και η τάση να απλώς προσαρμόσουν παλαιότερα σύνολα δεδομένων جميع αυτά τα προβλήματα που περιγράφονται στην καινούργια εργασία του Αδελαΐδας.
Τυπικές κριτικές μεθόδων επιθέσεων εικόνων ανταγωνιστών
Η πιο συχνή και επιμοντική κριτική των μηχανικών μηχανικής μάθησης κατά της αποτελεσματικότητας της τελευταίας μεθόδου επιθέσεων εικόνων ανταγωνιστών είναι ότι η επίθεση είναι ειδική σε ένα συγκεκριμένο σύνολο δεδομένων, ένα συγκεκριμένο μοντέλο, ή και τα δύο; ότι δεν είναι “γενικευμένη” σε άλλα συστήματα; και, κατά συνέπεια, αντιπροσωπεύει μόνο μια τριβή απειλή.
Η δεύτερη πιο συχνή καταγγελία είναι ότι η επίθεση εικόνων ανταγωνιστών είναι ‘λευκή κουτί’, που σημαίνει ότι θα χρειαζόταντε άμεση πρόσβαση στο περιβάλλον εκπαίδευσης ή δεδομένων. Αυτό είναι πραγματικά ένα απίθανο σενάριο, σε meisten περιπτώσεις – για παράδειγμα, αν ήθελες να εκμεταλλευτείς τη διαδικασία εκπαίδευσης για τα συστήματα αναγνώρισης προσώπου της Μητροπολιτικής Αστυνομίας του Λονδίνου, θα έπρεπε να hackαρεις τον εαυτό σου στο NEC, είτε με μια κονσόλα είτε με ένα άξονα.
Το μακροπρόθεσμο “DNA” των δημοφιλών συνόλων δεδομένων εικόνων υπολογιστή
Σχετικά με την πρώτη κριτική, πρέπει να λάβουμε υπόψη ότι δεν μόνο ένα μικρό χέρι συνόλων δεδομένων εικόνων υπολογιστή κυριαρχεί στη βιομηχανία ανά τομέα έτος-προς-έτος (π.χ. ImageNet για πολλαπλά είδη αντικειμένων, CityScapes για σκηνές οδήγησης, και FFHQ για αναγνώριση προσώπου); αλλά επίσης ότι, ως απλά αναγνωρισμένα δεδομένα εικόνων, είναι “πλατφόρμα-αγνόητα” και υψηλά μεταφερόμενα.
Ανάλογα με τις ικανότητές του, οποιοδήποτε αρχιτεκτονικό σύστημα αναγνώρισης εικόνων θα βρει κάποια χαρακτηριστικά αντικειμένων και κατηγοριών στο σύνολο δεδομένων ImageNet. Κάποια αρχιτεκτονικά μπορεί να βρουν περισσότερα χαρακτηριστικά από άλλα, ή να κάνουν πιο χρήσιμες συνδέσεις από άλλα, αλλά όλα θα βρουν τουλάχιστον τα υψηλότερα χαρακτηριστικά:

Δεδομένα ImageNet, με τον ελάχιστο ικανό αριθμό σωστών ταυτοποιήσεων – ‘υψηλά’ χαρακτηριστικά.
Είναι αυτά τα “υψηλά” χαρακτηριστικά που διακρίνουν και “αποτυπώνουν” ένα σύνολο δεδομένων, και τα οποία είναι τα αξιόπιστα “γάντζοι” στα οποία να κρεμάσετε μια μακροπρόθεσμη μεθοδολογία επιθέσεων εικόνων ανταγωνιστών που μπορεί να διασχίσει διαφορετικά συστήματα, και να μεγαλώσει σε συνδυασμό με το “παλιό” σύνολο δεδομένων καθώς το τελευταίο διατηρείται σε νέα έρευνα και προϊόντα.
