Τεχνητή νοημοσύνη
SofGAN: Ένας Γεγονός Προσώπου GAN που Προσφέρει Μεγαλύτερο Έλεγχο
Ερευνητές στη Σαγκάη και τις Ηνωμένες Πολιτείες έχουν αναπτύξει ένα σύστημα γεννήτριας πορτρέτου με βάση το GAN που επιτρέπει στους χρήστες να δημιουργούν νέα πρόσωπα με ένα επίπεδο ελέγχου που δεν ήταν διαθέσιμο μέχρι τώρα για ατομικά στοιχεία όπως τα μαλλιά, τα μάτια, τα γυαλιά, οι υφές και το χρώμα.
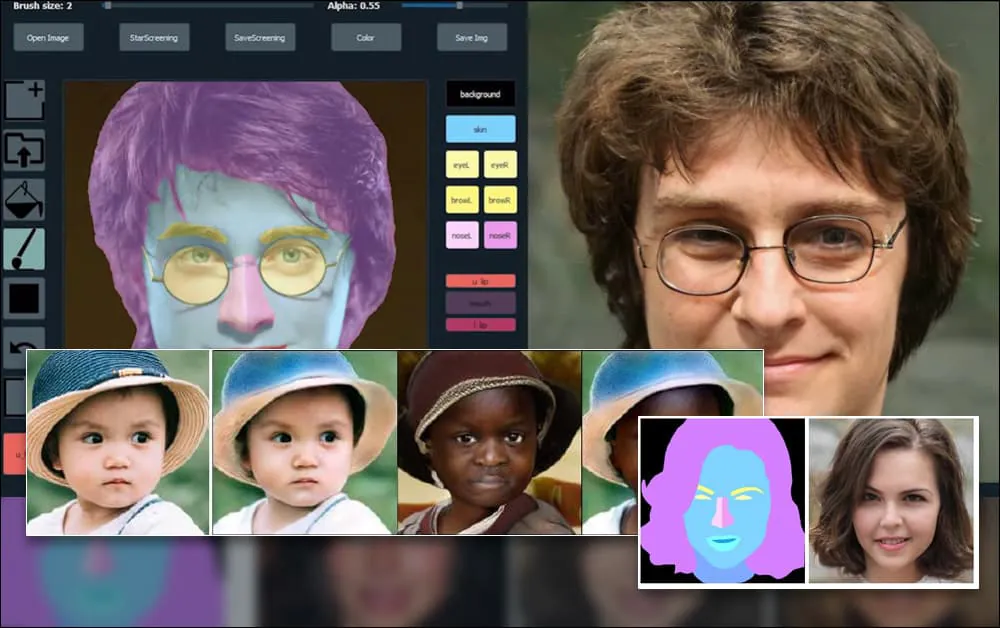
Για να δείξουν την ευελιξία του συστήματος, οι δημιουργοί έχουν παρέχει μια διεπαφή τύπου Photoshop όπου ο χρήστης μπορεί να σχεδιάσει trực tiếp στοιχεία семантиικής διαίρεσης που θα ερμηνευτούν σε ρεαλιστικές εικόνες και μπορεί ακόμη και να ληφθεί με την σχεδίαση απευθείας πάνω σε υπάρχουσες φωτογραφίες.
Στο παρακάτω παράδειγμα, μια εικόνα του ηθοποιού Daniel Radcliffe χρησιμοποιείται ως πρότυπο (και ο στόχος δεν είναι να παράγει μια ομοιότητα με αυτόν, αλλά μάλλον μια γενικά φωτορεαλιστική εικόνα). Όταν ο χρήστης συμπληρώνει διάφορα στοιχεία, συμπεριλαμβανομένων διακριτών πτυχών όπως τα γυαλιά, αυτά αναγνωρίζονται και ερμηνεύονται στην έξοδο της εικόνας:
