Kunstig intelligens
Tre udfordringer foran for Stable Diffusion

Udgivelsen af stability.ai’s Stable Diffusion latent diffusion billedsynthesemodell for et par uger siden kan være en af de mest betydningsfulde teknologiske afsløringer siden DeCSS i 1999; det er bestemt det største begivenhed i AI-genereret billedmateriale siden den 2017 deepfakes kode blev kopieret over til GitHub og forket til, hvad der blev til DeepFaceLab og FaceSwap, samt det realtid streaming deepfake software DeepFaceLive.
Ved et slag blev brugerfrustrationen over begrænsningerne i DALL-E 2’s billedsynthesi API sat til side, da det viste sig, at Stable Diffusions NSFW-filter kunne deaktiveres ved at ændre en enkelt linje kode. Pornocentriske Stable Diffusion Reddits dukkede op næsten med det samme, og blev lige så hurtigt lukket ned, mens udvikler- og brugerlejren splittede sig på Discord i officielle og NSFW-fællesskaber, og Twitter begyndte at blive fyldt op med fantastiske Stable Diffusion-kreationer.
For øjeblikket synes hver dag at bringe nogle fantastiske innovationer fra udviklerne, der har antaget systemet, med plugins og tredjeparts-tilføjelser, der hastigt skrives til Krita, Photoshop, Cinema4D, Blender og mange andre applikationsplatforme.
Imens er promptcraft – den nu professionelle kunst af ‘AI-whispering’, som måske ender med at være den kortest levende karriere mulighed siden ‘Filofax-binder’ – allerede blevet kommercielt, mens tidlig monetisering af Stable Diffusion finder sted på Patreon-niveauet, med sikkerhed for mere avancerede tilbud til at komme, for dem, der ikke vil navigere i Conda-baserede installationer af kildekoden eller de proskriptive NSFW-filtre i webbaserede implementationer.
Udviklingstempoet og den frie fornemmelse af udforskning fra brugerne sker i sådan en svimlende fart, at det er svært at se meget langt frem. Essentieligt set ved vi ikke helt, hvad vi har med at gøre endnu, eller hvad alle begrænsningerne eller mulighederne måtte være.
Alligevel lad os kaste et blik på tre af, hvad der måske er de mest interessante og udfordrende hinder for den hurtigt dannede og hurtigt voksende Stable Diffusion-fællesskab at møde og, håbefuldt, overvinde.
1: Optimering af tile-baserede rørledninger
Præsenteret med begrænsede hardwareressourcer og hårde grænser for opløsningen af træningsbilleder, synes det sandsynligt, at udviklerne vil finde løsninger til at forbedre både kvaliteten og opløsningen af Stable Diffusions output. Mange af disse projekter er sat til at udnytte begrænsningerne i systemet, såsom dets native opløsning på kun 512×512 pixels.
Som altid er tilfældet med computer vision og billedsynthesi-initiativer, blev Stable Diffusion trænet på kvadratisk forholdsbilleder, i dette tilfælde resampleret til 512×512, således at kildebillederne kunne regulariseres og være i stand til at passe inden for begrænsningerne af de GPU’er, der trænede modellen.
Derfor “tænker” Stable Diffusion (hvis det overhovedet tænker) i 512×512-termer, og bestemt i kvadratisk forhold. Mange brugere, der i øjeblikket udforsker begrænsningerne af systemet, rapporterer, at Stable Diffusion producerer de mest pålidelige og mindst glitchy resultater ved denne ret begrænsede aspektforhold (se ‘adressering af yderpunkter’ nedenfor).
Selvom forskellige implementationer har upscaling via RealESRGAN (og kan fikse dårligt renderede ansigter via GFPGAN) er flere brugere i øjeblikket ved at udvikle metoder til at splitte billeder op i 512x512px-sektioner og sy sammen billederne for at danne større sammensatte værker.

Dette 1024×576-render, en opløsning, der ellers er umulig i en enkelt Stable Diffusion-render, blev skabt ved at kopiere og indsætte attention.py Python-filen fra DoggettX-forken af Stable Diffusion (en version, der implementerer tile-baseret upscaling) i en anden fork. Kilde: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Selvom nogle initiativer af denne type bruger original kode eller andre biblioteker, er txt2imghd-porten af GOBIG (en mode i den VRAM-sultne ProgRockDiffusion) sat til at give denne funktionalitet til hovedgrenen snart. Mens txt2imghd er en dedikeret port af GOBIG, indebærer andre bestræbelser fra fællesskabsudviklere forskellige implementationer af GOBIG.

