
Τεχνητή νοημοσύνη
Άμεση βελτιστοποίηση προτιμήσεων: Πλήρης οδηγός

Η ευθυγράμμιση μεγάλων γλωσσικών μοντέλων (LLM) με τις ανθρώπινες αξίες και προτιμήσεις αποτελεί πρόκληση. Παραδοσιακές μέθοδοι, όπως π.χ Ενισχυτική μάθηση από την ανθρώπινη ανατροφοδότηση (RLHF), έχουν ανοίξει το δρόμο με την ενσωμάτωση ανθρώπινων εισροών για τη βελτίωση των αποτελεσμάτων των μοντέλων. Ωστόσο, το RLHF μπορεί να είναι πολύπλοκο και με ένταση πόρων, απαιτώντας σημαντική υπολογιστική ισχύ και επεξεργασία δεδομένων. Βελτιστοποίηση άμεσης προτίμησης (DPO) αναδεικνύεται ως μια νέα και πιο βελτιωμένη προσέγγιση, προσφέροντας μια αποτελεσματική εναλλακτική λύση σε αυτές τις παραδοσιακές μεθόδους. Με την απλοποίηση της διαδικασίας βελτιστοποίησης, το DPO όχι μόνο μειώνει τον υπολογιστικό φόρτο αλλά επίσης ενισχύει την ικανότητα του μοντέλου να προσαρμόζεται γρήγορα στις ανθρώπινες προτιμήσεις
Σε αυτόν τον οδηγό θα βουτήξουμε βαθιά στο DPO, διερευνώντας τα θεμέλια, την εφαρμογή και τις πρακτικές εφαρμογές του.
Η ανάγκη για ευθυγράμμιση προτιμήσεων
Για να κατανοήσουμε το DPO, είναι σημαντικό να κατανοήσουμε γιατί είναι τόσο σημαντική η ευθυγράμμιση των LLM με τις ανθρώπινες προτιμήσεις. Παρά τις εντυπωσιακές δυνατότητές τους, τα LLM που εκπαιδεύονται σε τεράστια σύνολα δεδομένων μπορούν μερικές φορές να παράγουν αποτελέσματα που είναι ασυνεπή, μεροληπτικά ή κακώς ευθυγραμμισμένα με τις ανθρώπινες αξίες. Αυτή η κακή ευθυγράμμιση μπορεί να εκδηλωθεί με διάφορους τρόπους:
- Δημιουργία μη ασφαλούς ή επιβλαβούς περιεχομένου
- Παροχή ανακριβών ή παραπλανητικών πληροφοριών
- Εμφάνιση προκαταλήψεων που υπάρχουν στα δεδομένα εκπαίδευσης
Για να αντιμετωπίσουν αυτά τα ζητήματα, οι ερευνητές έχουν αναπτύξει τεχνικές για να τελειοποιήσουν τα LLM χρησιμοποιώντας την ανθρώπινη ανατροφοδότηση. Η πιο σημαντική από αυτές τις προσεγγίσεις ήταν η RLHF.
Κατανόηση του RLHF: Ο πρόδρομος του DPO
Η Ενισχυτική Μάθηση από την Ανθρώπινη Ανατροφοδότηση (RLHF) ήταν η πιο δημοφιλής μέθοδος για την ευθυγράμμιση των LLM με τις ανθρώπινες προτιμήσεις. Ας αναλύσουμε τη διαδικασία RLHF για να κατανοήσουμε την πολυπλοκότητά της:
a) Εποπτευόμενη λεπτομέρεια (SFT): Η διαδικασία ξεκινάει με την τελειοποίηση ενός προεκπαιδευμένου LLM σε ένα σύνολο δεδομένων αποκρίσεων υψηλής ποιότητας. Αυτό το βήμα βοηθά το μοντέλο να δημιουργήσει πιο σχετικά και συνεκτικά αποτελέσματα για την εργασία-στόχο.
b) Μοντελοποίηση επιβράβευσης: Ένα ξεχωριστό μοντέλο ανταμοιβής εκπαιδεύεται για την πρόβλεψη των ανθρώπινων προτιμήσεων. Αυτό περιλαμβάνει:
- Δημιουργία ζευγών απόκρισης για δεδομένες προτροπές
- Έχοντας τους ανθρώπους να αξιολογήσουν ποια απόκριση προτιμούν
- Εκπαίδευση ενός μοντέλου για την πρόβλεψη αυτών των προτιμήσεων
c) Μάθηση Ενίσχυσης: Το τελειοποιημένο LLM στη συνέχεια βελτιστοποιείται περαιτέρω χρησιμοποιώντας ενισχυτική μάθηση. Το μοντέλο ανταμοιβής παρέχει ανατροφοδότηση, καθοδηγώντας το LLM να δημιουργήσει απαντήσεις που ευθυγραμμίζονται με τις ανθρώπινες προτιμήσεις.