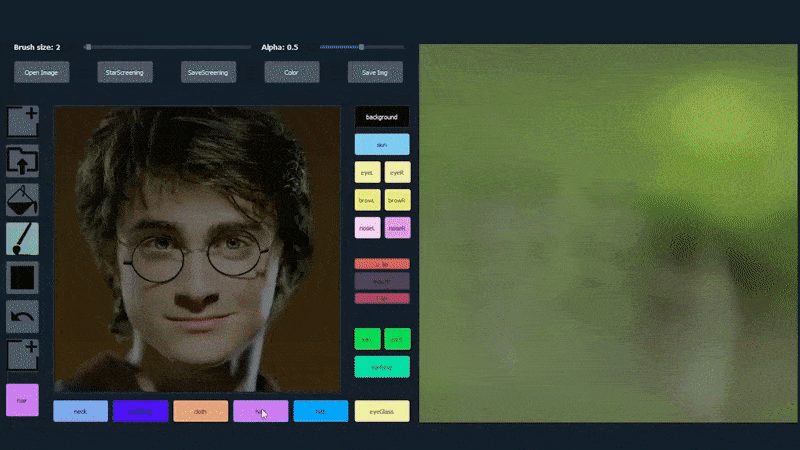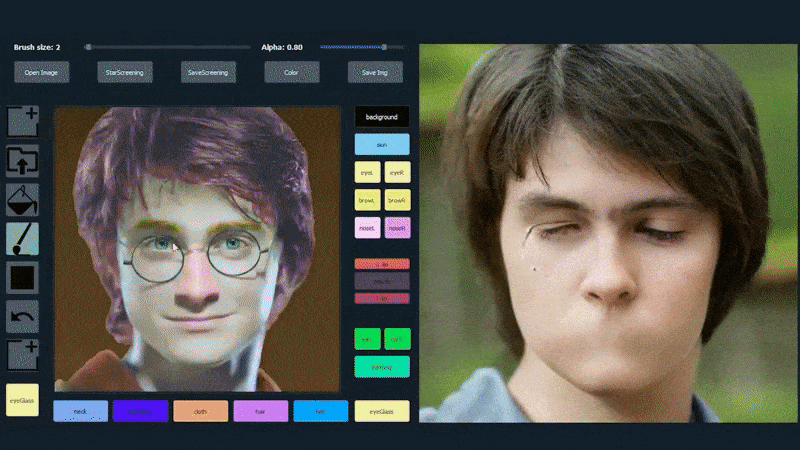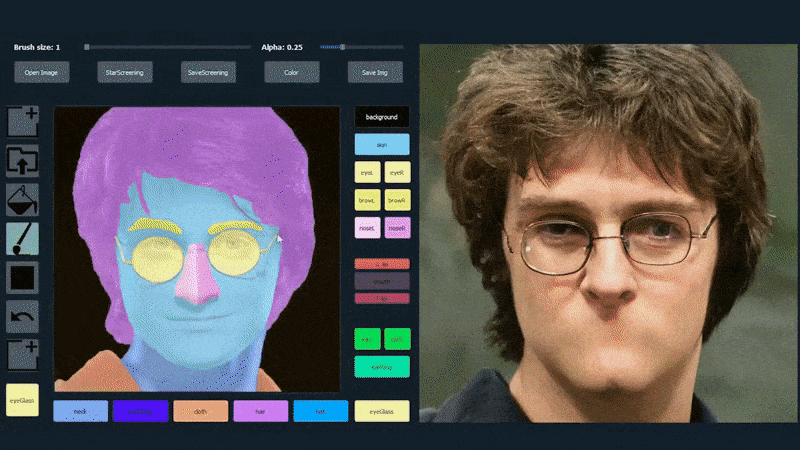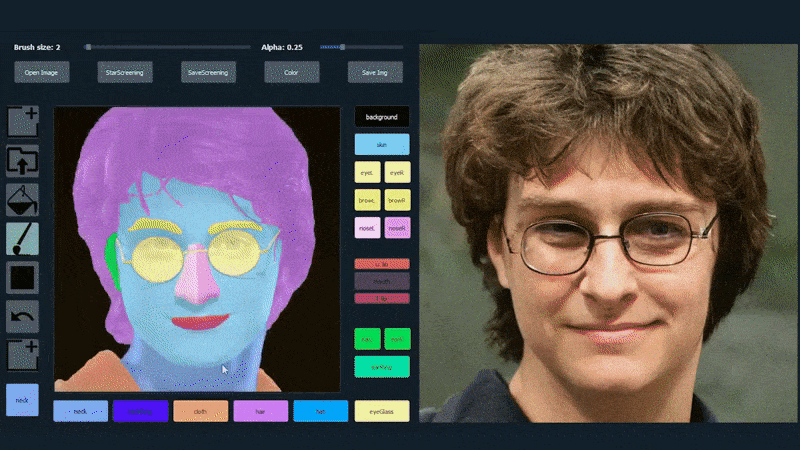
Χρήση μιας εικόνας ως υλικού για SofGAN-γεννημένο πορτρέτο. Source: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Το έγγραφο έχει τον τίτλο SofGAN: Ένας Γεννήτωρ Εικόνας Πορτρέτου με Δυναμική Στυλ και ηγείται από τους Anpei Chen και Ruiyang Liu, μαζί με δύο άλλους ερευνητές από το ShanghaiTech University και έναν από το Πανεπιστήμιο της Καλιφόρνιας στο Σαν Ντιέγκο.
Αποσύνδεση Χαρακτηριστικών
Η κύρια συνεισφορά της εργασίας δεν είναι τόσο η παροχή μιας φιλικής προς τον χρήστη διεπαφής, αλλά η ‘αποσύνδεση’ των χαρακτηριστικών των μαθημένων χαρακτηριστικών του προσώπου, όπως η στάση και η υφή, που επιτρέπει στο SofGAN να παράγει επίσης πρόσωπα που είναι σε間접ικές γωνίες προς την οπτική γωνία της κάμερας.