Et praktisk abstrakt billede i den originale 512x512px-render (venstre og anden fra venstre); opskalet af ESGRAN, der nu er mere eller mindre naturlig på tværs af alle Stable Diffusion-distributioner; og givet ‘speciel opmærksomhed’ via en implementering af GOBIG, der producerer detaljer, der, i hvert fald inden for billedets sektion, synes bedre opskalet. Kilde: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Den type abstrakt eksempel, der er nævnt ovenfor, har mange ‘lille kongeriger’ af detaljer, der passer denne solipsistiske tilgang til upscaling, men som måske kræver mere udfordrende kode-drevne løsninger for at producere ikke-repetitive, sammenhængende upscaling, der ikke ser ud til at være sammensat af mange dele. Ikke mindst i tilfælde af menneskeansigter, hvor vi er usædvanligt tilbøjelige til at bemærke afvigelser eller ‘chokerende’ artefakter. Derfor kan ansigter måske til sidst kræve en dedikeret løsning.
Stable Diffusion har i øjeblikket ingen mekanisme for at fokusere opmærksomheden på ansigtet under en render i samme måde, som mennesker prioriterer ansigtsinformation. Selvom nogle udviklere i Discord-fællesskaberne overvejer metoder til at implementere denne type ‘forbedret opmærksomhed’, er det i øjeblikket meget lettere at manuelt (og, til sidst, automatisk) forbedre ansigtet efter den første render har fundet sted.
Et menneskeansigt har en intern og fuldstændig semantisk logik, der ikke vil findes i en ‘flise’ af bunden af (for eksempel) en bygning, og derfor er det i øjeblikket muligt at meget effektivt ‘zoome ind’ og rendre et ‘skitseret’ ansigt i Stable Diffusions output.

Venstre, Stable Diffusions første forsøg med prompten ‘Full-længde farvefoto af Christina Hendricks, der går ind i en overfyldt lokalitet, iført en regnfrakke; Canon50, øjenkontakt, høj detalje, høj ansigtsdetalje’. Højre, et forbedret ansigt, der er opnået ved at føde det uklare og skitserede ansigt fra den første render tilbage ind i Stable Diffusions fulde opmærksomhed ved hjælp af Img2Img (se animerede billeder nedenfor).
I manglen på en dedikeret Textual Inversion-løsning (se nedenfor) vil dette kun fungere for berømthedsbilleder, hvor personen i spørgsmål allerede er godt repræsenteret i LAION-datasubsets, der trænede Stable Diffusion. Derfor vil det fungere på personer som Tom Cruise, Brad Pitt, Jennifer Lawrence og en begrænset række af ægte mediepersonligheder, der er til stede i store mængder af billeder i kilde-dataene.
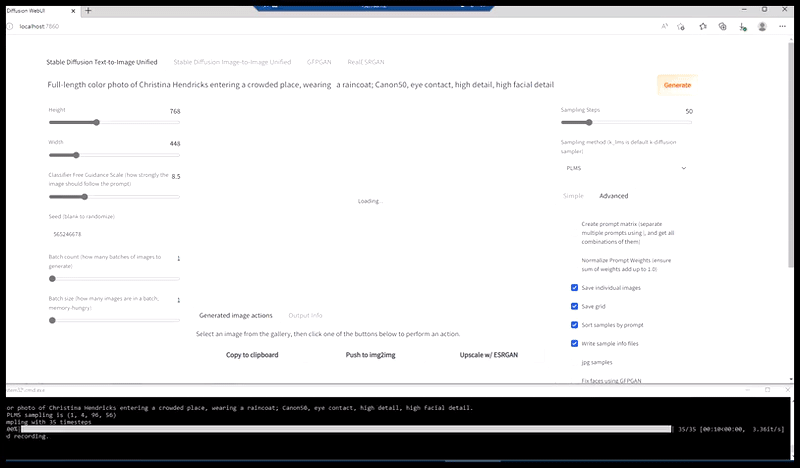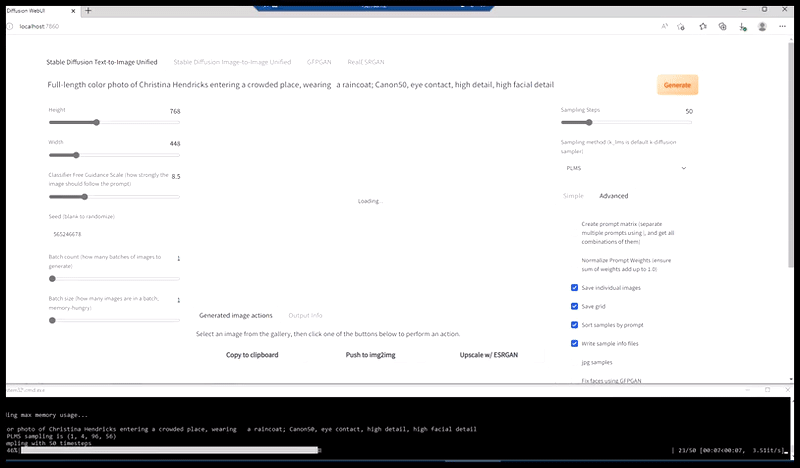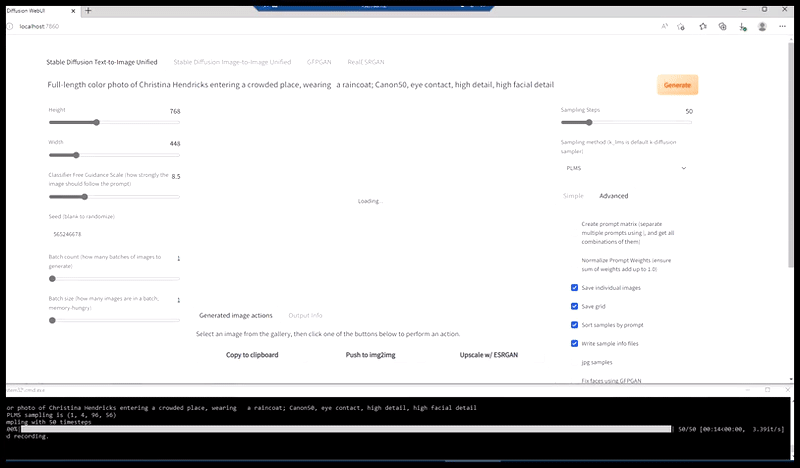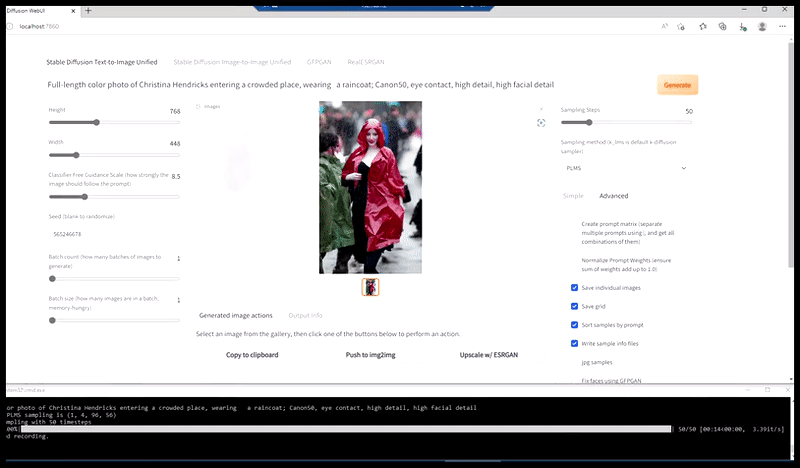
Generering af et troværdigt presbillede med prompten ‘Full-længde farvefoto af Christina Hendricks, der går ind i en overfyldt lokalitet, iført en regnfrakke; Canon50, øjenkontakt, høj detalje, høj ansigtsdetalje’.
For berømtheder med lange og varige karrierer vil Stable Diffusion som regel generere et billede af personen i en senere (dvs. ældre) alder, og det vil være nødvendigt at tilføje prompt-tilføjelser som ‘ung’ eller ‘i år [ÅR]’ for at producere yngre udseende billeder.