Ακολουθεί ένας απλοποιημένος ψευδοκώδικας Python για την απεικόνιση της διαδικασίας RLHF:
Ενώ είναι αποτελεσματικό, το RLHF έχει πολλά μειονεκτήματα:
- Απαιτεί εκπαίδευση και συντήρηση πολλαπλών μοντέλων (SFT, μοντέλο ανταμοιβής και μοντέλο βελτιστοποιημένο για RL)
- Η διαδικασία RL μπορεί να είναι ασταθής και ευαίσθητη σε υπερπαραμέτρους
- Είναι υπολογιστικά ακριβό, απαιτώντας πολλά περάσματα προς τα εμπρός και προς τα πίσω από τα μοντέλα
Αυτοί οι περιορισμοί έχουν παρακινήσει την αναζήτηση απλούστερων, πιο αποτελεσματικών εναλλακτικών λύσεων, οδηγώντας στην ανάπτυξη του DPO.
Βελτιστοποίηση Άμεσης Προτίμησης: Βασικές Έννοιες

Βελτιστοποίηση άμεσης προτίμησης https://arxiv.org/abs/2305.18290
Αυτή η εικόνα έρχεται σε αντίθεση με δύο διακριτές προσεγγίσεις για την ευθυγράμμιση των εξόδων LLM με τις ανθρώπινες προτιμήσεις: Ενισχυτική μάθηση από την ανθρώπινη ανατροφοδότηση (RLHF) και βελτιστοποίηση άμεσης προτίμησης (DPO). Το RLHF βασίζεται σε ένα μοντέλο ανταμοιβής για να καθοδηγήσει την πολιτική του γλωσσικού μοντέλου μέσω επαναληπτικών βρόχων ανάδρασης, ενώ το DPO βελτιστοποιεί άμεσα τις εξόδους του μοντέλου ώστε να ταιριάζουν με τις προτιμώμενες από τον άνθρωπο αποκρίσεις χρησιμοποιώντας δεδομένα προτιμήσεων. Αυτή η σύγκριση υπογραμμίζει τα δυνατά σημεία και τις πιθανές εφαρμογές κάθε μεθόδου, παρέχοντας πληροφορίες για το πώς οι μελλοντικοί LLMs θα μπορούσαν να εκπαιδευτούν ώστε να ευθυγραμμίζονται καλύτερα με τις ανθρώπινες προσδοκίες.
Βασικές ιδέες πίσω από το DPO:
a) Implicit Reward Modeling: Το DPO εξαλείφει την ανάγκη για ένα ξεχωριστό μοντέλο ανταμοιβής αντιμετωπίζοντας το ίδιο το γλωσσικό μοντέλο ως μια σιωπηρή συνάρτηση ανταμοιβής.
b) Διατύπωση με βάση την πολιτική: Αντί να βελτιστοποιήσει μια συνάρτηση ανταμοιβής, το DPO βελτιστοποιεί απευθείας την πολιτική (μοντέλο γλώσσας) για να μεγιστοποιήσει την πιθανότητα προτιμώμενων απαντήσεων.
c) Λύση κλειστής μορφής: Το DPO αξιοποιεί μια μαθηματική εικόνα που επιτρέπει μια λύση κλειστής μορφής για τη βέλτιστη πολιτική, αποφεύγοντας την ανάγκη για επαναληπτικές ενημερώσεις RL.
Implementing DPO: A Practical Code Walkthrough
Η παρακάτω εικόνα δείχνει ένα απόσπασμα κώδικα που υλοποιεί τη συνάρτηση απώλειας DPO χρησιμοποιώντας το PyTorch. Αυτή η λειτουργία παίζει κρίσιμο ρόλο στη βελτίωση του τρόπου με τον οποίο τα γλωσσικά μοντέλα δίνουν προτεραιότητα στα αποτελέσματα με βάση τις ανθρώπινες προτιμήσεις. Ακολουθεί μια ανάλυση των βασικών στοιχείων:
- Υπογραφή συνάρτησης: Ο
dpo_lossΗ συνάρτηση λαμβάνει πολλές παραμέτρους, συμπεριλαμβανομένων των πιθανοτήτων καταγραφής πολιτικών (pi_logps), πιθανότητες καταγραφής μοντέλου αναφοράς (ref_logps), και δείκτες που αντιπροσωπεύουν προτιμώμενες και μη προτιμώμενες συμπληρώσεις (yw_idxs,yl_idxs). Επιπλέον, αbetaΗ παράμετρος ελέγχει την ισχύ της ποινής KL. - Εξαγωγή πιθανοτήτων καταγραφής: Ο κώδικας εξάγει τις πιθανότητες καταγραφής για προτιμώμενες και μη προτιμώμενες συμπληρώσεις τόσο από το μοντέλο πολιτικής όσο και από το μοντέλο αναφοράς.
