Kunstig intelligens
Hvordan Stable Diffusion Kan Udvikle Sig Til En Mainstream Forbrugerprodukt

Ironisk nok, Stable Diffusion, det nye AI-billeddannelsesrammeværk, der har taget verden med storm, er hverken stabil eller rigtig “diffunderet” – i hvert fald ikke endnu.
Den fulde række af systemets funktioner er spredt over en varieret samling af konstant muterende tilbud fra en håndfuld udviklere, der febrilsk udveksler den seneste information og teorier i diverse diskussioner på Discord – og det overvældende flertal af installationsprocedurene for de pakker, de opretter eller ændrer, er meget langt fra “plug and play”.
I stedet kræver de ofte kommandolinje eller BAT-drevet installation via GIT, Conda, Python, Miniconda og andre skarpt udviklingsrammer – softwarepakker, der er så sjældne blandt den generelle forbruger, at deres installation ofte bliver markeret som bevis på et kompromitteret hostsystem af antivirus- og anti-malware-udbydere.

Kun et lille udvalg af stadier i den gauntlet, som den standardmæssige Stable Diffusion-installation i øjeblikket kræver. Mange af distributionerne kræver også specifikke versioner af Python, som kan være i konflikt med eksisterende versioner, der er installeret på brugerens maskine – selvom dette kan undgås med Docker-baserede installationer og i visse tilfælde gennem brug af Conda-miljøer.
Beskeder i både SFW- og NSFW-Stable Diffusion-samfund er oversvømmet med tip og tricks relateret til hacking af Python-skripter og standardinstallationer for at aktivere forbedret funktionalitet eller for at løse hyppige afhængighedsfejl og en række andre problemer.
Dette efterlader den gennemsnitlige forbruger, der er interesseret i at oprette fantastiske billeder fra tekstprompt, næsten helt på mercy af det voksende antal kommercielle API-webgrænseflader, hvoraf de fleste tilbyder en minimal mængde af gratis billedgenerationer, før de kræver køb af tokens.
Derudover nægter næsten alle disse webbaserede tilbud at producere NSFW-indhold (som kan omfatte ikke-pornografiske emner af generel interesse, såsom “krig”), hvilket adskiller Stable Diffusion fra OpenAI’s DALL-E 2’s censurerede tjenester.
‘Photoshop for Stable Diffusion’
Det, som den brede verden åbenbart venter på, er ‘Photoshop for Stable Diffusion’ – en tværgående installerbart program, der omfatter det bedste og mest kraftfulde funktionalitet i Stability.ai’s arkitektur samt de forskellige geniale innovationer fra den opkommende SD-udviklersamfund, uden nogen flydende CLI-vinduer, uklare og konstant skiftende installations- og opdateringsroutiner eller manglende funktioner.
Det, vi i øjeblikket har, i de fleste mere kapable installationer, er en forskelligt elegant web-side omgivet af et løsrevet kommandolinjevindue, og hvis URL er en localhost-port:

Lignende med CLI-drevne synteseapps som FaceSwap og BAT-centriske DeepFaceLab, viser ‘prepack’-installationen af Stable Diffusion sine kommandolinjerødder, med grænsefladen tilgængelig via en localhost-port (se toppen af billedet ovenfor), som kommunikerer med den CLI-baserede Stable Diffusion-funktionalitet.
Uden tvivl er der på vej en mere strømlinet anvendelse. Allerede er der flere Patreon-baserede integrale programmer, der kan downloades, såsom GRisk og NMKD (se billedet nedenfor) – men ingen, der endnu integrerer det fulde udvalg af funktioner, som nogle af de mere avancerede og mindre tilgængelige implementationer af Stable Diffusion kan tilbyde.