Med en fremtrædende, meget fotograferet og konsekvent karriere, der strækker sig over næsten 40 år, er skuespilleren Jennifer Connelly en af en håndfuld berømtheder i LAION, der tillader Stable Diffusion at repræsentere en række aldre. Kilde: prepack Stable Diffusion, lokal, v1.4 checkpoint; aldersrelaterede prompts.
Dette skyldes primært den udbredte digitale (i stedet for dyre, emulsionsbaserede) presfotografering fra midten af 2000’erne og den senere vækst i billedoutput på grund af øgede bredbånds-hastigheder.
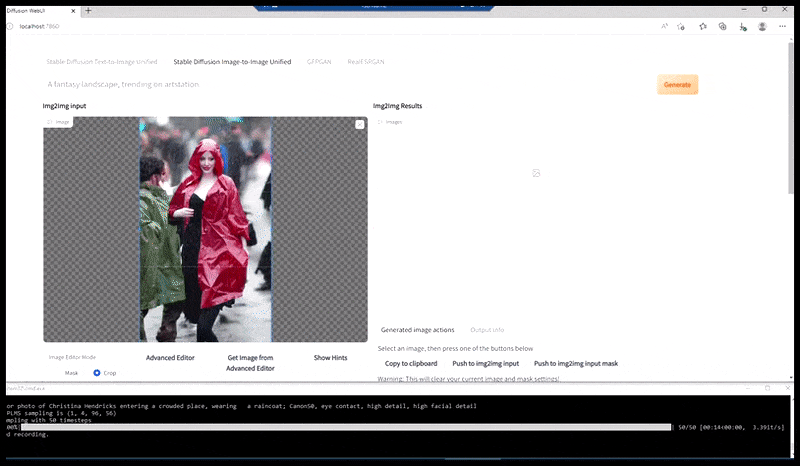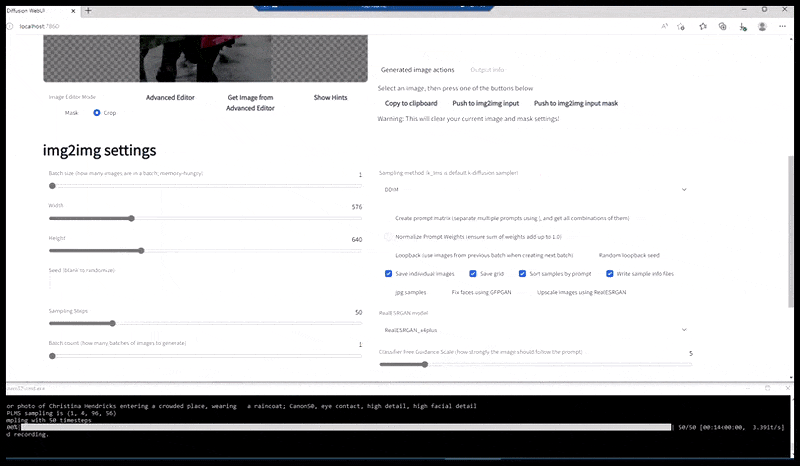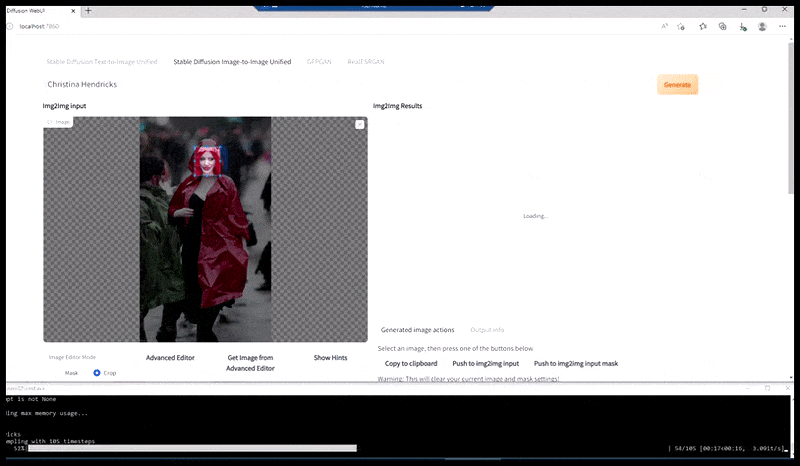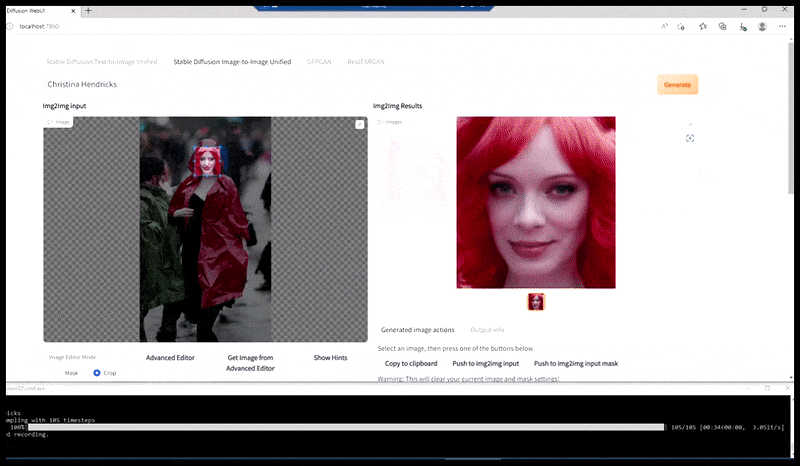
Det renderede billede føres videre til Img2Img i Stable Diffusion, hvor et ‘fokusområde’ vælges, og en ny, maksimum-størrelses-render lavet kun af det område, hvilket giver Stable Diffusion mulighed for at koncentrere alle tilgængelige ressourcer om at genskabe ansigtet.
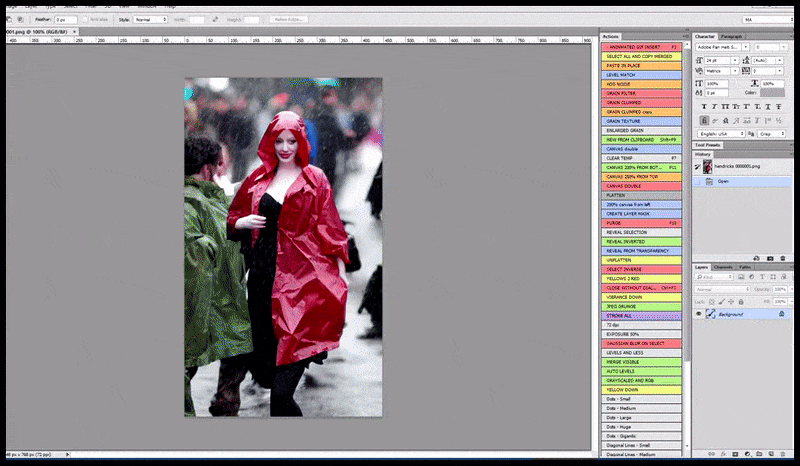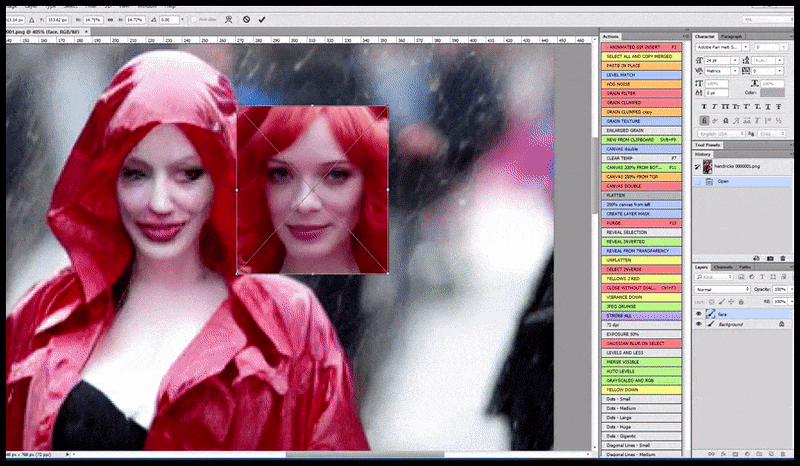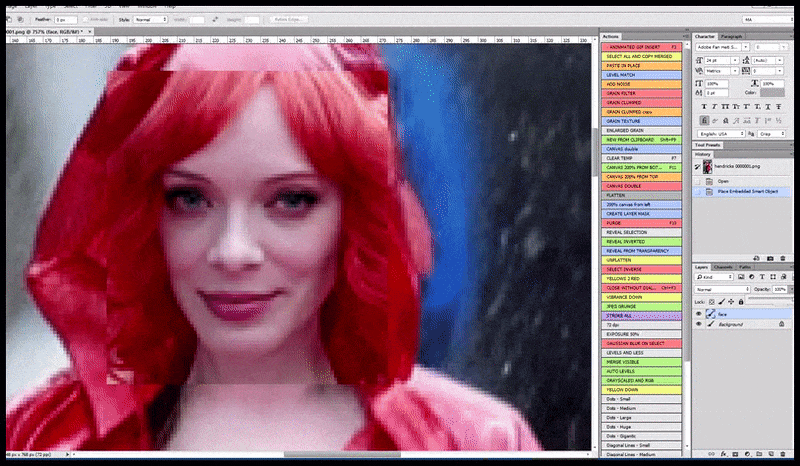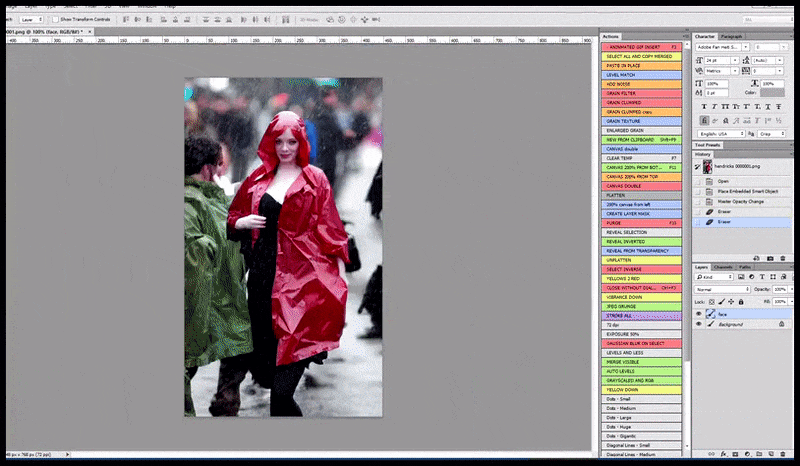
Komponering af ‘høj opmærksomhed’-ansigtet tilbage i den originale render. Ud over ansigter vil denne proces kun fungere med enheder, der har en potentiel kendt, sammenhængende og integral udseende, såsom en del af det originale foto, der har en distinkt genstand, såsom en ur eller en bil. Opskaling af en sektion af – for eksempel – en væg vil føre til en meget underlig genassembleret væg, fordi flisegrenderne havde ingen bredere kontekst for denne ‘puzzle-piece’, da de renderede.
Nogle berømtheder i databasen kommer ‘forfrosne’ i tid, enten fordi de døde tidligt (såsom Marilyn Monroe) eller opnåede kun en flygtig mainstream-popularitet, og producerede en stor mængde billeder i en begrænset periode. Afstemning af Stable Diffusion giver måske en slags ‘nuværende’ popularitetsindeks for moderne og ældre stjerner. For nogle ældre og nuværende berømtheder er der ikke nok billeder i kilde-dataene til at opnå et meget godt lighed, mens den vedvarende popularitet af bestemte længe døde eller andre forsvundne stjerner sikrer, at deres rimelige lighed kan opnås fra systemet.

