Τεχνητή νοημοσύνη
Η Επανάσταση του Υπουργείου Παιδείας: Πώς η Προηγμένη Δρομολόγηση και η Εξειδίκευση Μεταμορφώνουν τα Μεταπτυχιακά Νομικής (LLM)
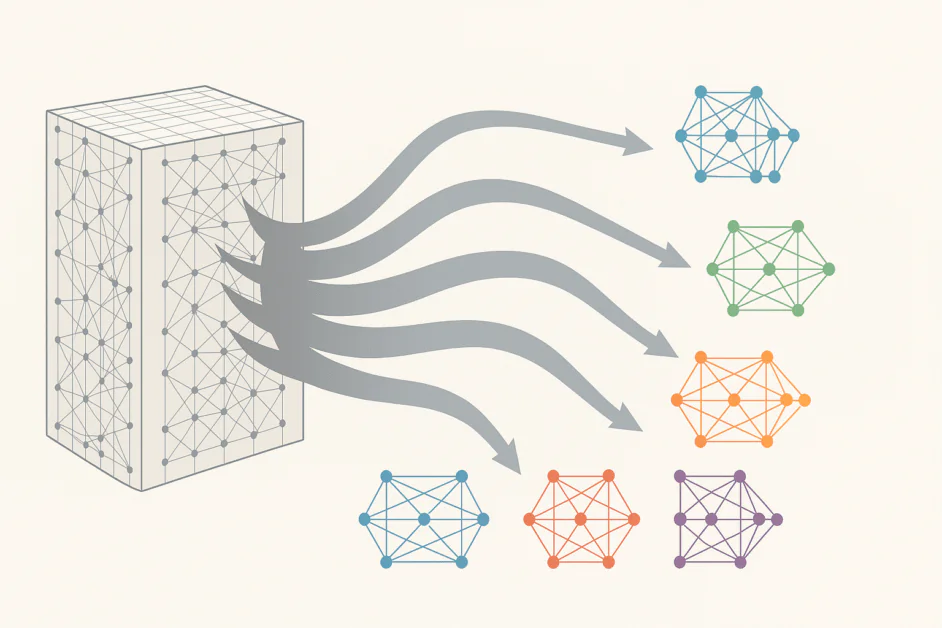
Μέσα σε λίγα μόλις χρόνια, τα μεγάλα γλωσσικά μοντέλα (LLM) έχουν επεκταθεί από εκατομμύρια σε εκατοντάδες δισεκατομμύρια παραμέτρους, επιδεικνύοντας την αξιοσημείωτη πρόοδο στην ικανότητά μας να σχεδιάζουμε και να κλιμακώνουμε τεράστια συστήματα Τεχνητής Νοημοσύνης. Αυτά τα τεράστια συστήματα έχουν προσφέρει εκπληκτικές δυνατότητες όπως η σύνταξη άπταιστου κειμένου, η δημιουργία κώδικα, η συλλογιστική σε σύνθετα προβλήματα και η συμμετοχή σε ανθρώπινο διάλογο. Αλλά αυτή η ταχεία κλιμάκωση συνοδεύεται από ένα σημαντικό κόστος. Η εκπαίδευση και η λειτουργία τέτοιων τεράστιων μοντέλων καταναλώνουν εξαιρετικά ποσά υπολογιστικής ισχύος, ενέργειας και κεφαλαίου. Η στρατηγική «όσο μεγαλύτερο τόσο καλύτερο» που κάποτε τροφοδότησε την πρόοδο έχει αρχίσει να δείχνει τα όριά της. Σε απάντηση σε αυτούς τους αυξανόμενους περιορισμούς, μια αρχιτεκτονική Τεχνητής Νοημοσύνης γνωστή ως... Μίγμα Εμπειρογνωμόνων (ΥΠ) προχωρά για να προσφέρει μια πιο έξυπνη και αποτελεσματική διαδρομή για την κλιμάκωση μεγάλων γλωσσικών μοντέλων. Αντί να βασίζεται σε ένα τεράστιο, πάντα ενεργό δίκτυο, το MoE διασπά το μοντέλο σε μια συλλογή εξειδικευμένων υποδικτύων ή «ειδικών», καθένα από τα οποία είναι εκπαιδευμένο να χειρίζεται συγκεκριμένα είδη δεδομένων ή εργασιών. Μέσω της έξυπνης δρομολόγησης, το μοντέλο ενεργοποιεί μόνο τους πιο σχετικούς ειδικούς για κάθε είσοδο, με στόχο τη μείωση του υπολογιστικού κόστους, διατηρώντας ή ακόμα και βελτιώνοντας την απόδοση. Αυτή η ικανότητα συνδυασμού της επεκτασιμότητας με την αποτελεσματικότητα καθιστά το MoE ένα από τα πιο καθοριστικά αναδυόμενα παραδείγματα στην Τεχνητή Νοημοσύνη. Αυτό το άρθρο διερευνά πώς η προηγμένη δρομολόγηση και η εξειδίκευση οδηγούν αυτόν τον μετασχηματισμό και τι σημαίνει αυτό για το μέλλον των έξυπνων συστημάτων.
