Evnen til at generere 3D-digitale aktiver fra tekstprompts repræsenterer en af de mest spændende nyere udviklinger i AI og computergrafik. Da markedet for 3D-digitale aktiver forventes at vokse fra 28,3 milliarder dollars i 2024 til 51,8 milliarder dollars i 2029, er tekst-til-3D AI-modeller godt positioneret til at spille en stor rolle i at revolutionere indholdsskabelse på tværs af brancher som gaming, film, e-handel og mere. Men hvordan fungerer disse AI-systemer nøjagtig? I denne artikel dykker vi dybt ned i de tekniske detaljer bag tekst-til-3D-generering.
Udfordringen ved 3D-generering
At generere 3D-aktiver fra tekst er en langt mere kompleks opgave end 2D-billedegenerering. Mens 2D-billeder i virkeligheden er gitter af pixel, kræver 3D-aktiver repræsentation af geometri, teksturer, materialer og ofte animationer i tre dimensioner. Denne tilføjede dimension og kompleksitet gør genereringsopgaven meget mere udfordrende.
Nogle nøgleudfordringer i tekst-til-3D-generering omfatter:
Repræsentation af 3D-geometri og struktur
Generering af konsistente teksturer og materialer på tværs af 3D-overfladen
Sikring af fysisk plausibilitet og kohærens fra multiple synsvinkler
Fanget af fine detaljer og global struktur samtidig
Generering af aktiver, der kan let renderes eller 3D-printes
For at tackle disse udfordringer udnytter tekst-til-3D-modeller flere nøgleteknologier og -teknikker.
Nøglekomponenter i tekst-til-3D-systemer
De fleste state-of-the-art tekst-til-3D-genereringssystemer deler nogle fælles komponenter:
Tekstkode: Konvertering af inputtekstprompt til en numerisk repræsentation
3D-repræsentation: En metode til at repræsentere 3D-geometri og udseende
Generativ model: Den centrale AI-model til at generere 3D-aktiver
Rendering: Konvertering af 3D-repræsentation til 2D-billeder til visualisering
Lad os udforske hver af disse i mere detalje.
Tekstkode
Det første trin er at konvertere inputtekstpromptet til en numerisk repræsentation, som AI-modellen kan arbejde med. Dette gøres typisk ved hjælp af store sprogmodeller som BERT eller GPT.
3D-repræsentation
Der er flere almindelige måder at repræsentere 3D-geometri i AI-modeller:
Voxelgitter: 3D-arrays af værdier, der repræsenterer besættelse eller funktioner
Punktskyer: Sæt af 3D-punkter
Net: Vertices og flader, der definerer en overflade
Implicitte funktioner: Kontinuerte funktioner, der definerer en overflade (f.eks. signerede afstandsfunktioner)
Neurale lysfelter (NeRF): Neurale netværk, der repræsenterer tæthed og farve i 3D-rum
Hver har kompromiser i forhold til opløsning, hukommelsesbrug og letgenhed ved generering. Mange nyere modeller bruger implicitte funktioner eller NeRF, da de giver højkvalitetsresultater med rimelige beregningskrav.
For eksempel kan vi repræsentere en simpel kugle som en signerede afstandsfunktion:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluér SDF ved et 3D-punkt
punkt = [0.5, 0.5, 0.5]
afstand = sphere_sdf(*punkt)
print(f"Afstand til kugleoverfladen: {afstand}")
Generativ model
Kernen i et tekst-til-3D-system er den generative model, der producerer 3D-aktiver fra tekstembedding. De fleste state-of-the-art-modeller bruger en variation af en diffusionsmodel, lignende dem, der bruges i 2D-billedegenerering.
Diffusionsmodeller fungerer ved at tilføje støj til data og derefter lære at omvende denne proces. For 3D-generering sker denne proces i rummet af den valgte 3D-repræsentation.
En forenklet pseudokode for en diffusionsmodeltræningsstep kunne se således ud:
Under generering starter vi fra ren støj og itererer derefter støjen, betinget af tekstembedding.
Rendering
For at visualisere resultater og beregne tab under træning har vi brug for at renderere vores 3D-repræsentation til 2D-billeder. Dette gøres typisk ved hjælp af differentiable rendering-teknikker, der tillader, at gradienter kan flyde tilbage gennem renderingprocessen.