Tidlige, Patreon-baserede pakker af Stable Diffusion, let ‘app-izeret’. NMKD’s er den første til at integrere CLI-udgangen direkte i GUI’en.
Lad os kaste et blik på, hvordan en mere poleret og integral implementering af denne forbløffende open source-vidunder kan se ud – og hvilke udfordringer den kan møde.
Retlige Overvejelser for en Fuldt Finansieret Kommerciel Stable Diffusion-Anvendelse
NSFW-Faktoren
Stable Diffusion-kilden er udgivet under en ekstremt tilladende licens, der ikke forhindrer kommercielle genimplementeringer og afledte værker, der bygger omfattende på kilden.
Ud over de ovennævnte og voksende antal Patreon-baserede Stable Diffusion-bygninger samt det omfattende antal applikationsplugins, der udvikles til Figma, Krita, Photoshop, GIMP og Blender (iblandt andre), er der ingen praktisk grund til, at en vel-finansieret softwareudviklingsvirksomhed ikke kan udvikle en langt mere sofistikeret og kraftfuld Stable Diffusion-anvendelse. Fra et markedsperspektiv er der alle grund til at tro, at flere sådanne initiativer allerede er godt i gang.
Her står sådanne bestræbelser straks over for dilemmaet om, hvorvidt anvendelsen, ligesom de fleste web-API’er for Stable Diffusion, vil tillade Stable Diffusions indbyggede NSFW-filter (en fragment af kode), at blive slået fra.
‘Begravelse’ af NSFW-Skiftet
Selvom Stability.ai’s open source-licens for Stable Diffusion indeholder en bredt fortolkelig liste over anvendelser, som den ikke må bruges til (muligvis herunder pornografisk indhold og deepfakes), er den eneste måde, en udbyder kunne effektivt forhindre en sådan brug, at kompilere NSFW-filtret til en uigennemsigtig eksekverbar fil i stedet for en parameter i en Python-fil, eller på anden vis påtvinge en checksum-sammenligning på Python-filen eller DLL-filen, der indeholder NSFW-direktivet, således at rendering ikke kan ske, hvis brugerne ændrer denne indstilling.
Dette ville efterlade den påståede anvendelse “kastreret” på samme måde, som DALL-E 2 i øjeblikket er, og mindske dens kommercielle appel. Desuden ville uundgåeligt dekompilerede “doktorerede” versioner af disse komponenter (enten originale Python-runtime-elementer eller kompilerede DLL-filer, som nu bruges i Topaz-linjen af AI-billedeforbedringsværktøjer) sandsynligvis dukke op i torrent/hacking-samfundet for at omgå sådanne begrænsninger, blot ved at erstatte de hindrende elementer og negere enhver checksum-krav.
Til sidst kan udbyderen blot gentage Stability.ai’s advarsel mod misbrug, som kendetegner den første kørsel af mange nuværende Stable Diffusion-distributioner.
Men de små open source-udviklere, der i øjeblikket bruger sådanne uformelle disclaimere, har lidt at tabe i sammenligning med et softwarefirma, der har investeret betydelige mængder tid og penge i at gøre Stable Diffusion fuldt udbygget og tilgængeligt – hvilket inviterer til dybere overvejelser.
Deepfake-Ansvar
Som vi nyligt har bemærket, indeholder LAION-aestetikdatabasen, en del af de 4,2 milliarder billeder, som Stable Diffusions fortsatte modeller blev trænet på, et stort antal berømthedsbilleder, hvilket muliggør, at brugerne kan effektivt skabe deepfakes, herunder deepfake-berømtheds-pornografi.