Κατανόηση της βασικής αρχιτεκτονικής
Η ιδέα πίσω από το Μείγμα Εμπειρογνωμόνων (MoE) δεν είναι καινούργια. Ανάγεται στο μάθηση του συνόλου μεθόδους της δεκαετίας του 1990. Αυτό που έχει αλλάξει είναι η τεχνολογία που την κάνει να λειτουργεί. Μόνο τα τελευταία χρόνια οι εξελίξεις στο υλικό και στους αλγόριθμους δρομολόγησης κατέστησαν πρακτική την εφαρμογή αυτής της έννοιας στη σύγχρονη Βασισμένο σε μετασχηματιστή γλωσσικά μοντέλα.
Στην ουσία του, το MoE επαναπροσδιορίζει ένα μεγάλο νευρωνικό δίκτυο ως μια συλλογή μικρότερων, εξειδικευμένων υποδικτύων, καθένα από τα οποία έχει εκπαιδευτεί να χειρίζεται έναν συγκεκριμένο τύπο δεδομένων ή εργασίας. Αντί να ενεργοποιεί κάθε παράμετρο για κάθε είσοδο, το MoE εισάγει έναν μηχανισμό δρομολόγησης που αποφασίζει ποιοι ειδικοί είναι πιο σχετικοί για ένα δεδομένο διακριτικό ή ακολουθία. Το αποτέλεσμα είναι ένα μοντέλο που χρησιμοποιεί μόνο ένα κλάσμα των παραμέτρων του σε οποιαδήποτε δεδομένη στιγμή, μειώνοντας δραματικά την υπολογιστική ζήτηση διατηρώντας ή ακόμα και βελτιώνοντας την απόδοση.
Στην πράξη, αυτή η αρχιτεκτονική αλλαγή επιτρέπει στους ερευνητές να κλιμακώνουν μοντέλα σε τρισεκατομμύρια παραμέτρους χωρίς να απαιτείται αναλογική αύξηση των υπολογιστικών πόρων. Αντικαθιστά τα παραδοσιακά πυκνά επίπεδα feedforward με ένα πιο έξυπνο και δυναμικό σύστημα. Κάθε επίπεδο MoE περιέχει πολλαπλούς ειδικούς, συνήθως μικρότερα δίκτυα feedforward, και έναν δρομολογητή ή δίκτυο πύλης που αποφασίζει ποιοι ειδικοί θα πρέπει να επεξεργαστούν κάθε εισερχόμενο στοιχείο. Ο δρομολογητής λειτουργεί σαν διαχειριστής έργου, στέλνοντας σχετικές ερωτήσεις σε κάθε ειδικό. Με την πάροδο του χρόνου, το σύστημα μαθαίνει ποιοι ειδικοί έχουν την καλύτερη απόδοση για διαφορετικούς τύπους προβλημάτων, βελτιώνοντας τη στρατηγική δρομολόγησής του καθώς εκπαιδεύεται.
Αυτός ο σχεδιασμός προσφέρει έναν εντυπωσιακό συνδυασμό κλίμακας και αποδοτικότητας. Για παράδειγμα, DeepSeek V3, ένα από τα πιο προηγμένα μοντέλα MoE, χρησιμοποιεί τον εκπληκτικό αριθμό 685 δισεκατομμυρίων παραμέτρων, αλλά ενεργοποιεί μόνο ένα μικρό μέρος τους κατά την εξαγωγή συμπερασμάτων. Προσφέρει την απόδοση ενός τεράστιου μοντέλου με σημαντικά χαμηλότερες υπολογιστικές και ενεργειακές απαιτήσεις.
Η Εξέλιξη των Μηχανισμών Δρομολόγησης
Ο δρομολογητής είναι η καρδιά του Υπουργείου Παιδείας και Θρησκευμάτων, καθορίζοντας ποιοι ειδικοί χειρίζονται κάθε είσοδο. Τα πρώτα μοντέλα χρησιμοποιούσαν απλές στρατηγικές, επιλέγοντας τους δύο ή τρεις κορυφαίους ειδικούς με βάση τα βάρη που είχαν αποκτηθεί. Τα σύγχρονα συστήματα είναι πολύ πιο εξελιγμένα.