Stable Diffusions renderinger afslører hurtigt, hvilke berømte ansigter, der er godt repræsenteret i træningsdataene. Trods hendes enorme popularitet som en ældre teenager på tidspunktet for skrivningen, var Millie Bobby Brown yngre og mindre kendt, da LAION-kilde-datasættene blev skrabet fra webben, hvilket gjorde det problematisk at opnå et højkvalitets-lighed med Stable Diffusion på nuværende tidspunkt.
Hvor data er tilgængelig, kunne tile-baserede up-res-løsninger i Stable Diffusion gå videre end at fokusere på ansigtet: de kunne potentielt aktivere endnu mere præcise og detaljerede ansigter ved at bryde ansigtstrækkene ned og vende den fulde kraft af lokale GPU-ressourcer på betydningsfulde funktioner individuelt, før genassemblage – en proces, der i øjeblikket igen er manuel.

Dette er ikke begrænset til ansigter, men det er begrænset til dele af objekter, der er mindst lige så forudsigeligt placeret i den bredere kontekst af værten-objektet, og som overholder højniveaudybdelser, som man rimeligvis kan forvente at finde i en hyperskala-datasæt.
Den virkelige begrænsning er mængden af tilgængelige reference-data i datasættet, fordi dybt-itereret detalje til sidst vil blive helt ‘hallucineret’ (dvs. fiktiv) og mindre autentisk.
Sådanne højniveaudybdelser fungerer i tilfældet med Jennifer Connelly, fordi hun er godt repræsenteret på tværs af en række aldre i LAION-aesthetics (den primære undergruppe af LAION 5B, som Stable Diffusion bruger), og generelt på tværs af LAION; i mange andre tilfælde ville nøjagtigheden lide under mangel på data, hvilket nødvendiggør enten finjustering (yderligere træning, se ‘Tilpasning’ nedenfor) eller Textual Inversion (se nedenfor).
Fliser er en kraftfuld og relativt billig måde for Stable Diffusion at være i stand til at producere hi-res-output, men algoritme-baseret flise-upscaling af denne type, hvis den mangler en slags bredere, højere niveau-opmærksomheds-mekanisme, kan falde kort af de håbede standarder på tværs af en række indholdstyper.
2: Tilpasning af menneskelige lemmer
Stable Diffusion holder ikke målet, når det kommer til at afbilde kompleksiteten af menneskelige yderpunkter. Hænder kan multiplicere tilfældigt, fingre samles, en tredje ben dukker op uanmeldt, og eksisterende lemmer forsvinder uden spor. I sin forsvar er Stable Diffusion deltager i dette problem med sine stabile kammerater, og bestemt med DALL-E 2.

