Τεχνητή νοημοσύνη
Ολοκληρωμένος Οδηγός για το Gemma 2: Το Νέο Ανοικτό Μεγάλο Μοντέλο Γλώσσας της Google

Gemma 2 κατασκευάζεται πάνω στο προηγούμενο μοντέλο, προσφέροντας βελτιωμένη απόδοση και αποδοτικότητα, μαζί με μια σειρά καινοτόμων χαρακτηριστικών που το καθιστούν ιδιαίτερα ελκυστικό τόσο για έρευνα όσο και για πρακτικές εφαρμογές. Αυτό που διακρίνει το Gemma 2 είναι η ικανότητά του να παρέχει απόδοση συγκρίσιμη με πολύ μεγαλύτερα ιδιόκτητα μοντέλα, αλλά σε ένα πακέτο που σχεδιάστηκε για ευρύτερη πρόσβαση και χρήση σε πιο μετρημένα σύνολα υλικού.
Καθώς εμβάθυνα στις τεχνικές προδιαγραφές και την αρχιτεκτονική του Gemma 2, βρήκα τον εαυτό μου ολοένα και πιο εντυπωσιασμένο από την ευρηματικότητα του σχεδιασμού του. Το μοντέλο ενσωματώνει幾να προηγμένα τεχνικά, συμπεριλαμβανομένων νέων μηχανισμών προσοχής και καινοτόμων προσεγγίσεων για τη σταθερότητα της εκπαίδευσης, που συμβάλλουν στις αξιοσημείωτες ικανότητές του.

Google Open Source LLM Gemma
Σε αυτόν τον ολοκληρωμένο οδηγό, θα εξετάσουμε το Gemma 2 σε βάθος, εξετάζοντας την αρχιτεκτονική του, τα βασικά χαρακτηριστικά και τις πρακτικές εφαρμογές του. Ανεξάρτητα από το αν είστε έμπειρος επαγγελματίας του AI ή ενθουσιώδης νέος στην περιοχή, αυτό το άρθρο στοχεύει να παρέχει宝貴ες πληροφορίες σχετικά με το πώς λειτουργεί το Gemma 2 και πώς μπορείτε να εκμεταλλευτείτε τη δύναμή του στα δικά σας έργα.
Τι είναι το Gemma 2;
Το Gemma 2 είναι το νέο ανοικτό μοντέλο μεγάλης κλίμακας γλώσσας της Google, σχεδιασμένο να είναι ελαφρύ αλλά ισχυρό. Κατασκευάζεται με βάση την ίδια έρευνα και τεχνολογία που χρησιμοποιήθηκε για τη δημιουργία των μοντέλων Gemini της Google, προσφέροντας απόδοση κορυφής σε ένα πιο προσιτό πακέτο. Το Gemma 2 διατίθεται σε δύο μεγέθη:
Gemma 2 9B: Ένα μοντέλο 9 δισεκατομμυρίων παραμέτρων
Gemma 2 27B: Ένα μεγαλύτερο μοντέλο 27 δισεκατομμυρίων παραμέτρων
Κάθε μέγεθος είναι διαθέσιμο σε δύο παραλλαγές:
Βασικά μοντέλα: Προ-εκπαιδευμένα σε một τεράστιο σώμα κειμένου
Μοντέλα ενημερωμένα με οδηγίες (IT): Λειτούργησαν για καλύτερη απόδοση σε συγκεκριμένες εργασίες
Πρόσβαση στα μοντέλα στο Google AI Studio: Google AI Studio – Gemma 2
Διαβάστε την τεχνική αναφορά εδώ: Τεχνική Αναφορά Gemma 2
Κύρια Χαρακτηριστικά και Βελτιώσεις
Το Gemma 2 εισάγει několik σημαντικών προόδων σε σχέση με τον προκάτοχό του:
1. Αυξημένα Δεδομένα Εκπαίδευσης
Τα μοντέλα έχουν εκπαιδευτεί σε σημαντικά περισσότερα δεδομένα:
Gemma 2 27B: Εκπαιδευμένο σε 13 τρισεκατομμύρια tokens
Gemma 2 9B: Εκπαιδευμένο σε 8 τρισεκατομμύρια tokens
Αυτή η διευρυμένη βάση δεδομένων, που αποτελείται κυρίως από δεδομένα του web (κυρίως αγγλικά), κώδικα και μαθηματικών, συμβάλλει στις βελτιωμένες επιδόσεις και την ευελιξία των μοντέλων.