Fra vores seneste artikel, fire stadier af Jennifer Connelly over fire årtier af hendes karriere, sluttede fra Stable Diffusion.
Dette er et separat og mere kontroversielt spørgsmål end genereringen af (som regel) lovligt “abstrakt” pornografi, der ikke afbilder “reelle” personer (selvom sådanne billeder er sluttede fra multiple virkelige billeder i træningsmaterialet).
Da et stigende antal amerikanske stater og lande udvikler eller har indført love mod deepfake-pornografi, kunne Stable Diffusions evne til at skabe berømtheds-pornografi betyde, at en kommerciel anvendelse, der ikke er helt censureret (dvs. der kan skabe pornografisk materiale), måske stadig skal have nogen form for filter til at genkende antaget berømthedsansigter.
En metode kunne være at tilbyde en indbygget “sortliste” over termer, der ikke vil blive accepteret i en brugerprompt, relateret til berømthedsnavne og til fiktive karakterer, de måske er forbundet med. Sandsynligvis skulle sådanne indstillinger også være nødvendige i flere sprog end kun engelsk, da det oprindelige data omfatter andre sprog. En anden tilgang kunne være at integrere berømtheds-genkendelsessystemer som dem, der er udviklet af Clarifai.
Det kan være nødvendigt for softwareproducenter at integrere sådanne metoder, måske først slået fra, som kan hjælpe med at forhindre en fuldt udbygget selvstændig Stable Diffusion-anvendelse i at skabe berømthedsansigter, indtil nye love, der kunne gøre en sådan funktionalitet ulovlig, er trådt i kraft.
En gang til, dog, kunne en sådan funktionalitet uundgåeligt blive dekompileret og omvendt af interesserede parter; dog kunne softwareproducenten, i så fald, hævde, at dette i virkeligheden er unsanktioneret vandalisme – så længe en sådan omvendt ingeniørkunst ikke gøres alt for let.
Funktioner, der Kan Medtages
Den grundlæggende funktionalitet i enhver distribution af Stable Diffusion ville forventes af enhver vel-finansieret kommerciel anvendelse. Disse omfatter muligheden for at bruge tekstprompt til at generere passende billeder (tekst-til-billede); muligheden for at bruge skitser eller andre billeder som retningslinjer for nye genererede billeder (billede-til-billede); midlet til at justere, hvor “fantasifuld” systemet er instrueret til at være; en måde til at afveje render-tid mod kvalitet; og andre “grundlæggende” funktioner, såsom valgfri automatisk billed/prompt-arkivering og rutine-valgfri opskalering via RealESRGAN, og mindst grundlæggende “ansigtscorrection” med GFPGAN eller CodeFormer.
Det er en ret “vanilje-installation”. Lad os kaste et blik på nogle af de mere avancerede funktioner, der i øjeblikket udvikles eller udvides, som kunne integreres i en fuldt udbygget “traditionel” Stable Diffusion-anvendelse.
Stokastisk Frysning
Selv hvis du genbruger en seed fra en tidligere succesfuld render, er det frygteligt svært at få Stable Diffusion til nøjagtigt at gentage en transformation, hvis noget af prompten eller kildebilledet (eller begge) ændres for en efterfølgende render.
Dette er et problem, hvis du ønsker at bruge EbSynth til at påføre Stable Diffusions transformationer på virkeligt video på en tidsmæssigt koherent måde – selvom teknikken kan være meget effektiv til simple hoved-og-skuldre-optagelser:

Begrænset bevægelse kan gøre EbSynth til et effektivt medium til at omdanne Stable Diffusions transformationer til realistisk video. Kilde: https://streamable.com/u0pgzd
EbSynth virker ved at extrapolere en lille udvalg af “ændrede” nøgleframes til en video, der er renderet ud i en række billedfiler (og som senere kan samles tilbage til en video).

I dette eksempel fra EbSynth-sitet er et lille håndfuld frames fra en video blevet malet på en kunstnerisk måde. EbSynth bruger disse frames som stilvejledere til at ændre hele videoen, så den matcher den malede stil. Kilde: https://www.youtube.com/embed/eghGQtQhY38
I eksemplet nedenfor, hvor der næsten ikke er nogen bevægelse overhovedet fra den (virkelige) blonde yogainstruktør til venstre, har Stable Diffusion stadig svært ved at opretholde en konsekvent ansigt, fordi de tre billeder, der transformerer som “nøgleframes”, ikke er helt identiske, selvom de alle deler den samme numeriske seed.

Her, selv med samme prompt og seed over alle tre transformationer, og meget få ændringer mellem kildebillederne, varierer kroppens muskler i størrelse og form, men vigtigere er ansigtet inkonsistent, hvilket hindrer tidsmæssig konsistens i en potentiel EbSynth-render.
Selvom Stable Diffusion/EbSynth-videoen nedenfor er meget opfindsom, hvor brugerens fingre er blevet til en gående mand og en and, er inkonsistensen af bukserne typisk for det problem, Stable Diffusion har med at opretholde konsistens på tværs af forskellige nøgleframes, selv hvor kildebillederne er lignende hinanden og seeden er konsekvent.

