OpenAI har udgivet sin seneste og mest avancerede sprogmodel hidtil – GPT-4o, også kendt som “Omni“-modellen. Dette revolutionerende AI-system repræsenterer et kæmpe skridt fremad, med kapaciteter der udvisker grænsen mellem menneskelig og kunstig intelligens.
I hjertet af GPT-4o ligger dens native multimodale natur, der tillader den at ubesværet behandle og generere indhold på tværs af tekst, lyd, billeder og video. Denne integration af multiple modaliteter i en enkelt model er en første gang, og lover at forandre, hvordan vi interagerer med AI-assistenter.
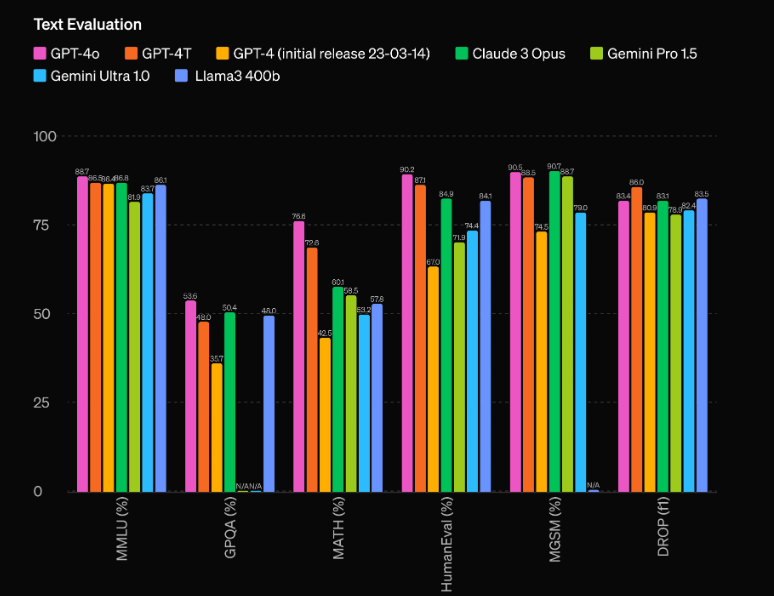
Men GPT-4o er langt mere end bare en multimodal system. Den har en overvældende præstationsforbedring i forhold til sin forgænger, GPT-4, og efterlader konkurrerende modeller som Gemini 1.5 Pro, Claude 3 og Llama 3-70B i støvet. Lad os dykke dybere ind i, hvad der gør denne AI-model virkelig banebrydende.
Ubegrænset Præstation og Effektivitet
En af de mest imponerende aspekter af GPT-4o er dens ubesværet præstationskapaciteter. Ifølge OpenAIs evalueringer har modellen en bemærkelsesværdig 60 Elo-point føring over den tidligere top-performer, GPT-4 Turbo. Denne betydelige fordel placerer GPT-4o i en liga for sig selv, overgående selv de mest avancerede AI-modeller, der i øjeblikket er tilgængelige.
Men raw præstation er ikke det eneste område, hvor GPT-4o skinner. Modellen har også imponerende effektivitet, der opererer med dobbelt så stor hastighed som GPT-4 Turbo, mens den kun koster halvt så meget at køre. Denne kombination af overlegen præstation og omkostningseffektivitet gør GPT-4o til en ekstremt attraktiv mulighed for udviklere og virksomheder, der søger at integrere avancerede AI-kapaciteter i deres applikationer.
Multimodale Kapaciteter: Blænding af Tekst, Lyd og Syn
Måske den mest banebrydende aspekt af GPT-4o er dens native multimodale natur, der tillader den at ubesværet behandle og generere indhold på tværs af multiple modaliteter, herunder tekst, lyd og syn. Denne integration af multiple modaliteter i en enkelt model er en første gang, og lover at revolutionere, hvordan vi interagerer med AI-assistenter.
Med GPT-4o kan brugere engagere i naturlige, real-tids-samtaler ved hjælp af tale, med modellen, der øjeblikkeligt genkender og responderer til lyd-indtastninger. Men kapaciteterne stopper ikke der – GPT-4o kan også fortolke og generere visuelt indhold, åbner op for en verden af muligheder for applikationer, der spænder fra billedanalyse og -generering til video-forståelse og -skabelse.