Ασυνήθιστο μεταξύ των γεννητών προσώπου με βάση τα Γεννητικά Ανταγωνιστικά Δίκτυα, το SofGAN μπορεί να αλλάξει τη γωνία θέασης κατά βούληση, εντός των ορίων του πίνακα των γωνιών που παρέχονται στα δεδομένα εκπαίδευσης. Source: https://arxiv.org/pdf/2007.03780.pdf
Εφόσον οι υφές είναι τώρα αποσυνδεμένες από τη γεωμετρία, το σχήμα του προσώπου και η υφή μπορούν επίσης να χειριστούν ως ξεχωριστές οντότητες. Σε πραγματικότητα, αυτό επιτρέπει την αλλαγή φυλής ενός πηγαίου προσώπου, μια σκανδαλώδης πρακτική που τώρα έχει μια потенτικά χρήσιμη εφαρμογή, για τη δημιουργία ισορροπημένων συνόλων δεδομένων μηχανικής μάθησης.

Το SofGAN υποστηρίζει επίσης την τεχνητή γήρανση και τη ρύθμιση στυλ που είναι συνεπής με τα χαρακτηριστικά σε ένα λεπτομερές επίπεδο που δεν έχει παρατηρηθεί σε παρόμοιους συστήματα διαίρεσης > εικόνας όπως το GauGAN της NVIDIA και το σύστημα της Intel.

Το SofGAN μπορεί να εφαρμόσει τη γήρανση ως μια επαναληπτική στυλ.
Μια άλλη καινοτομία για τη μεθοδολογία του SofGAN είναι ότι η εκπαίδευση δεν απαιτεί ζευγαρωμένα δεδομένα διαίρεσης/πραγματικών εικόνων, αλλά μπορεί να εκπαιδευτεί απευθείας σε μη ζευγαρωμένες πραγματικές εικόνες.
Οι ερευνητές αναφέρουν ότι η ‘αποσύνδεση’ αρχιτεκτονική του SofGAN ενέπνευσε από παραδοσιακά συστήματα απόδοσης εικόνας, τα οποία αποσυνδέουν τα ατομικά στοιχεία μιας εικόνας. Σε ροές εργασιών οπτικών εφέ, τα στοιχεία για ένα σύνθετο αποσυνδέονται σε τα πιο μικρά συστατικά, με ειδικούς αφιερωμένους σε κάθε συστατικό.
Σημαντική Κατοχή Σημασιολογικού Πεδίου (SOF)
Για να επιτύχουν αυτό σε ένα πλαίσιο σύνθεσης εικόνας με βάση τη μηχανική μάθηση, οι ερευνητές ανέπτυξαν ένα σημαντικό πεδίο κατοχής (SOF), μια επέκταση του παραδοσιακού πεδίου κατοχής που αποσυνδέει τα στοιχεία των πορτρέτων. Το SOF εκπαιδεύτηκε σε διαβιβασμένα χάρτες διαίρεσης με πολλαπλά θέα, αλλά χωρίς καμία επίβλεψη ground truth.

Πολλαπλές επαναλήψεις από einen χάρτη διαίρεσης (κάτω αριστερά).
Επιπλέον, χάρτες διαίρεσης 2D λαμβάνονται με την ακολουθία της εξόδου του SOF, πριν υφανθούν από έναν γεννήτωρα GAN. Οι ‘συνθετικοί’ χάρτες διαίρεσης κωδικοποιούνται επίσης σε ένα χαμηλό διαστατικό χώρο μέσω ενός τριστιβαθίου κωδικοποιητή για να διασφαλιστεί η συνέχεια της εξόδου όταν η οπτική γωνία αλλάζει.
Το σχήμα εκπαίδευσης χωρικά αναμιγνύει δύο τυχαίες στυλ για κάθε σημασιολογική περιοχή:

Η αρχιτεκτονική για SofGAN.
Οι ερευνητές ισχυρίζονται ότι το SofGAN επιτυγχάνει μια χαμηλότερη Απόσταση Frechet Inception (FID) από τις τρέχουσες εναλλακτικές προσεγγίσεις SOTA, καθώς και einen υψηλότερο μετρητή Learned Perceptual Image Patch Similarity (LPIPS).
Προηγούμενες προσεγγίσεις StyleGAN έχουν συχνά εμποδιστεί από την αποσύνδεση χαρακτηριστικών, όπου τα στοιχεία που αποτελούν μια εικόνα είναι αδιαχώριστα δεμένα μεταξύ τους, προκαλώντας την εμφάνιση ανεπιθύμητων στοιχείων μαζί με ένα επιθυμητό στοιχείο (π.χ. σκουλαρίκια μπορεί να εμφανιστούν όταν ένα σχήμα αυτιού αποδίδεται που ενημερώθηκε κατά την εκπαίδευση από μια εικόνα που είχε σκουλαρίκια).

Η μεθόδος ray marching χρησιμοποιείται για τον υπολογισμό του όγκου των χαρτών διαίρεσης, επιτρέποντας πολλαπλές οπτικές γωνίες.
Συνόλα Δεδομένων και Εκπαίδευση
Τρία συνόλα δεδομένων χρησιμοποιήθηκαν στην ανάπτυξη διαφόρων υλοποιήσεων του SofGAN: CelebAMask-HQ, ένα αποθετήριο 30.000 υψηλής ανάλυσης εικόνων από το σύνολο δεδομένων CelebA-HQ, το FFHQ της NVIDIA, το οποίο περιέχει 70.000 εικόνες, όπου οι ερευνητές έταξαν τις εικόνες με έναν προ-εκπαιδευμένο αναλυτή προσώπου, και ένα αυτοπαραγόμενο σύνολο 122 πορτρέτων με χειροκίνητα επισημασμένες σημασιολογικές περιοχές.
Το SOF αποτελείται από τρία εκπαιδεύσιμα υπο-μοντά: το hyper-δίκτυο, έναν ray marcher (βλ. εικόνα παραπάνω) και έναν ταξινομητή. Ο γεννήτωρας StyleGAN του SofGAN ρυθμίζεται παρόμοια με το StyleGAN2 σε ορισμένα аспектούς. Η επέκταση δεδομένων εφαρμόζεται μέσω τυχαίου масштабα και περικοπής, και η εκπαίδευση χαρακτηριστικών περιλαμβάνει κανονικοποίηση μονοπατιού κάθε τέσσερις βήματα. Η ολόκληρη διαδικασία εκπαίδευσης διήρκεσε 22 ημέρες για να φτάσει τις 800.000 επαναλήψεις σε τέσσερις RTX 2080 Ti GPU μέσω CUDA 10.1.
Το έγγραφο δεν αναφέρει τη ρύθμιση των καρτών 2080, οι οποίες μπορούν να φιλοξενήσουν μεταξύ 11gb-22gb VRAM η κάθε μια, που σημαίνει ότι το συνολικό VRAM που χρησιμοποιήθηκε για το μεγαλύτερο μέρος του μήνα για την εκπαίδευση του SofGAN είναι κάπου μεταξύ 44Gb και 88Gb.
Οι ερευνητές παρατηρούν ότι αποδεκτά γενικευμένα, υψηλού επιπέδου αποτελέσματα άρχισαν να εμφανίζονται khá νωρίς στην εκπαίδευση, στις 1500 επαναλήψεις, τρεις ημέρες στην εκπαίδευση. Το υπόλοιπο της εκπαίδευσης καταλαμβάνθηκε από την προβλέψιμη, αργή πορεία προς την απόκτηση λεπτομερών στοιχείων όπως τα μαλλιά και τα στοιχεία των ματιών.
Το SofGAN γενικά επιτυγχάνει πιο ρεαλιστικά αποτελέσματα από έναν χάρτη διαίρεσης από αντίπαλες μεθόδους όπως το SPADE της NVIDIA και το Pix2PixHD, και το SEAN.

Κάτω από το βίντεο που κυκλοφόρησε από τους ερευνητές. Περαιτέρω αυτο-φιλοξενούμενα βίντεο είναι διαθέσιμα στη σελίδα του έργου.
https://www.youtube.com/watch?v=xig8ZA3DVZ8













{kind=link}
{kind=link}