2. Μηχανισμός Προσοχής με Ολισθηρό Παραθύρο
Το Gemma 2 εφαρμόζει μια νέα προσέγγιση για τους μηχανισμούς προσοχής:
Κάθε δεύτερος όρο χρησιμοποιεί μια προσοχή με ολισθηρό παραθύρο με τοπικό контέκστ 4096 tokens
Εναλλάξιμοι όροι χρησιμοποιούν πλήρη квадρατική παγκόσμια προσοχή σε ολόκληρο το контέκστ 8192 tokens
Αυτή η υβριδική προσέγγιση στοχεύει να ισορροπήσει την αποδοτικότητα με την ικανότητα να καταγράφει μακροπρόθεσμες εξαρτήσεις στην είσοδο.
3. Soft-Capping
Για τη βελτίωση της σταθερότητας και της απόδοσης της εκπαίδευσης, το Gemma 2 εισάγει einen μηχανισμό soft-capping:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Εφαρμογή στους λογαρίθμους προσοχής attention_logits = soft_cap(attention_logits, cap=50.0) # Εφαρμογή στους τελικούς λογαρίθμους final_logits = soft_cap(final_logits, cap=30.0)
Αυτή η τεχνική αποτρέπει τους λογαρίθμους από το να μεγαλώσουν υπερβολικά χωρίς σκληρή τομή, διατηρώντας περισσότερες πληροφορίες ενώ σταθεροποιεί τη διαδικασία εκπαίδευσης.
- Gemma 2 9B: Ένα μοντέλο 9 δισεκατομμυρίων παραμέτρων
- Gemma 2 27B: Ένα μεγαλύτερο μοντέλο 27 δισεκατομμυρίων παραμέτρων
Κάθε μέγεθος είναι διαθέσιμο σε δύο παραλλαγές:
- Βασικά μοντέλα: Προ-εκπαιδευμένα σε ένα τεράστιο σώμα κειμένου
- Μοντέλα ενημερωμένα με οδηγίες (IT): Λειτούργησαν για καλύτερη απόδοση σε συγκεκριμένες εργασίες
4. Απόσταξη Γνώσης
Για το μοντέλο 9B, το Gemma 2 χρησιμοποιεί τεχνικές απόσταξης γνώσης:
- Προ-εκπαίδευση: Το μοντέλο 9B μαθαίνει από ένα μεγαλύτερο δάσκαλο κατά τη διάρκεια της αρχικής εκπαίδευσης
- Μετα-εκπαίδευση: Και τα δύο μοντέλα 9B και 27B χρησιμοποιούν απόσταξη πολιτικής για να βελτιώσουν την απόδοσή τους
Αυτή η διαδικασία βοηθά το μικρότερο μοντέλο να καταγράψει τις ικανότητες των μεγαλύτερων μοντέλων πιο αποτελεσματικά.
5. Συγχώνευση Μοντέλων
Το Gemma 2 χρησιμοποιεί μια νέα τεχνική συγχώνευσης μοντέλων που ονομάζεται Warp, η οποία συνδυάζει πολλά μοντέλα σε τρία στάδια:
- Εξονυχιστική Κίνηση Μέσων (EMA) κατά τη διάρκεια της εκπαίδευσης με ενίσχυση
- Σφαιρική Γραμμική Διασύνδεση (SLERP) μετά την εκπαίδευση πολλών πολιτικών
- Γραμμική Διασύνδεση προς την Αρχική Κατάσταση (LITI) ως τελικό βήμα
Αυτή η προσέγγιση στοχεύει να δημιουργήσει ένα πιο robust και ικανό τελικό μοντέλο.