En mands fingre bliver til en gående mand og en and, via Stable Diffusion og EbSynth. Kilde: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Brugeren, der skabte denne video kommenterede, at and-transformationen, der sandsynligvis er den mere effektive af de to, kun krævede en enkelt transformeret nøgleframe, hvorimod det var nødvendigt at render 50 Stable Diffusion-billeder for at skabe de gående bukser, der viser mere tidsmæssig inkonsistens. Brugeren bemærkede også, at det krævede fem forsøg at opnå konsistens for hver af de 50 nøgleframes.
Derfor ville det være en stor fordel for en rigtig komprehensiv Stable Diffusion-anvendelse at give mulighed for at “fryse” den stokastiske kodning for transformationen på hver frame, hvilket i øjeblikket kun kan opnås ved at ændre kilden manuelt. Som eksemplet nedenfor viser, hjælper dette med at opretholde tidsmæssig konsistens, selvom det bestemt ikke løser det:

En Reddit-bruger transformerer webcam-optagelser af sig selv til forskellige berømte personer ved ikke kun at fastholde seeden (hvad enhver implementation af Stable Diffusion kan gøre), men også ved at sikre, at den stokastiske_kodning() parameter var identisk i hver transformation. Dette blev opnået ved at ændre koden, men kunne let blive en bruger-tilgængelig skifter. Det er dog tydeligt, at det ikke løser alle tidsmæssige problemer.
Cloud-baseret Tekstuel Inversion
En bedre løsning til at fremkalde tidsmæssigt konsistente karakterer og objekter er at “bage” dem ind i en Tekstuel Inversion – en 5KB-fil, der kan trænes på få timer på basis af kun fem annoterede billeder, som derefter kan fremkaldes af en særlig ‘*’ prompt, og muliggøre, for eksempel, en varig fremtoning af nye karakterer til inklusion i en fortælling.

Billeder forbundet med passende tags kan konverteres til separate enheder via Tekstuel Inversion og fremkaldes uden forvirring og i den rigtige kontekst og stil, ved særlige token-ord. Kilde: https://huggingface.co/docs/diffusers/training/text_inversion
Tekstuelle Inversioner er bifile til den meget store og fuldt trænede model, som Stable Diffusion bruger, og er effektivt “slipstrømmet” ind i den fremkaldende/prompt-proces, så de kan deltage i model-afledte scener, og drage fordel af modellens enorme database af viden om objekter, stilarter, miljøer og interaktioner.
Men selvom en Tekstuel Inversion ikke tager lang tid at træne, kræver den en stor mængde VRAM; ifølge forskellige nuværende vejledninger kræver det mellem 12, 20 og selv 40GB.
Da de fleste almindelige brugere sandsynligvis ikke har så megen GPU-kraft til rådighed, er cloud-tjenester allerede under udvikling, der kan håndtere operationen, herunder en Hugging Face-version. Selvom der er Google Colab-implementationer, der kan oprette tekstuelle inversioner for Stable Diffusion, kan de påkrævede VRAM- og tidskrav gøre det til en udfordring for free-tier Colab-brugere.
For en potentiel fuldt udbygget og vel-investeret Stable Diffusion-anvendelse (installeret) ville det være en åbenlys moneteringsstrategi (under antagelse af, at en lav eller ikke-kostbar Stable Diffusion-anvendelse er gennemtrængt af sådan ikke-kostbar funktionalitet, hvilket synes sandsynligt i mange mulige anvendelser, der vil opstå fra denne teknologi i de næste 6-9 måneder).
Derudover kunne den ret komplicerede proces med at annotere og formaterer de indsendte billeder og tekst have gavn af automatisering i en integreret miljø. Den potentielle “afhængighedsfaktor” af at skabe unikke elementer, der kan udforske og interagere med de enorme verdener af Stable Diffusion, ville synes potentielt vanvittig, både for almindelige entusiaster og unge brugere.
Flersidig Prompt-Vægning
Der er mange nuværende implementationer, der tillader brugeren at tildele større vægt til en del af en lang tekstprompt, men instrumenteringen varierer ret meget mellem disse, og er ofte klodset eller ikke-intuitivt.
Den meget populære Stable Diffusion-gren af AUTOMATIC1111 kan f.eks. sænke eller hæve værdien af en prompt-ord ved at indramme det i enkelt eller multiple parenteser (for at mindske vægten) eller kvadratparenteser for ekstra vægt.