Μια πιο σύνθετη αρχιτεκτονική θα παράγει πιο ακριβείς και λεπτομερείς ταυτοποιήσεις, χαρακτηριστικά και κατηγορίες:

Ωστόσο, όσο περισσότερο μια επίθεση εικόνων ανταγωνιστών εξαρτάται από αυτά τα χαμηλότερα χαρακτηριστικά (π.χ. “Νέος Λευκός Άνδρας” αντί για “Πρόσωπο”), τόσο λιγότερο αποτελεσματική θα είναι σε διασταυρούμενες ή μεταγενέστερες αρχιτεκτονικές που χρησιμοποιούν διαφορετικές εκδόσεις του αρχικού συνόλου δεδομένων – όπως ένα υποσύνολο ή φιλτράρισμα συνόλου, όπου πολλά από τα αρχικά δεδομένα του πλήρους συνόλου δεν είναι παρόντα:

Επιθέσεις εικόνων ανταγωνιστών σε “μηδενικά”, προ-εκπαιδευμένα μοντέλα
Τι γίνεται με τις περιπτώσεις όπου απλά κατεβάζετε ένα προ-εκπαιδευμένο μοντέλο που αρχικά εκπαιδεύτηκε σε ένα πολύ δημοφιλές σύνολο δεδομένων, και του δίνετε完全 νέες δεδομένα;
Το μοντέλο έχει ήδη εκπαιδευτεί στο (για παράδειγμα) ImageNet, και όλα που μένουν είναι τα βαρίδια, τα οποία μπορεί να χρειάστηκαν εβδομάδες ή μήνες για να εκπαιδευτούν, και είναι τώρα έτοιμα να σας βοηθήσουν να αναγνωρίσετε παρόμοια αντικείμενα με αυτά που υπήρχαν στο αρχικό (τώρα απουσιάζον) δεδομένα.

Με τα αρχικά δεδομένα αφαιρεμένα από την αρχιτεκτονική εκπαίδευσης, ότι μένει είναι η ‘πredisposition’ του μοντέλου να ταξινομεί αντικείμενα με τον τρόπο που αρχικά μάθει να κάνει, το οποίο θα προκαλέσει πολλά από τα αρχικά ‘σημάδια’ να αναμορφωθούν και να γίνουν ξανά ευάλωτα στις ίδιες παλιές μεθόδους επιθέσεων εικόνων ανταγωνιστών.
Αυτά τα βαρίδια είναι πολύτιμα. Χωρίς τα δεδομένα ή τα βαρίδια, έχετε ουσιαστικά μια κενή αρχιτεκτονική με κανένα δεδομένο. Θα πρέπει να την εκπαιδεύσετε από την αρχή, με μεγάλο κόστος χρόνου και υπολογιστικών πόρων, όπως και οι αρχικοί συγγραφείς (πιθανότατα σε πιο ισχυρό υλικό και με υψηλότερο προϋπολογισμό από αυτό που έχετε διαθέσιμο).
Το πρόβλημα είναι ότι τα βαρίδια είναι ήδη khá καλά διαμορφωμένα και ανθεκτικά. Αν και θα προσαρμοστούν κάπως στην εκπαίδευση, θα συμπεριφερθούν παρόμοια στα νέα δεδομένα σας όπως και στα αρχικά δεδομένα, παράγοντας χαρακτηριστικά που ένα σύστημα επιθέσεων εικόνων ανταγωνιστών μπορεί να κλείσει ξανά.
Στο μακροπρόθεσμο, αυτό επίσης διατηρεί το “DNA” των συνόλων δεδομένων εικόνων υπολογιστή που είναι δώδεκα ή περισσότερα χρόνια παλιά, και μπορεί να έχουν περάσει από μια αξιοσημείωτη εξέλιξη από ανοιχτές πηγές μέχρι εμπορικές αναπτύξεις – ακόμη και όπου τα αρχικά δεδομένα εκπαίδευσης είχαν完全 αφαιρεθεί στην αρχή του project. Κάποιες από αυτές τις εμπορικές αναπτύξεις μπορεί να μην συμβούν για χρόνια ακόμη.
Χωρίς λευκό κουτί
Σχετικά με τη δεύτερη κοινή κριτική των συστημάτων επιθέσεων εικόνων ανταγωνιστών, οι συγγραφείς της νέας εργασίας έχουν βρει ότι η ικανότητά τους να απομακρύνουν συστήματα αναγνώρισης με σχεδιασμένες εικόνες λουλουδιών είναι πολύ μεταφερόμενη σε πολλά αρχιτεκτονικά.
Καθώς παρατηρούν ότι η μέθοδος “Universal NaTuralistic adversarial paTches” (TnT) είναι η πρώτη που χρησιμοποιεί αναγνωρίσιμες εικόνες (αντί για τυχαίο θόρυβο) για να απομακρύνει συστήματα αναγνώρισης εικόνων, οι συγγραφείς επίσης δηλώνουν:
‘[TnTs] είναι αποτελεσματικά ενάντια σε πολλά state-of-the-art ταξινομητές που κυριαρχούν στο Large-Scale Visual Recognition task του συνόλου δεδομένων ImageNet σε WideResNet50 και VGG-face μοντέλα στο face recognition task του συνόλου δεδομένων PubFig και σε targeted και untargeted επιθέσεις.