Βενζίνες Απόδοσης
Το Gemma 2 παρουσιάζει εντυπωσιακή απόδοση σε διάφορες βενζίνες:
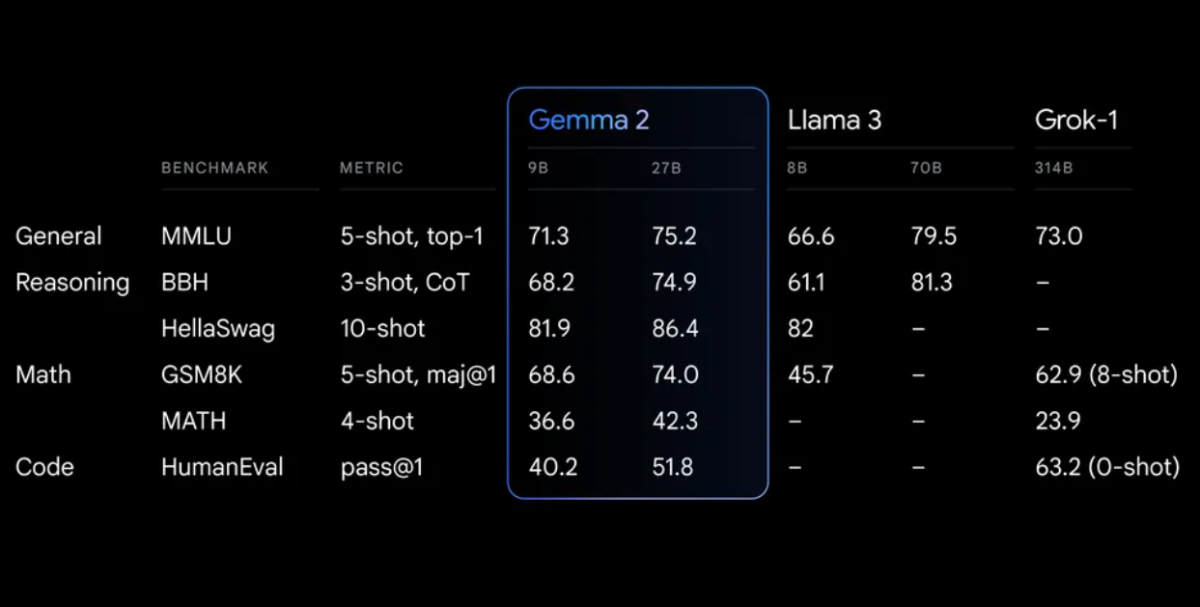
Gemma 2 on a redesigned architecture, engineered for both exceptional performance and inference efficiency
Εκκίνηση με το Gemma 2
Για να αρχίσετε να χρησιμοποιείτε το Gemma 2 στα δικά σας έργα, έχετε beberapa επιλογές:
1. Google AI Studio
Για γρήγορη πειραματισμό χωρίς απαιτήσεις υλικού, μπορείτε να αποκτήσετε πρόσβαση στο Gemma 2 μέσω Google AI Studio.
2. Hugging Face Transformers
Το Gemma 2 είναι ενσωματωμένο με τη δημοφιλή βιβλιοθήκη Hugging Face Transformers. Εδώ είναι πώς μπορείτε να το χρησιμοποιήσετε:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Φόρτωση του μοντέλου και του tokenizer model_name = "google/gemma-2-27b-it" # ή "google/gemma-2-9b-it" για την μικρότερη έκδοση tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Προετοιμασία εισόδου prompt = "Εξηγήστε την έννοια της κβαντικής εμβάπτισης με απλά λόγια." inputs = tokenizer(prompt, return_tensors="pt") # Γεννήστε κείμενο outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Για τους χρήστες του TensorFlow, το Gemma 2 είναι διαθέσιμο μέσω του Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Φόρτωση του μοντέλου
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Γεννήστε κείμενο
prompt = "Εξηγήστε την έννοια της κβαντικής εμβάπτισης με απλά λόγια."
output = model.generate(prompt, max_length=200)
print(output)
Προηγμένη Χρήση: Δημιουργία ενός Τοπικού Συστήματος RAG με το Gemma 2
Μια ισχυρή εφαρμογή του Gemma 2 είναι η δημιουργία ενός Συστήματος Αυξημένης Αναζήτησης και Γεννήσεως (RAG). Ας δημιουργήσουμε ένα απλό, πλήρως τοπικό σύστημα RAG χρησιμοποιώντας το Gemma 2 και τις ενσωματώσεις Nomic.
Βήμα 1: Ρύθμιση του Περιβάλλοντος
Πρώτα, βεβαιωθείτε ότι έχετε εγκαταστήσει τις απαραίτητες βιβλιοθήκες:
pip install langchain ollama nomic chromadb
Βήμα 2: Δείκτης Εγγράφων
Δημιουργήστε einen δείκτη για την επεξεργασία των εγγράφων σας:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