- Υπολογισμός αναλογίας καταγραφής: Η διαφορά μεταξύ των πιθανοτήτων καταγραφής για προτιμώμενες και μη προτιμώμενες ολοκληρώσεις υπολογίζεται τόσο για το μοντέλο πολιτικής όσο και για το μοντέλο αναφοράς. Αυτή η αναλογία είναι κρίσιμη για τον προσδιορισμό της κατεύθυνσης και του μεγέθους της βελτιστοποίησης.
- Υπολογισμός απώλειας και ανταμοιβής: Η απώλεια υπολογίζεται χρησιμοποιώντας το
logsigmoidσυνάρτηση, ενώ οι ανταμοιβές καθορίζονται με την κλιμάκωση της διαφοράς μεταξύ των πιθανοτήτων καταγραφής πολιτικής και αναφοράς κατάbeta.

Λειτουργία απώλειας DPO χρησιμοποιώντας PyTorch
Ας βουτήξουμε στα μαθηματικά πίσω από το DPO για να καταλάβουμε πώς επιτυγχάνει αυτούς τους στόχους.
Τα Μαθηματικά του DPO
Το DPO είναι μια έξυπνη αναδιατύπωση του προβλήματος μάθησης προτιμήσεων. Ακολουθεί μια αναλυτική ανάλυση βήμα προς βήμα:
α) Σημείο εκκίνησης: KL-Constrained Reward Maximization
Ο αρχικός στόχος RLHF μπορεί να εκφραστεί ως εξής:
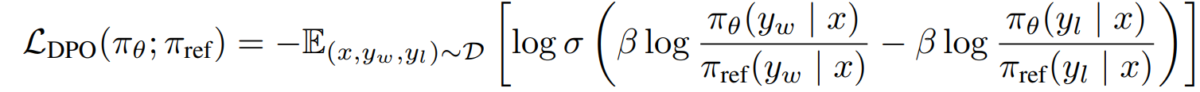
- Το πθ είναι η πολιτική (μοντέλο γλώσσας) που βελτιστοποιούμε
- Το r(x,y) είναι η συνάρτηση ανταμοιβής
- Το πref είναι μια πολιτική αναφοράς (συνήθως το αρχικό μοντέλο SFT)
- Το β ελέγχει την ισχύ του περιορισμού απόκλισης KL
b) Βέλτιστη φόρμα πολιτικής: Μπορεί να αποδειχθεί ότι η βέλτιστη πολιτική για αυτόν τον στόχο έχει τη μορφή:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Όπου το Z(x) είναι σταθερά κανονικοποίησης.
c) Διττός ανταμοιβής-πολιτικής: Η βασική γνώση του DPO είναι να εκφράσει τη συνάρτηση ανταμοιβής με βάση τη βέλτιστη πολιτική:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))δ) Μοντέλο προτίμησης Υποθέτοντας ότι οι προτιμήσεις ακολουθούν το μοντέλο Bradley-Terry, μπορούμε να εκφράσουμε την πιθανότητα να προτιμήσουμε το y1 έναντι του y2 ως:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Όπου σ είναι η λογιστική συνάρτηση.
e) Στόχος DPO Αντικαθιστώντας τη δυαδικότητα ανταμοιβής-πολιτικής με το μοντέλο προτίμησης, φτάνουμε στον στόχο DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Αυτός ο στόχος μπορεί να βελτιστοποιηθεί χρησιμοποιώντας τυπικές τεχνικές gradient descent, χωρίς την ανάγκη για αλγόριθμους RL.