‘TnTs μπορούν να έχουν: i) τη φυσικότητα που επιτυγχάνεται [με] triggers που χρησιμοποιούνται σε Trojan attack μεθόδους; και ii) τη γενικευσιμότητα και τη μεταφερσιμότητα adversarial examples σε άλλα δίκτυα.
‘Αυτό προκαλεί προβλήματα ασφαλείας και ασφάλειας σχετικά με ήδη αναπτυγμένα DNNs, καθώς και μελλοντικές αναπτύξεις DNN όπου οι επιτιθέμενοι μπορούν να χρησιμοποιήσουν αόρατες φυσικές εικόνες για να απομακρύνουν νευρωνικά δίκτυα χωρίς να διαταράξουν το μοντέλο και να κινδυνεύσουν να ανακαλυφθούν.’
Οι συγγραφείς προτείνουν ότι οι παραδοσιακές αντιμετρόπες, όπως η μείωση της Clean Acc. ενός δικτύου, θα μπορούσαν θεωρητικά να παρέχουν κάποια άμυνα ενάντια στις TnT patches, αλλά ότι ‘TnTs vẫn μπορούν να παρακάμψουν αυτή τη SOTA προβλήματος άμυνας με τα περισσότερα από τα συστήματα άμυνας να επιτύχουν 0% Robustness’.
Πιθανές άλλες λύσεις περιλαμβάνουν federated learning, όπου η προέλευση των συνεισφερόντων εικόνων προστατεύεται, και νέες προσεγγίσεις που θα μπορούσαν να “κρυπτογραφήσουν” δεδομένα κατά την εκπαίδευση, όπως μια πρόταση πρόσφατα από το Πανεπιστήμιο Αεροπορίας και Αστροναυτικής της Ναντσίνγκ.
Ακόμη και σε αυτές τις περιπτώσεις, θα ήταν σημαντικό να εκπαιδεύσετε σε πραγματικά νέα δεδομένα εικόνων – μέχρι τώρα, οι εικόνες και οι συνδεδεμένες αναnotations στα πιο δημοφιλή σύνολα δεδομένων CV είναι τόσο ενσωματωμένα στις κυκλικές αναπτύξεις ανά τον κόσμο, ώστε να μοιάζουν περισσότερο με λογισμικό παρά με δεδομένα; λογισμικό που συχνά δεν έχει ενημερωθεί σημαντικά τα τελευταία χρόνια.
Συμπέρασμα
Οι επιθέσεις εικόνων ανταγωνιστών γίνονται δυνατές όχι μόνο από τις ανοιχτές πηγές πρακτικές μηχανικής μάθησης, αλλά και από μια εταιρική κουλτούρα AI που κινείται από την επαναχρήση καλά καθιερωμένων συνόλων δεδομένων εικόνων υπολογιστή για διάφορους λόγους: είναι ήδη αποδεδειγμένα αποτελεσματικά; είναι πολύ φθηνότερα από το να “ξεκινήσετε από την αρχή”; και διατηρούνται και ενημερώνονται από πρωτοπόρους νους και οργανισμούς σε ακαδημία και βιομηχανία, σε επίπεδα χρηματοδότησης και προσωπικού που θα ήταν δύσκολο για μια seule εταιρεία να αναπαράγει.
Επιπλέον, σε πολλές περιπτώσεις όπου τα δεδομένα δεν είναι πρωτότυπα (αντίθετα με το CityScapes), οι εικόνες συλλέχθηκαν πριν από πρόσφατες διαμάχες γύρω από προβλήματα ιδιωτικότητας και συλλογής δεδομένων, αφήνοντας αυτά τα παλιά σύνολα δεδομένων σε ένα είδος ημι-νομικού λίμνη που μπορεί να μοιάζει με ένα “ασφαλές λιμάνι”, από την πλευρά μιας εταιρείας.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems είναι συν-συγγραφέας από Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe από το Πανεπιστήμιο του Αδελαΐδας, μαζί με Shiqing Ma από το Τμήμα Πληροφορικής του Πανεπιστημίου Rutgers.
Ενημερώθηκε 1η Δεκεμβρίου 2021, 7:06 π.μ. GMT+2 – διορθώθηκε τυπογραφικό λάθος.












