Kunstig intelligens
Farene ved at bruge citater til at autentificere NLG-indhold

Opinion Naturalsprogsgenereringsmodeller som GPT-3 er prone to ‘hallucinate’ materiale, som de præsenterer i konteksten af faktuel information. I en æra, der er ekstraordinært bekymret for væksten af tekstbaseret fake news, repræsenterer disse ‘eager to please’ flugt af fantasi en eksistensen hindring for udviklingen af automatiserede skrivnings- og sammenfatningssystemer og for fremtiden for AI-dreven journalistik, blandt andre undersektorer af Naturalsprogsbehandling (NLP).
Det centrale problem er, at GPT-stil sprogmodeller udleder nøglefunktioner og klasser fra meget store korpora af træningsTekster og lærer at bruge disse funktioner som byggesten til sprog på en dygtig og autentisk måde, uanset den genererede indholds nøjagtighed eller endda dets acceptabilitet.
NLG-systemer afhænger derfor i øjeblikket af menneskelig verificering af fakta i en af to tilgange: enten bruges modellerne som sædtekst-genereringsmodeller, der straks overføres til menneskelige brugere, enten til verificering eller en anden form for redigering eller tilpasning; eller mennesker bruges som dyre filtre til at forbedre kvaliteten af datasæt, der er tiltænkt at informere mindre abstrakte og ‘kreative’ modeller (der i sig selv er svært at stole på i forhold til faktuel nøjagtighed og som vil kræve yderligere lag af menneskelig tilsyn).
Gammel nyheder og falske fakta
Naturalsprogsgenereringsmodeller (NLG) kan producere overbevisende og plausibel output, fordi de har lært semantisk arkitektur, snarere end mere abstrakt at assimilere den faktiske historie, videnskab, økonomi eller andre emner, som de måtte være påkrævet at udtale sig om, som effektivt er sammenflettede som ‘passagerer’ i kilde-data.
Den faktuelle nøjagtighed af den information, som NLG-modeller genererer, antager, at input, som de trænes på, i sig selv er pålidelig og opdateret, hvilket præsenterer en ekstraordinær byrde i forhold til forarbejdning og yderligere menneskebaseret verificering – en kostbar hindring, som NLP-forskningssektoren i øjeblikket adresserer på mange fronter.
GPT-3-skala systemer tager en ekstraordinær lang tid og penge at træne, og når de er trænet, er de svære at opdatere på, hvad der kan betragtes som ‘kernel-niveau’. Selvom session-baserede og bruger-baserede lokale ændringer kan øge nyttigheden og nøjagtigheden af de implementerede modeller, er disse nyttige fordele svære, undertiden umulige at overføre tilbage til kerne-modellen uden at kræve fuld eller delvis gen-træning.
Derfor er det svært at oprette trænede sprogmodeller, der kan udnytte den seneste information.

Trænet før selv COVID, text-davinci-002 – iterationen af GPT-3, der anses for ‘mest kapabel’ af dens skaber OpenAI – kan behandle 4000 tokens per anmodning, men kender intet til COVID-19 eller den ukrainske invasion i 2022 (disse prompts og svar er fra 5. april 2022). Interessant nok er ‘ukendt’ faktisk et acceptabelt svar i begge fejltilfælde, men yderligere prompts etablerer let, at GPT-3 er uvidende om disse begivenheder. Kilde: https://beta.openai.com/playground
En trænet model kan kun tilgå ‘sandheder’, som den internaliserede under træningstiden, og det er svært at få et præcist og relevant citat som standard, når man forsøger at få modellen til at verificere sine påstande. Den virkelige fare ved at opnå citater fra standard GPT-3 (for eksempel) er, at den nogen gange producerer korrekte citater, hvilket fører til en falsk tillid til denne facette af dens evner:

Top, tre præcise citater erhvervet af 2021-æra davinci-instruct-text GPT-3. Center, GPT-3 fejler at citerer en af Einsteins mest berømte citater (“Gud spiller ikke terninger med universet”), på trods af en ikke-kryptisk prompt. Bund, GPT-3 tilknytter et skandaløst og fiktivt citat til Albert Einstein, åbenbart overskyl fra tidligere spørgsmål om Winston Churchill i samme session. Kilde: Forfatterens egen artikel fra 2021 på https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
I håb om at adressere denne generelle svaghed i NLG-modeller, har Google’s DeepMind nyligt foreslået GopherCite, en 280-milliard parameter model, der er i stand til at citerer specifik og præcis bevis i støtte for dens genererede svar på prompts.



Tre eksempler på GopherCite, der bakker op om sine påstande med virkelige citater. Kilde: https://arxiv.org/pdf/2203.11147.pdf
GopherCite udnytter forstærket læring fra menneskelige præferencer (RLHP) til at træne spørgsmålsmodeller, der kan citerer virkelige citater som støttebevis. Citaterne hentes live fra multiple dokumentkilder, der er erhvervet fra søgemaskiner eller fra et specifikt dokument, der er leveret af brugeren.
GopherCites præstation blev målt gennem menneskelig evaluering af modellens svar, der blev fundet at være ‘høj kvalitet’ 80% af tiden på Googles NaturalQuestions datasæt og 67% af tiden på ELI5 datasættet.
Citerer falskheder
Men når den blev testet mod Oxford Universitets TruthfulQA benchmark, var GopherCites svar sjældent vurderet som sande i forhold til de menneskekurerede ‘korrekte’ svar.
Forfatterne foreslår, at dette skyldes, at konceptet ‘understøttede svar’ ikke på nogen objektiv måde hjælper med at definere sandhed i sig selv, da nyttigheden af kildecitater kan være kompromitteret af andre faktorer, såsom muligheden for, at forfatteren af citatet selv ‘hallucinerer’ (dvs. skriver om fiktive verdener, producerer reklameindhold eller på anden måde fantastiserer uægte materiale.