Kvadratparenteser og/eller parenteser kan forvandle din morgenmad i denne version af Stable Diffusion-prompt-vægt, men det er en kolesterol-mareridt på begge måder.
Andre iterationer af Stable Diffusion bruger udråbstegn til vægtning, mens de mest fleksible tillader brugere at tildele vægt til hvert ord i prompten via GUI’en.
Systemet skulle også tillade negative prompt-vægt – ikke kun for horror-fans, men fordi der måske er færre alarmende og mere opbyggelige mysterier i Stable Diffusions latente rum end vores begrænsede brug af sprog kan fremkalde.
Udmaalning
Kort efter den sensationelle open-sourcing af Stable Diffusion forsøgte OpenAI – stort set forgæves – at genskabe noget af sin DALL-E 2-thunder ved at annoncere ‘udmaalning’, der tillader en bruger at udvide et billede ud over dets grænser med semantisk logik og visuel kohærens.
Naturligvis er dette siden blevet implementeret i forskellige former for Stable Diffusion, samt i Krita, og burde bestemt være inkluderet i en komprehensiv, Photoshop-lignende version af Stable Diffusion.
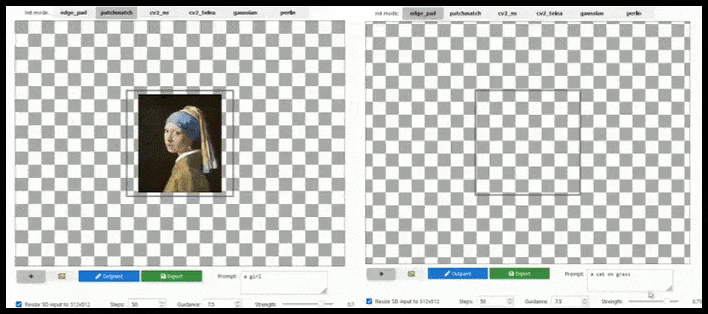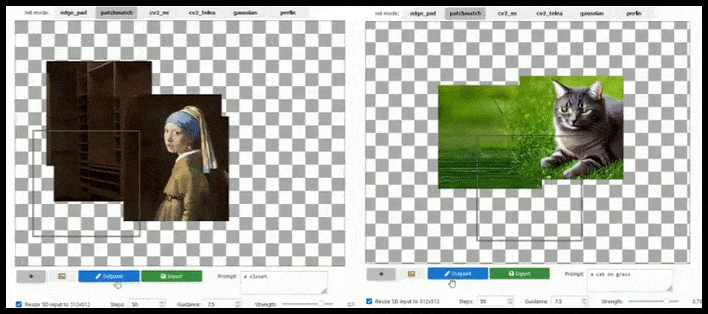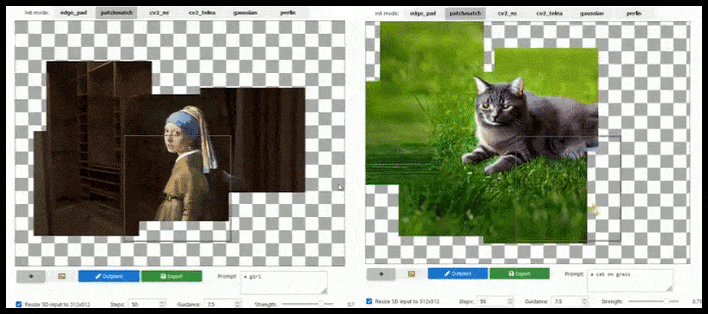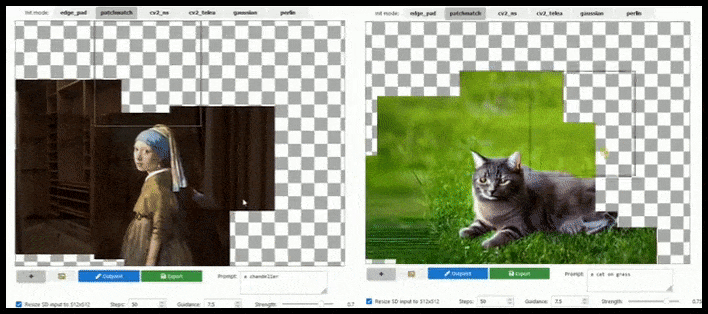
Flis-baseret udvidelse kan udvide et standard 512×512-render næsten uendeligt, så længe prompten, det eksisterende billede og den semantiske logik tillader det. Kilde: https://github.com/lkwq007/stablediffusion-infinity
Fordi Stable Diffusion er trænet på 512x512px-billeder (og af en række andre årsager), skærer det ofte hoveder (eller andre essentielle kropsdele) af menneskelige subjekter, selv hvor prompten tydeligt angav “hoved-til-fokus”, osv..