Uredigerede resultater fra DALL-E 2 og Stable Diffusion (1.4) ved udgangen af august 2022, begge viser problemer med lemmer. Prompt er ‘En kvinde omfavner en mand’
Stable Diffusion-entusiaster, der håber, at den forestående 1.5-checkpoint (en mere intensivt trænet version af modellen med forbedrede parametre) ville løse lem-problemet, er sandsynligvis til at blive skuffede. Den nye model, der vil blive udgivet om cirka to ugers tid, er i øjeblikket ved at blive præsenteret på det kommercielle stability.ai-portalen DreamStudio, der bruger 1.5 som standard, og hvor brugere kan sammenligne den nye output med renderinger fra deres lokale eller andre 1.4-systemer:

Kilde: Lokal 1.4 prepack og https://beta.dreamstudio.ai/

Kilde: Lokal 1.4 prepack og https://beta.dreamstudio.ai/

Kilde: Lokal 1.4 prepack og https://beta.dreamstudio.ai/
Som ofte er tilfældet, kan datakvalitet godt være den primære bidragende årsag.
De åbne kilde-databaser, der driver billedsynthesi-systemer som Stable Diffusion og DALL-E 2, kan give mange mærker for både enkelte mennesker og inter-menneskelig handling. Disse mærker trænes symbiotisk med deres associerede billeder eller billedsegmenter.