Εφαρμογή DPO
Τώρα που καταλαβαίνουμε τη θεωρία πίσω από το DPO, ας δούμε πώς να την εφαρμόσουμε στην πράξη. θα χρησιμοποιήσουμε Python και PyTorch για αυτό το παράδειγμα:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Προκλήσεις και Μελλοντικές Κατευθύνσεις
Ενώ το DPO προσφέρει σημαντικά πλεονεκτήματα σε σχέση με τις παραδοσιακές προσεγγίσεις RLHF, εξακολουθούν να υπάρχουν προκλήσεις και τομείς για περαιτέρω έρευνα:
α) Επεκτασιμότητα σε μεγαλύτερα μοντέλα:
Καθώς τα γλωσσικά μοντέλα συνεχίζουν να αυξάνονται σε μέγεθος, η αποτελεσματική εφαρμογή DPO σε μοντέλα με εκατοντάδες δισεκατομμύρια παραμέτρους παραμένει μια ανοιχτή πρόκληση. Οι ερευνητές διερευνούν τεχνικές όπως:
- Αποτελεσματικές μέθοδοι μικρορύθμισης (π.χ. LoRA, συντονισμός προθέματος)
- Κατανεμημένες βελτιστοποιήσεις εκπαίδευσης
- Σημείο ελέγχου κλίσης και εκπαίδευση μεικτής ακρίβειας
Παράδειγμα χρήσης LoRA με DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
β) Προσαρμογή πολλαπλών εργασιών και λίγων βολών:
Η ανάπτυξη τεχνικών DPO που μπορούν να προσαρμοστούν αποτελεσματικά σε νέες εργασίες ή τομείς με περιορισμένα δεδομένα προτιμήσεων είναι ένας ενεργός τομέας έρευνας. Οι προσεγγίσεις που διερευνώνται περιλαμβάνουν:
- Πλαίσια μετα-μάθησης για γρήγορη προσαρμογή
- Βελτιστοποίηση βάσει άμεσης ενημέρωσης για DPO
- Μεταφορά μάθησης από μοντέλα γενικών προτιμήσεων σε συγκεκριμένους τομείς
γ) Χειρισμός διφορούμενων ή αντικρουόμενων προτιμήσεων:
Τα δεδομένα προτιμήσεων του πραγματικού κόσμου συχνά περιέχουν ασάφειες ή διενέξεις. Η βελτίωση της ευρωστίας του DPO σε τέτοια δεδομένα είναι ζωτικής σημασίας. Οι πιθανές λύσεις περιλαμβάνουν:
- Πιθανοτική μοντελοποίηση προτιμήσεων
- Ενεργητική μάθηση για την επίλυση αμφισημιών
- Συγκέντρωση προτιμήσεων πολλαπλών πρακτόρων
Παράδειγμα πιθανοτικής μοντελοποίησης προτιμήσεων:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
δ) Συνδυασμός DPO με άλλες τεχνικές ευθυγράμμισης:
Η ενσωμάτωση του DPO με άλλες προσεγγίσεις ευθυγράμμισης θα μπορούσε να οδηγήσει σε πιο ισχυρά και ικανά συστήματα:
- Συνταγματικές αρχές τεχνητής νοημοσύνης για ρητή ικανοποίηση περιορισμών
- Συζήτηση και αναδρομική μοντελοποίηση ανταμοιβής για σύνθετη πρόκληση προτιμήσεων
- Εκμάθηση αντίστροφης ενίσχυσης για συμπέρασμα υποκείμενων συναρτήσεων ανταμοιβής
Παράδειγμα συνδυασμού DPO με συνταγματική AI:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Πρακτικές θεωρήσεις και βέλτιστες πρακτικές
Κατά την εφαρμογή DPO για εφαρμογές πραγματικού κόσμου, λάβετε υπόψη τις ακόλουθες συμβουλές:
a) Ποιότητα δεδομένων: Η ποιότητα των δεδομένων προτίμησής σας είναι ζωτικής σημασίας. Βεβαιωθείτε ότι το σύνολο δεδομένων σας:
- Καλύπτει ένα ευρύ φάσμα εισροών και επιθυμητών συμπεριφορών
- Διαθέτει συνεπείς και αξιόπιστους σχολιασμούς προτιμήσεων
- Εξισορροπεί διαφορετικούς τύπους προτιμήσεων (π.χ. πραγματικότητα, ασφάλεια, στυλ)
b) Ρύθμιση υπερπαραμέτρων: Ενώ το DPO έχει λιγότερες υπερπαραμέτρους από το RLHF, ο συντονισμός εξακολουθεί να είναι σημαντικός:
- β (βήτα): Ελέγχει την αντιστάθμιση μεταξύ ικανοποίησης προτιμήσεων και απόκλισης από το μοντέλο αναφοράς. Ξεκινήστε με τις αξίες γύρω 0.1-0.5.
- Ποσοστό εκμάθησης: Χρησιμοποιήστε χαμηλότερο ρυθμό εκμάθησης από τον τυπικό συντονισμό, συνήθως στο εύρος των 1e-6 έως 1e-5.