Οι σημερινοί μηχανισμοί δυναμικής δρομολόγησης προσαρμόζουν τον αριθμό των ενεργοποιημένων εμπειρογνωμόνων με βάση την πολυπλοκότητα των εισροών. Μια απλή ερώτηση μπορεί να χρειάζεται μόνο έναν ειδικό, ενώ οι δύσκολες εργασίες συλλογισμού μπορεί να ενεργοποιήσουν αρκετούς. DeepSeek-V2 Υλοποίησε δρομολόγηση περιορισμένης ανά συσκευή για τον έλεγχο του κόστους επικοινωνίας σε όλο το κατανεμημένο υλικό. DeepSeek-V3 πρωτοπόροι σε στρατηγικές χωρίς επικουρικές απώλειες που επιτρέπουν πλουσιότερη εξειδίκευση των ειδικών χωρίς υποβάθμιση της απόδοσης.
Προηγμένοι δρομολογητές τώρα λειτουργούν ως έξυπνοι διαχειριστές πόρων, προσαρμόζοντας τις στρατηγικές επιλογής με βάση τα χαρακτηριστικά εισόδου, το βάθος του δικτύου ή την ανατροφοδότηση απόδοσης σε πραγματικό χρόνο. Μερικοί ερευνητές είναι εξερεύνηση ενισχυτική μάθηση για τη βελτιστοποίηση της μακροπρόθεσμης απόδοσης των εργασιών. Τεχνικές όπως μαλακή πύλη επιτρέπουν την ομαλότερη επιλογή εμπειρογνωμόνων, ενώ η πιθανοτική κατανομή χρησιμοποιεί στατιστικές μεθόδους για τη βελτιστοποίηση των αναθέσεων.
Η εξειδίκευση οδηγεί στην απόδοση
Η βασική υπόσχεση του MoE είναι ότι η βαθιά εξειδίκευση υπερτερεί της ευρείας γενίκευσης. Κάθε ειδικός επικεντρώνεται στην τελειοποίηση συγκεκριμένων τομέων αντί να είναι μέτριος σε όλα. Κατά τη διάρκεια της εκπαίδευσης, οι μηχανισμοί δρομολόγησης κατευθύνουν σταθερά ορισμένους τύπους εισροών προς συγκεκριμένους ειδικούς, δημιουργώντας έναν ισχυρό βρόχο ανατροφοδότησης. Μερικοί εμπειρογνώμονες διαπρέπουν στον προγραμματισμό, άλλοι στην ιατρική ορολογία και άλλοι στη δημιουργική γραφή.
Ωστόσο, η επίτευξη αυτού του στόχου παρουσιάζει προκλήσεις. Οι παραδοσιακές προσεγγίσεις εξισορρόπησης φορτίου μπορούν, κατά ειρωνικό τρόπο, εμποδίζω εξειδίκευση επιβάλλοντας ομοιόμορφη χρήση από ειδικούς. Ωστόσο, ο τομέας εξελίσσεται ραγδαία. Έρευνες αποκαλύπτουν ότι τα λεπτομερή μοντέλα MoE εμφανίζουν σαφή εξειδίκευση, με διαφορετικούς ειδικούς να κυριαρχούν στους αντίστοιχους τομείς τους. Έρευνες επιβεβαιώνουν ότι οι μηχανισμοί δρομολόγησης παίζουν ενεργό ρόλο στη διαμόρφωση αυτού του αρχιτεκτονικού καταμερισμού εργασίας.
Οι στρατηγικές που απασχολούν βασικούς εμπειρογνώμονες στον τομέα έχουν επιδείξει αξιοσημείωτες βελτιώσεις στην απόδοση. Για παράδειγμα, οι ερευνητές αναφερθεί αύξηση ακρίβειας 3.33% στο Σημείο αναφοράς AIME2024Όταν η εξειδίκευση λειτουργεί, τα αποτελέσματα είναι αξιοσημείωτα. DeepSeek V3 υπερέχει GPT-4o στα περισσότερα benchmarks φυσικής γλώσσας και οδηγεί σε όλες τις εργασίες κωδικοποίησης και μαθηματικής συλλογιστικής, ένα εντυπωσιακό ορόσημο για ένα μοντέλο ανοιχτού κώδικα.
Πρακτικός αντίκτυπος στις δυνατότητες του μοντέλου
Η επανάσταση του MoE έχει επιφέρει απτές βελτιώσεις στις δυνατότητες των βασικών μοντέλων. Τα μοντέλα πλέον χειρίζονται μεγαλύτερα σε διάρκεια περιβάλλοντα πιο αποτελεσματικά. DeepSeek V3 και GPT-4o μπορεί να επεξεργαστεί 128 διακριτικά (tokens) σε μία μόνο είσοδο, με την αρχιτεκτονική MoE να βελτιστοποιεί την απόδοση, ειδικά σε τεχνικούς τομείς. Αυτό είναι κρίσιμο για εφαρμογές όπως η ανάλυση ολόκληρων βάσεων κώδικα ή η επεξεργασία μακροσκελών νομικών εγγράφων.