Stable Diffusion-brugere kan udforske koncepterne, der er trænet ind i modellen, ved at forespørge LAION-aesthetics-datasættet, en undergruppe af den større LAION 5B-datasæt, der driver systemet. Billederne er sorteret ikke efter deres alfabetiske mærker, men efter deres ‘æstetiske score’. Kilde: https://rom1504.github.io/clip-retrieval/
En god hierarki af enkelt-mærker og klasser, der bidrager til afbildningen af et menneskearm, ville være noget i retning af krop>arm>hånd>fingre>[under-fingre + tommelfinger]> [fingre-segmenter]> Fingernegle.

Granuleret semantisk segmentering af håndens dele. Selv denne usædvanligt detaljerede dekonstruktion efterlader hver ‘finger’ som en enkelt enhed, uden at tage højde for de tre sektioner af en finger og de to sektioner af en tommelfinger Kilde: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
I virkeligheden er kildebillederne sandsynligvis ikke så konsekvent annoterede på tværs af hele datasættet, og usupervised mærkningsalgoritmer vil sandsynligvis stoppe på det højere niveau af – for eksempel – ‘hånd’, og efterlade de indre pixler (der teknisk set indeholder ‘finger’-information) som en umærket masse af pixler, hvorfra funktioner vil blive arbitrært afledt, og som måske vil manifestere sig i senere renderinger som en chokerende enhed.

Hvor det burde være (øverst til højre, hvis ikke øverst skåret), og hvordan det tenderer til at være (nederst til højre), på grund af begrænsede ressourcer til mærkning eller arkitektonisk udnyttelse af sådanne mærker, hvis de findes i datasættet.
Derfor, hvis en latent diffusionsmodel kommer så langt som til at rendre en arm, er det næsten sikkert, at den vil have et forsøg på at rendre en hånd i enden af den arm, fordi arm>hånd er den minimale krævede hierarki, ret højt oppe i, hvad arkitekturen ved om ‘menneskeanatomi’.
Efter det kan ‘fingre’ være den mindste gruppering, selvom der er 14 yderligere finger/tommelfinger-underdele at overveje, når det kommer til at afbilde menneskehænder.
Hvis denne teori holder, er der ingen virkelig løsning, på grund af sektoren bredt manglende budget til manuel annotation, og manglen på tilstrækkeligt effektive algoritmer, der kunne automatisere mærkning, mens de producerer lave fejl-rater. I virkeligheden kan modellen måske i øjeblikket afhænge af menneskeanatomisk konsistens for at dække over datasættets mangler.
En mulig årsag til, at det ikke kan, nyligt forslagt på Stable Diffusion Discord, er, at modellen kunne blive forvirret om det korrekte antal fingre, et (realistisk) menneskehånd burde have, fordi LAION-databasen, der driver den, indeholder tegneseriefigurer, der måske har færre fingre (hvilket i sig selv er en arbejdssparende genvej).

To af de potentielle skyldige i ‘manglende finger’-syndromet i Stable Diffusion og lignende modeller. Nedenfor, eksempler på tegnehånd fra LAION-aesthetics-datasættet, der driver Stable Diffusion. Kilde: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Hvis dette er sandt, er den eneste åbenlyse løsning at træne modellen om, med exclusion af ikke-realistic menneskebaseret indhold, og sikre, at ægte tilfælde af udeladelse (dvs. amputerede) er passende mærket som undtagelser. Fra et data-curation-punkt er dette en ret stor udfordring, især for ressource-svagt fællesskabs-bestræbelser.
Den anden tilgang ville være at anvende filtre, der udelukker sådant indhold (dvs. ‘hånd med tre/fem fingre’) fra at manifestere sig under render-tid, på samme måde som OpenAI har, i en vis udstrækning, filtreret GPT-3 og DALL-E 2, så deres output kunne reguleres uden at skulle træne kilde-modellerne om.