En af de mest imponerende demonstrationer af GPT-4os multimodale kapaciteter er dens evne til at analysere en scene eller et billede i realtid, nøjagtigt beskrive og fortolke de visuelle elementer, den opfatter. Denne funktion har dybe implikationer for applikationer som assistive teknologier for synshandicappede, såvel som i felter som sikkerhed, overvågning og automatisering.
Men GPT-4os multimodale kapaciteter strækker sig ud over blot at forstå og generere indhold på tværs af forskellige modaliteter. Modellen kan også ubesværet blande disse modaliteter, skabe rigtigt immersive og engagerende oplevelser. For eksempel kunne GPT-4o under OpenAIs live-demo generere en sang baseret på input-forhold, blande sin forståelse af sprog, musikteori og lyd-generering i en kohærent og imponerende output.
Brug af GPT0 med Python
import openai
<p># Erstat med din faktiske API-nøgle
OPENAI_API_KEY = "din_openai_api_nøgle_her"</p>
<p># Funktion til at hente respons-indhold
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []</p>
<p> if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content</p>
<p> raise ValueError(f"Unable to resolve response: {response_dict}")</p>
<p># Asynkron funktion til at sende en anmodning til OpenAIs chat-API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY</p>
<p> message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)</p>
<p> return get_response_content(response)</p>
<p># Eksempel på brug
async def main():
prompt = "Hej!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)</p>
<p>if __name__ == "__main__":
import asyncio
asyncio.run(main())</p>
Jeg har:
Importeret openai-modulen direkte i stedet for at bruge en brugerdefineret klasse.
Omdøbt openai_chat_resolve-funktionen til get_response_content og lavet nogle mindre ændringer i dens implementering.
Erstattet AsyncOpenAI-klassen med openai.ChatCompletion.acreate-funktionen, som er den officielle asynkrone metode, der leveres af OpenAIs Python-bibliotek.
Tilføjet et eksempel på en main-funktion, der demonstrerer, hvordan man kan bruge send_openai_chat_request-funktionen.
Vær opmærksom på, at du skal erstatte “din_openai_api_nøgle_her” med din faktiske OpenAI-API-nøgle for at koden skal fungere korrekt.
Emotionel Intelligens og Naturlig Interaktion
En anden banebrydende aspekt af GPT-4o er dens evne til at fortolke og generere emotionelle responser, en kapacitet, der længe har undgået AI-systemer. Under den live-demo viste OpenAIs ingeniører, hvordan GPT-4o kunne nøjagtigt registrere og respondere til den emotionelle tilstand af brugeren, justere sin tone og responser derefter.
I et særligt slående eksempel lod en ingeniør, som om han hyperventilerede, og GPT-4o genkendte øjeblikkeligt tegnene på distress i hans stemme og åndedrætsmønster. Modellen guidede derefter ingeniøren gennem en række åndedrætsøvelser, modulerede sin tone til en beroligende og trøstende måde, indtil den simulerede distress var aftaget.
Denne evne til at fortolke og respondere til emotionelle signaler er et betydeligt skridt mod rigtigt naturlige og menneskelignende interaktioner med AI-systemer. Ved at forstå den emotionelle kontekst af en samtale kan GPT-4o tilpasse sine responser på en måde, der føles mere naturlig og empatisk, og føre til en mere engagerende og tilfredsstillende brugeroplevelse.
Tilgængelighed
OpenAI har valgt at tilbyde GPT-4os kapaciteter til alle brugere, uden omkostninger. Denne prismodel sætter en ny standard, hvor konkurrenter typisk opkræver betydelige abonnementsgebyrer for adgang til deres modeller.
Selvom OpenAI stadig vil tilbyde en betalt “ChatGPT Plus”-tier med fordele som højere brugsgrænser og prioriteret adgang, vil de grundlæggende kapaciteter af GPT-4o være tilgængelige for alle uden omkostninger.
Virkelige Anvendelser og Fremtidige Udviklinger
Implikationerne af GPT-4os kapaciteter er enorme og langtrækkende, med mulige anvendelser, der spænder over mange industrier og domæner. I området for kundeservice og support kunne GPT-4o for eksempel revolutionere, hvordan virksomheder interagerer med deres kunder, ved at tilbyde naturlig, real-tids-hjælp på tværs af multiple modaliteter, herunder tale, tekst og visuelle hjælpemidler.