GopherCite tilfælde, hvor plausibilitet ikke nødvendigvis er lig med ‘sandhed’.
Effektivt bliver det nødvendigt at skelne mellem ‘understøttet’ og ‘sandt’ i sådanne tilfælde. Menneskelig kultur er i øjeblikket langt foran maskinlæring i forhold til brugen af metoder og rammer, der er designet til at opnå objektive definitioner af sandhed, og selv der, synes den native tilstand af ‘vigtig’ sandhed at være kontention og marginal benægtelse.
Problemet er rekursivt i NLG-arkitekturer, der søger at udvikle definitive ‘korroborerende’ mekanismer: menneskeledet konsensus presses i tjeneste som en benchmark for sandhed gennem outsourced, AMT-style modeller, hvor de menneskelige evalueringer (og andre mennesker, der mægler uenigheder mellem dem) er i sig selv partiske og fordomsfulde.
For eksempel bruger de initiale GopherCite-eksperimenter en ‘super rater’-model til at vælge de bedste menneskelige emner til at evaluere modellens output, hvor kun de rater, der scorede mindst 85% i forhold til en kvalitets sikkerhedssæt, blev valgt. Til sidst blev 113 super-ratere valgt til opgaven.
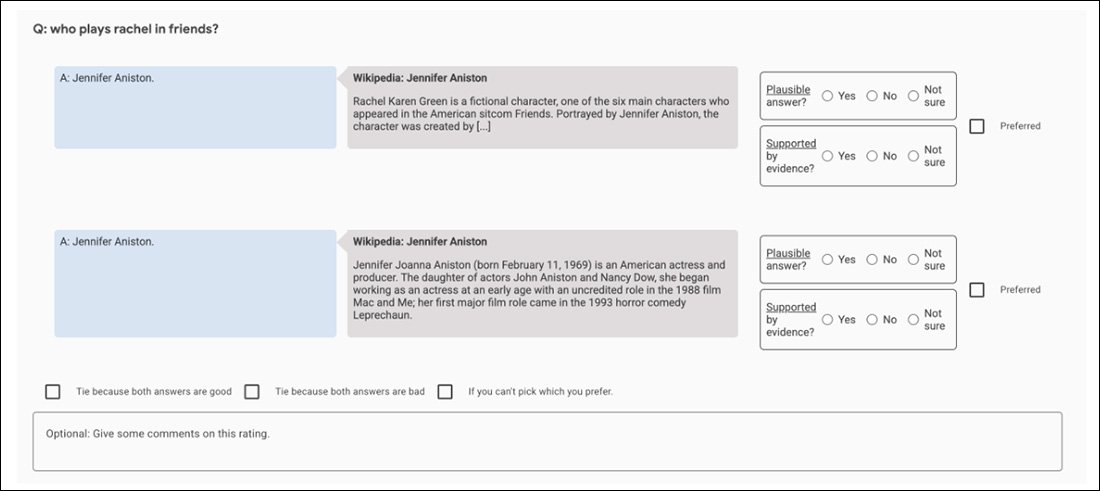
Skærmbillede af sammenlignings-appen, der hjælper med at evaluere GopherCites output.
Det kan argumenteres for, at dette er et perfekt billede af en uovervindelig fraktal jagt: kvalitets sikkerhedssættet, der bruges til at vurdere raterne, er i sig selv en anden ‘menneske-defineret’ målestok for sandhed, ligesom Oxford TruthfulQA-sættet, som GopherCite er blevet fundet mangelfuld over for.
I forhold til understøttet og ‘autentificeret’ indhold kan NLG-systemer kun håbe at syntetisere menneskelig ulighed og diversitet fra træning på menneskelig data, som i sig selv er et dårligt formuleret og uløst problem. Vi har en indre tendens til at citerer kilder, der støtter vores synspunkter, og til at tale med autoritet og overbevisning i tilfælde, hvor vores kildeinformation kan være forældet, helt urigtig eller på anden måde bevidst misrepræsenteret; og en tilbøjelighed til at diffuse disse synspunkter direkte ud i det vilde, i en skala og effektivitet, der ikke er set før i menneskehistorien, lige ind i stien for de viden-skrapende rammer, der føder nye NLG-rammer.
Derfor synes faren, der er forbundet med udviklingen af citation-understøttede NLG-systemer, at være forbundet med den uforudsigelige natur af kildematerialet. Enhver mekanisme (såsom direkte citation og citater), der øger brugerens tillid til NLG-output, er, i den nuværende tilstand af kunsten, tilføjer farligt til autenticiteten, men ikke sandheden af outputtet.
Sådanne teknikker er sandsynligvis nyttige nok, når NLP endelig genskaber de fiktions-skriveri ‘kalejdoskoper’ fra Orwells Nitten Åttende-Fire; men de repræsenterer en farlig jagt for objektiv dokumentanalyse, AI-centreret journalistik og andre mulige ‘non-fiction’ anvendelser af maskin-sammenfatning og spontan eller guidet tekstgenerering.
Offentliggjort første gang 5. april 2022. Opdateret kl. 15:29 EET til at korrigere term.