For Stable Diffusion kan den semantiske forskel mellem cifre og endda lemmer blive forfærdeligt uklar, og bringer i tanke den 1980’eres ‘krop-rædsel’-strøm af horrorfilm fra folk som David Cronenberg. Kilde: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Der kunne dog være to tilbageværende veje fremad: kaste mere data på problemet, og anvende tredjeparts-tolkningssystemer, der kan gribe ind, når fysisk fejl af den type, der er beskrevet her, præsenteres for slutbrugeren (i hvert fald ville dette give OpenAI en metode til at give refusioner for ‘krop-rædsel’-renderinger, hvis virksomheden var motiveret til at gøre det).
3: Tilpasning
En af de mest spændende muligheder for fremtiden for Stable Diffusion er udsigten til, at brugere eller organisationer udvikler reviderede systemer; modifikationer, der tillader indhold uden for den forudtrænede LAION-sfære at blive integreret i systemet – idealiseret uden den ustyrlige omkostning af at træne hele modellen om igen, eller risikoen, der er forbundet med at træne i en stor mængde nyt indhold til en eksisterende, moden og kapabel model.
Ved analogi: hvis to mindre begavede studerende slutter sig til en avanceret klasse på 30 studerende, vil de enten assimilere og holde trit, eller fejle som outliers; i begge tilfælde vil klasse-gennemsnits-præstationen sandsynligvis ikke blive påvirket. Hvis 15 mindre begavede studerende slutter sig til, vil klasse-gennemsnits-kurven sandsynligvis lide.
På samme måde kan den synergistiske og ret sårbare netværk af relationer, der opbygges over en længere og dyrekøbt modeltræning, blive kompromitteret, i visse tilfælde effektivt ødelagt, af overmål af nyt indhold, hvilket sænker modellens output-kvalitet på tværs af brættet.
Tilfældet for at gøre dette er primært, hvor dit interesse ligger i at fuldstændigt kapre modellens konceptuelle forståelse af relationer og ting, og overtage det til eksklusiv produktion af indhold, der ligner det tilføjede materiale, du tilføjer.
Derfor er træning af 500.000 Simpsons-frames i en eksisterende Stable Diffusion-checkpoint sandsynligvis til sidst at få en bedre Simpsons-simulator end den originale bygning kunne have tilbudt, under forudsætning af, at tilstrækkeligt bredt semantisk relationer overlever processen (dvs. Homer Simpson spiser en hotdog, som måske kræver materiale om hotdogs, der ikke var i dit tilføjede materiale, men allerede eksisterede i checkpointet), og under forudsætning af, at du ikke pludselig skal skifte fra Simpsons-indhold til at skabe fabulous landscape by Greg Rutkowski – fordi din post-trænede model har haft sin opmærksomhed kraftigt omdirigeret, og ikke vil være så god til at gøre den slags ting, som den var før.
Et bemærkelsesværdigt eksempel på dette er waifu-diffusion, der har succesfuldt post-trænet 56.000 anime-billeder i en fuldt trænet Stable Diffusion-checkpoint. Det er en hård opgave for en hobbyist, da modellen kræver en øjenåbnende minimum på 30GB VRAM, langt ud over, hvad der sandsynligvis er tilgængeligt på forbruger-niveauet i NVIDIAs kommende 40XX-serie-udgivelser.

Træningen af brugerdefineret indhold i Stable Diffusion via waifu-diffusion: modellen tog to uger med post-træning for at producere dette niveau af illustration. De seks billeder til venstre viser modellens fremgang i at producere emne-kohærent output baseret på det nye træningsdata. Kilde: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
En stor indsats kan blive brugt på sådanne ‘forks’ af Stable Diffusion-checkpoints, kun for at blive stillet tilbage af teknisk gæld. Udviklere på det officielle Discord har allerede indikeret, at senere checkpoint-udgivelser ikke nødvendigvis er bagud-kompatible, selv med prompt-logik, der måske har fungeret med en tidligere version, da deres primære interesse er i at opnå den bedste model mulig, snarere end at understøtte arv-applikationer og processer.
Derfor har en virksomhed eller en person, der beslutter at forkke en checkpoint til en kommerciel produkt, ingen vej tilbage; deres version af modellen er, på dette punkt, en ‘hard fork’, og vil ikke være i stand til at trække fordel af upstream-fordele fra senere udgivelser fra stability.ai – hvilket er en ret stor forpligtelse.
Den nuværende og større håb for tilpasning af Stable Diffusion er Textual Inversion, hvor brugeren træner ind i en lille håndfuld CLIP-alignerede billeder.

Et samarbejde mellem Tel Aviv Universitet og NVIDIA, tekstuel inversion tillader træning af diskrete og nyt indhold, uden at ødelægge kildemodellens evner. Kilde: https://textual-inversion.github.io/
Den primære åbenlyse begrænsning af tekstuel inversion er, at et meget lavt antal billeder anbefales – så få som fem. Dette producerer i virkeligheden en begrænset enhed, der måske er mere nyttig til stil-overførsel-opgaver end til indsættelse af fotorealistiske objekter.
Alligevel er eksperimenter i øjeblikket i gang inden for de forskellige Stable Diffusion Discords, der bruger langt højere antal træningsbilleder, og det er uvist, hvor produktiv metoden kan vise sig at være. Igen kræver teknikken en stor mængde VRAM, tid og tålmodighed.
På grund af disse begrænsninger kan vi måske skulle vente lidt, før vi ser nogle af de mere avancerede tekstuelle inversion-eksperimenter fra Stable Diffusion-entusiaster – og om denne tilgang kan ‘sætte dig i billedet’ på en måde, der ser bedre ud end en Photoshop-klip-og-lim, mens den bevarende den forbløffende funktionalitet af de officielle checkpoints.
Først udgivet 6. september 2022.