Typiske eksempler på Stable Diffusions “afhugning”; men udmaalning kunne sætte George tilbage i billedet.
Enhver udmaalningsimplementering af den type, der er illustreret i den animerede billedsekvens ovenfor (der udelukkende er baseret på Unix-biblioteker, men burde være i stand til at blive replikeret på Windows), burde også være udstyret som en enklik/prompt-løsning for dette problem.
I øjeblikket udvider en række brugere canvas af “afhugede” fremstillinger opad, udfylder omtrent ansigtets område og bruger img2img til at fuldføre den fejlbehæftede render.
Effektiv Maskering, der Forstår Kontekst
Maskering kan være en frygteligt ram-skydning i Stable Diffusion, afhængigt af grenen eller versionen i spørgsmålet. Ofte, hvor det er muligt at tegne en samlet mask på alle måder, ender den angivne område med at blive påmalet med indhold, der ikke tager hele billedets kontekst i betragtning.
På en lejlighed maskerede jeg korneerne af et ansigt og angav prompten ‘blå øjne’ som mask-indpaining – kun for at opdage, at jeg så ud til at se gennem to udskårne menneskeøjne på et fjernt billede af et overnaturligt udseende ulv. Jeg gætter, jeg er heldig, det ikke var Frank Sinatra.
Semantisk redigering er også mulig ved at identificere støjen, der opbyggede billedet fra starten, hvilket tillader brugeren at adresse specifikke strukturelle elementer i en render uden at forstyrre resten af billedet:

Ændring af et element i et billede uden traditionel maskering og uden at ændre tilstødende indhold, ved at identificere støjen, der oprindeligt skabte billedet, og adresse de dele af den, der bidrog til målområdet. Kilde: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Denne metode er baseret på K-Diffusion-samleren.
Semantiske Filter til Fysiologiske Fejl
Som vi tidligere har nævnt, kan Stable Diffusion ofte tilføje eller fjerne lemmer, primært på grund af data-problemer og mangler i annoteringerne, der ledsager billederne, der trænede det.

Lige som den uartige dreng, der stak sin tunge ud i skolefotoet, er Stable Diffusions biologiske grusomheder ikke altid øjeblikkeligt åbenlyse, og du kan have deltet dit seneste AI-mesterværk på Instagram, før du opdager de ekstra hænder eller opløste lemmer.
Det er så svært at rette disse fejl, at det ville være nyttigt, hvis en fuldt udbygget Stable Diffusion-anvendelse indeholdt et eller andet anatomisk genkendelsessystem, der anvender semantisk segmentering til at beregne, om det indkommende billede har alvorlige anatomiske mangler (som i billedet ovenfor), og forkaster det til fordel for en ny render, før det præsenteres for brugeren.