For mesh-baserede repræsentationer kunne vi bruge en rasterizationsbaseret renderer:
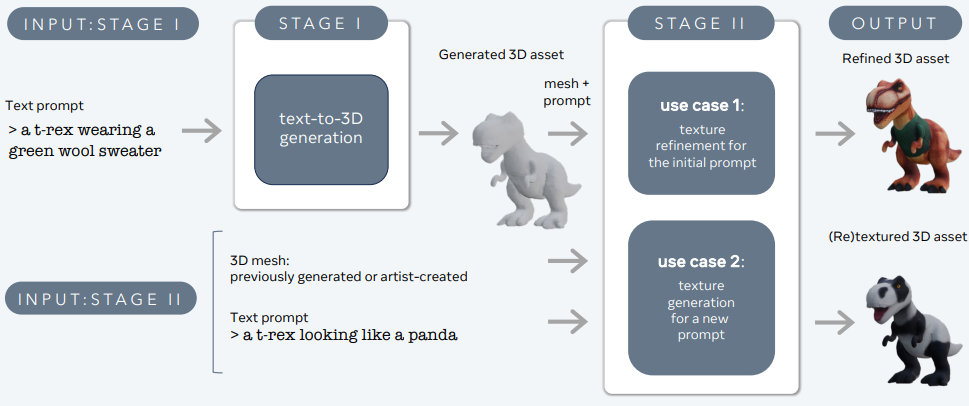
3DGen understøtter fysisk-baseret rendering (PBR), der er essentiel for realistisk 3D-aktiver-genoplysning i virkelige applikationer. Det aktiverer også generativ omteksturering af tidligere genererede eller kunstnerisk skabte 3D-former ved hjælp af nye tekstinput. Pipeline-integrationen består af to kernekomponenter: Meta 3D AssetGen og Meta 3D TextureGen, der håndterer tekst-til-3D og tekst-til-tekstur-generering, henholdsvis.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) er ansvarlig for den initielle generering af 3D-aktiver fra tekstprompts. Denne komponent producerer en 3D-mesh med teksturer og PBR-materialekort i cirka 30 sekunder.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) forbedrer teksturerne genereret af AssetGen. Den kan også bruges til at generere nye teksturer til eksisterende 3D-mesh’er baseret på yderligere tekstbeskrivelser. Dette trin tager cirka 20 sekunder.
Point-E (OpenAI)
Point-E, udviklet af OpenAI, er endnu en bemærkelsesværdig tekst-til-3D-genereringsmodel. I modsætning til DreamFusion, der producerer NeRF-repræsentationer, genererer Point-E 3D-punktskyer.
Nøglefunktioner i Point-E:
a) To-trins-pipeline: Point-E genererer først en syntetisk 2D-visning ved hjælp af en tekst-til-billede-diffusionsmodel, derefter bruger denne billed til at betinge en anden diffusionsmodel, der producerer 3D-punktskyen.
b) Effektivitet: Point-E er designet til at være beregningsmæssigt effektiv, i stand til at generere 3D-punktskyer på få sekunder på en enkelt GPU.
c) Farveinformation: Modellen kan generere farvede punktskyer, der bevare både geometrisk og udseendemæssig information.
Begrænsninger:
Lavere fidelitet i forhold til mesh-baserede eller NeRF-baserede tilgange
Punktskyer kræver yderligere behandling til mange efterfølgende applikationer
Shap-E (OpenAI):
Bygget på Point-E introducerede OpenAI Shap-E, der genererer 3D-mesh’er i stedet for punktskyer. Dette adresserer nogle af begrænsningerne i Point-E, mens det fastholder beregningsmæssig effektivitet.
Nøglefunktioner i Shap-E:
a) Implicit repræsentation: Shap-E lærer at generere implicitte repræsentationer (signerede afstandsfunktioner) af 3D-objekter.
b) Mesh-ekstraktion: Modellen bruger en differentiable implementering af marching cubes-algoritmen til at konvertere den implicitte repræsentation til en polygonal mesh.
c) Teksturgenerering: Shap-E kan også generere teksturer til 3D-mesh’er, resulterende i mere visuelt tillokkende output.
Fordele:
Hurtige genereringstider (sekunder til minutter)
Direkte mesh-output egnet til rendering og efterfølgende applikationer
Evne til at generere både geometri og tekstur
GET3D (NVIDIA):
GET3D, udviklet af NVIDIA-forskere, er endnu en kraftfuld tekst-til-3D-genereringsmodel, der fokuserer på at producere højkvalitets-teksturerede 3D-mesh’er.
Nøglefunktioner i GET3D:
a) Eksplicit overfladerepræsentation: I modsætning til DreamFusion eller Shap-E genererer GET3D direkte eksplicitte overfladerepræsentationer (mesh’er) uden intermediate implicitte repræsentationer.
b) Teksturgenerering: Modellen inkluderer en differentiable rendering-teknik til at lære og generere højkvalitets-teksturer til 3D-mesh’er.
c) GAN-baseret arkitektur: GET3D bruger en generative adversarial network (GAN)-tilgang, der tillader hurtig generering, når modellen er trænet.
Fordele:
Højkvalitetsgeometri og teksturer
Hurtige inferenstider
Direkte integration med 3D-renderingsmotorer
Begrænsninger:
Kræver 3D-træningsdata, der kan være knappe for nogle objekt kategorier
Konklusion
Tekst-til-3D AI-generering repræsenterer en grundlæggende ændring i, hvordan vi skaber og interagerer med 3D-indhold. Ved at udnytte avancerede dybe læringsteknikker kan disse modeller producere komplekse, højkvalitets 3D-aktiver fra simple tekstbeskrivelser. Da teknologien fortsætter med at udvikle sig, kan vi forvente at se stadig mere avancerede og kapable tekst-til-3D-systemer, der vil revolutionere brancher fra gaming og film til produkt design og arkitektur.
Jeg har brugt de sidste fem år på at dykke ned i den fascinerende verden af Machine Learning og Deep Learning. Min passion og ekspertise har ført til, at jeg har bidraget til over 50 forskellige software-udviklingsprojekter, med særlig fokus på AI/ML. Min vedvarende nysgerrighed har også ført mig i retning af Natural Language Processing, et felt jeg er ivrig efter at udforske yderligere.