Τα κέρδη από την άποψη της αποδοτικότητας κόστους είναι ακόμη πιο δραματικά. Ανάλυση υποδηλώνει ότι το DeepSeek-V3 είναι περίπου 29.8 φορές φθηνότερο ανά διακριτικό σε σύγκριση με το GPT-4o. Αυτή η διαφορά τιμής καθιστά την προηγμένη Τεχνητή Νοημοσύνη προσβάσιμη σε ένα ευρύτερο φάσμα χρηστών και εφαρμογών. Επιταχύνει σημαντικά τον εκδημοκρατισμό της Τεχνητής Νοημοσύνης.
Επιπλέον, η αρχιτεκτονική επιτρέπει πιο βιώσιμη ανάπτυξη. Η εκπαίδευση ενός μοντέλου MoE εξακολουθεί να απαιτεί σημαντικούς πόρους, αλλά η δραματική χαμηλότερη συμπερασματική ανάλυση Το κόστος ανοίγει τον δρόμο για ένα πιο αποτελεσματικό και οικονομικά βιώσιμο μοντέλο για τις εταιρείες Τεχνητής Νοημοσύνης και τους πελάτες τους.
Προκλήσεις και η πορεία προς τα εμπρός
Παρά τα σημαντικά πλεονεκτήματα, το Υπουργείο Παιδείας δεν στερείται προκλήσειςΗ εκπαίδευση μπορεί να είναι ασταθής, με τους ειδικούς μερικές φορές να μην εξειδικεύονται όπως προβλέπεται. Τα πρώτα μοντέλα δυσκολεύονταν με το «σύμπτυξη δρομολόγησης», όπου κυριαρχούσε ένας ειδικός. Η διασφάλιση ότι όλοι οι ειδικοί λαμβάνουν επαρκή δεδομένα εκπαίδευσης ενώ μόνο ένα υποσύνολο είναι ενεργό απαιτεί προσεκτική εξισορρόπηση.
Το πιο σημαντικό συμφόρησης είναι η επιβάρυνση επικοινωνίας. Σε κατανεμημένες ρυθμίσεις GPU, το κόστος επικοινωνίας μπορεί να καταναλώσει έως και 77% του χρόνου επεξεργασίας. Πολλοί ειδικοί είναι «υπερβολικά συνεργάσιμοι», ενεργοποιούνται συχνά από κοινού και επιβάλλουν επαναλαμβανόμενες μεταφορές δεδομένων μεταξύ επιταχυντών υλικού. Αυτό οδηγεί σε θεμελιώδεις επανεκτιμήσεις του σχεδιασμού υλικού τεχνητής νοημοσύνης.
Οι απαιτήσεις μνήμης παρουσιάζουν μια άλλη σημαντική πρόκλησηΕνώ το MoE μειώνει το υπολογιστικό κόστος κατά την εξαγωγή συμπερασμάτων, όλοι οι εμπειρογνώμονες πρέπει να φορτώνονται στη μνήμη, επιβαρύνοντας τις συσκευές edge ή τα περιβάλλοντα με περιορισμένους πόρους. Η ερμηνευσιμότητα παραμένει μια άλλη βασική πρόκληση, καθώς ο προσδιορισμός του ποιος εμπειρογνώμονας συνέβαλε σε μια δεδομένη έξοδο προσθέτει ένα ακόμη επίπεδο πολυπλοκότητας στην αρχιτεκτονική. Οι ερευνητές διερευνούν τώρα μεθόδους για την ανίχνευση των ενεργοποιήσεων των εμπειρογνωμόνων και την οπτικοποίηση των διαδρομών λήψης αποφάσεων, με στόχο να καταστήσουν τα συστήματα MoE πιο διαφανή και ευκολότερα στον έλεγχο.
Η κατώτατη γραμμή
Το παράδειγμα του Μείγματος Εμπειρογνωμόνων δεν είναι απλώς μια νέα αρχιτεκτονική. Αντίθετα, είναι μια νέα φιλοσοφία για την κατασκευή μοντέλων Τεχνητής Νοημοσύνης. Συνδυάζοντας την έξυπνη δρομολόγηση με την εξειδίκευση σε επίπεδο τομέα, το MoE επιτυγχάνει αυτό που κάποτε φαινόταν αντιφατικό: μεγαλύτερη κλίμακα με λιγότερους υπολογισμούς. Ενώ οι προκλήσεις στη σταθερότητα, την επικοινωνία και την ερμηνευσιμότητα παραμένουν, η ισορροπία μεταξύ αποτελεσματικότητας, προσαρμοστικότητας και ακρίβειας δείχνει προς το μέλλον των συστημάτων Τεχνητής Νοημοσύνης που δεν είναι μόνο μεγαλύτερα αλλά και πιο έξυπνα.