Selvfølgelig kan du måske ønske at render den gudinde Kali, eller Doktor Octopus, eller endda redde en upåvirket del af et lem-hæmmet billede, så denne funktion burde være en valgfri skifter.
Hvis brugere kunne acceptere aspektet af telemetri, kunne sådanne fejl også blive transmitteret anonymt i en fælles indsats for at hjælpe fremtidige modeller med at forbedre deres forståelse af anatomisk logik.
LAION-baseret Automatisk Ansigtforbedring
Som jeg bemærkede i min tidligere kig på tre ting, Stable Diffusion kunne adressere i fremtiden, burde det ikke blot overlades til en eller anden version af GFPGAN at forsøge at “forbedre” renderede ansigter i første instans.
GFPGAN’s “forbedringer” er frygteligt generiske, ofte undergraver identiteten af den afbildede person, og fungerer udelukkende på et ansigt, der ikke har modtaget mere processortid eller opmærksomhed end noget andet del af billedet.
Derfor burde et professionelt standardprogram for Stable Diffusion være i stand til at genkende et ansigt (med en standard og relativt letvægtsbibliotek som YOLO), anvende den fulde vægt af tilgængelig GPU-kraft til gen-rendering af det, og enten blande det forbedrede ansigt ind i den originale fuld-kontekst-render eller gemme det separat til manuel gen-sammensætning. I øjeblikket er dette en ret “hånd-til”-operation.
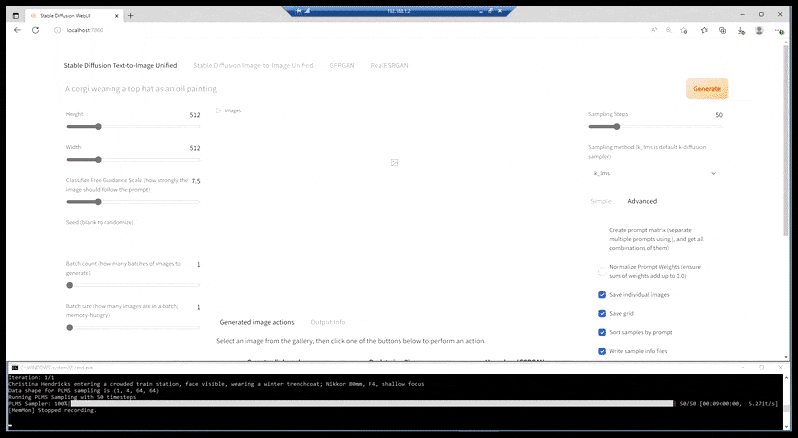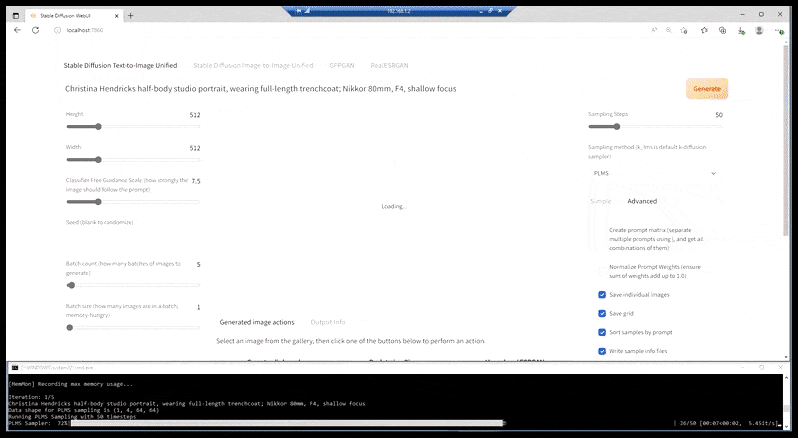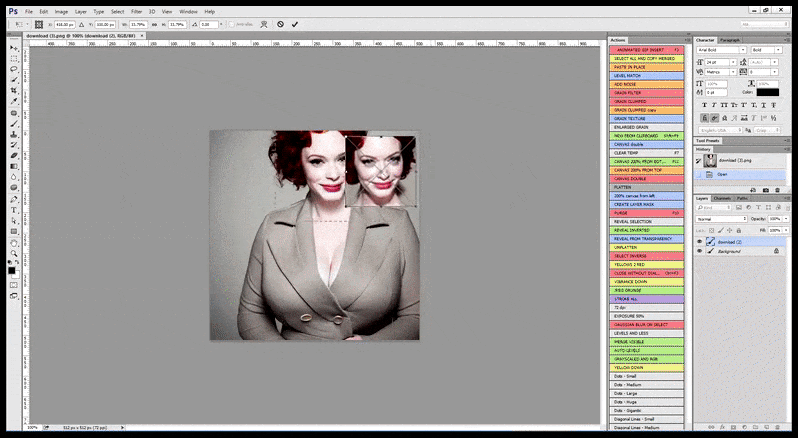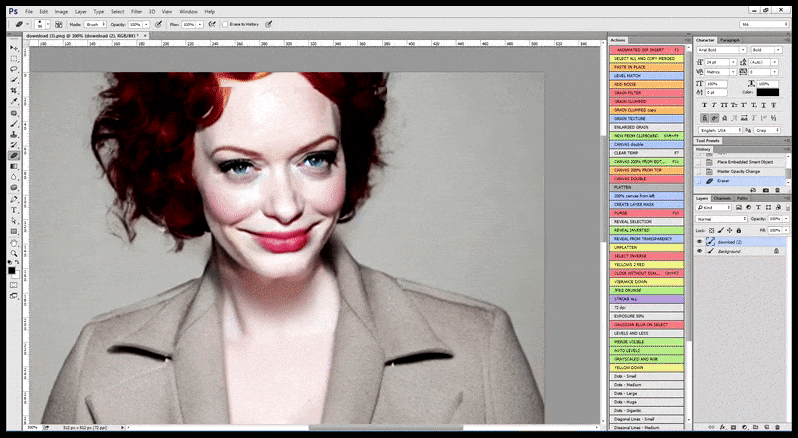
I tilfælde, hvor Stable Diffusion er trænet på et tilstrækkeligt antal billeder af en berømthed, er det muligt at fokusere hele GPU-kapaciteten på en efterfølgende render udelukkende af ansigtet på det renderede billede, hvilket som regel er en bemærkelsesværdig forbedring – og, i modsætning til GFPGAN, trækker på information fra LAION-trænet data, snarere end blot at justere de renderede pixel.
Ind-App LAION-Søgninger
Siden brugere begyndte at indse, at søgning i LAION’s database efter begreber, personer og temaer kunne være en hjælp til bedre brug af Stable Diffusion, er der blevet oprettet flere online LAION-udforskere, herunder haveibeentrained.com.