I uddannelsesfeltet kunne GPT-4o anvendes til at skabe immersive og personlige læringsoplevelser, hvor modellen tilpasser sin undervisningsstil og indhold til hver enkelt elevs behov og præferencer. Forestil dig en virtuel tutor, der ikke kun kan forklare komplekse begreber gennem naturligt sprog, men også generere visuelle hjælpemidler og interaktive simulationer på stedet.
Underholdningsindustrien er et andet område, hvor GPT-4os multimodale kapaciteter kunne skille sig ud. Fra generering af dynamiske og engagerende narrativer til film og videospil til komposition af original musik og soundtracks, er mulighederne uendelige.
I fremtiden har OpenAI ambitiøse planer om at fortsætte med at udvide kapaciteterne af sine modeller, med fokus på at forbedre resonans-evner og yderligere integrere personlige data. En af de mest spændende muligheder er integrationen af GPT-4o med store sprogmodeller, der er trænet på bestemte domæner, som f.eks. medicinske eller juridiske videnbasers. Dette kunne åbne vejen for højt specialiserede AI-assistenter, der kan tilbyde ekspert-niveau-råd og support i deres respektive felter.
En anden spændende vej for fremtidig udvikling er integrationen af GPT-4o med andre AI-modeller og systemer, der muliggør samarbejde og viden-delning på tværs af forskellige domæner og modaliteter. Forestil dig en situation, hvor GPT-4o kunne udnytte kapaciteterne af avancerede computer-vision-modeller til at analysere og fortolke komplekse visuelle data eller samarbejde med robot-systemer til at give real-tids-vejledning og support i fysiske opgaver.
Etiske Overvejelser og Ansvarlig AI
Som med alle kraftfulde teknologier rejser udviklingen og implementeringen af GPT-4o og lignende AI-modeller vigtige etiske overvejelser. OpenAI har været åben om sin tilgang til ansvarlig AI-udvikling, implementerende forskellige sikkerhedsforanstaltninger og forholdsregler for at minimere potentielle risici og misbrug.
En af de vigtigste bekymringer er den potentielle mulighed for, at AI-modeller som GPT-4o kan fastholde eller forstærke eksisterende fordomme og skadelige stereotyper, der er til stede i træningsdataene. For at imødegå dette har OpenAI implementeret strenge debiasing-teknikker og filtre for at minimere spredningen af sådanne fordomme i modellens output.
En anden kritisk sag er den potentielle misbrug af GPT-4os kapaciteter til skadelige formål, som f.eks. generering af deepfakes, spredning af misinformation eller engagement i andre former for digital manipulation. OpenAI har implementeret robuste indholdsfiltre og moderations-systemer for at opdage og forhindre misbrug af sine modeller til skadelige eller ulovlige aktiviteter.
Desuden har virksomheden understreget vigtigheden af åbenhed og ansvarlighed i AI-udvikling, offentliggørende regelmæssigt forskningspapirer og tekniske detaljer om sine modeller og metoder. Dette engagement i åbenhed og gennemsigtighed er afgørende for at opbygge tillid og sikre ansvarlig udvikling og implementering af AI-teknologier som GPT-4o.
Konklusion
OpenAIs GPT-4o repræsenterer et sandt paradigmeskift i feltet for kunstig intelligens, indledende en ny æra af multimodal, emotionel intelligent og naturlig menneske-maskine-interaktion. Med sin ubegrænsede præstation, ubesværet integration af tekst, lyd og syn, og sin revolutionerende prismodel lover GPT-4o at demokratisere adgangen til avancerede AI-kapaciteter og forandre, hvordan vi interagerer med teknologi på en grundlæggende niveau.
Selvom implikationerne og de potentielle anvendelser af denne banebrydende model er enorme og spændende, er det afgørende, at dens udvikling og implementering er guidet af en fast tilgang til etiske principper og ansvarlig AI-praksis.
Jeg har brugt de sidste fem år på at dykke ned i den fascinerende verden af Machine Learning og Deep Learning. Min passion og ekspertise har ført mig til at bidrage til over 50 forskellige software-ingeniørprojekter, med en særlig fokus på AI/ML. Min fortsatte nysgerrighed har også ført mig mod Natural Language Processing, et felt jeg er ivrig efter at udforske yderligere.