- Μέγεθος παρτίδας: Μεγαλύτερα μεγέθη παρτίδας (32-128) συχνά λειτουργούν καλά για τη μάθηση κατά προτίμηση.
c) Επαναληπτική βελτίωση: Το DPO μπορεί να εφαρμοστεί επαναληπτικά:
- Εκπαιδεύστε ένα αρχικό μοντέλο χρησιμοποιώντας DPO
- Δημιουργήστε νέες απαντήσεις χρησιμοποιώντας το εκπαιδευμένο μοντέλο
- Συλλέξτε νέα δεδομένα προτιμήσεων για αυτές τις απαντήσεις
- Επανεκπαίδευση χρησιμοποιώντας το διευρυμένο σύνολο δεδομένων

Απόδοση βελτιστοποίησης άμεσης προτίμησης
Αυτή η εικόνα δείχνει την απόδοση των LLMs όπως το GPT-4 σε σύγκριση με τις ανθρώπινες κρίσεις σε διάφορες τεχνικές εκπαίδευσης, όπως η βελτιστοποίηση άμεσης προτίμησης (DPO), η εποπτευόμενη τελειοποίηση (SFT) και η εγγύς βελτιστοποίηση πολιτικής (PPO). Ο πίνακας αποκαλύπτει ότι τα αποτελέσματα του GPT-4 ευθυγραμμίζονται ολοένα και περισσότερο με τις ανθρώπινες προτιμήσεις, ειδικά στις εργασίες σύνοψης. Το επίπεδο συμφωνίας μεταξύ του GPT-4 και των ανθρώπινων αναθεωρητών καταδεικνύει την ικανότητα του μοντέλου να δημιουργεί περιεχόμενο που έχει απήχηση στους ανθρώπινους αξιολογητές, σχεδόν τόσο στενά όσο και το περιεχόμενο που δημιουργείται από ανθρώπους.
Μελέτες Περιπτώσεων και Εφαρμογές
Για να δείξουμε την αποτελεσματικότητα του DPO, ας δούμε μερικές εφαρμογές του πραγματικού κόσμου και μερικές από τις παραλλαγές του:
- Επαναληπτικό DPO: Αναπτύχθηκε από τον Snorkel (2023), αυτή η παραλλαγή συνδυάζει δειγματοληψία απόρριψης με DPO, επιτρέποντας μια πιο εκλεπτυσμένη διαδικασία επιλογής για τα δεδομένα εκπαίδευσης. Με την επανάληψη σε πολλούς γύρους δειγματοληψίας προτιμήσεων, το μοντέλο μπορεί να γενικεύει καλύτερα και να αποφεύγει την υπερβολική προσαρμογή σε θορυβώδεις ή μεροληπτικές προτιμήσεις.
- IPO (Επαναληπτική βελτιστοποίηση προτιμήσεων): Εισάγεται από τους Azar et al. (2023), η IPO προσθέτει έναν όρο τακτοποίησης για να αποτρέψει την υπερπροσαρμογή, το οποίο είναι ένα κοινό ζήτημα στη βελτιστοποίηση βάσει προτιμήσεων. Αυτή η επέκταση επιτρέπει στα μοντέλα να διατηρούν μια ισορροπία μεταξύ της τήρησης των προτιμήσεων και της διατήρησης των δυνατοτήτων γενίκευσης.
- KTO (Βελτιστοποίηση Μεταφοράς Γνώσης): Μια πιο πρόσφατη παραλλαγή από τους Ethayarajh et al. (2023), το KTO απαλλάσσει τις δυαδικές προτιμήσεις εντελώς. Αντίθετα, εστιάζει στη μεταφορά γνώσης από ένα μοντέλο αναφοράς στο μοντέλο πολιτικής, βελτιστοποιώντας για μια πιο ομαλή και πιο συνεπή ευθυγράμμιση με τις ανθρώπινες αξίες.
- Multi-Modal DPO for Cross-Domain Learning από Xu et al. (2024): Μια προσέγγιση όπου το DPO εφαρμόζεται σε διαφορετικούς τρόπους —κείμενο, εικόνα και ήχος— καταδεικνύοντας την ευελιξία του στην ευθυγράμμιση μοντέλων με τις ανθρώπινες προτιμήσεις σε διάφορους τύπους δεδομένων. Αυτή η έρευνα υπογραμμίζει τις δυνατότητες του DPO στη δημιουργία πιο ολοκληρωμένων συστημάτων τεχνητής νοημοσύνης ικανά να χειρίζονται πολύπλοκες εργασίες πολλαπλών μέσων.