Søgefunktionen på haveibeentrained.com låter brugere udforske de billeder, der driver Stable Diffusion, og opdage, om objekter, personer eller ideer, de måske ønsker at fremkalde fra systemet, sandsynligvis er blevet trænet ind i det. Sådanne systemer er også nyttige til at opdage tilstødende enheder, såsom måden, berømtheder er grupperet, eller “næste idé”, der følger fra den nuværende.
Selvom sådanne web-baserede databaser ofte afslører nogle af de tags, der ledsager billederne, indebærer processen med generalisering, der finder sted under modeltræning, at det er usandsynligt, at et bestemt billede kunne fremkaldes ved at bruge dets tag som prompt.
Derudover indebærer fjernelse af ‘stop-ord’ og praksis med stemming og lemmatisering i naturlig sprogbehandling, at mange af de fraser, der vises, blev delt eller udeladt, før de blev trænet ind i Stable Diffusion.
Alligevel kan måden, hvorpå æstetiske grupperinger binder sammen i disse grænseflader, lære slutbrugeren meget om logikken (eller måske “personligheden”) af Stable Diffusion og være en hjælp til bedre billedproduktion.
Konklusion
Der er mange andre funktioner, jeg gerne ville se i en fuldt udbygget nativ desktop-implementering af Stable Diffusion, såsom nativ CLIP-baseret billedanalyse, der omvender den standardmæssige Stable Diffusion-proces og tillader brugeren at fremkalde fraser og ord, som systemet naturligt ville associerer med kildebilledet eller renderen.
Derudover ville sand flis-baseret skaleringsmulighed være en velkommen tilføjelse, da ESRGAN er næsten lige så klodset et instrument som GFPGAN. Takket være planer om at integrere txt2imghd-implementationen af GOBIG er dette allerede under hurtig udvikling på tværs af distributionerne, og det synes en åbenlys valgmulighed for en desktop-iteration.
Nogle andre populære anmodninger fra Discord-samfundene interesserer mig mindre, såsom integrerede prompt-ordbøger og anvendelige lister over kunstnere og stilarter, selvom en indbygget notesbog eller en tilpasselig leksikon af fraser ville synes en logisk tilføjelse.
Ligesom de nuværende begrænsninger af menneske-centreret animation i Stable Diffusion, selvom de er kickstartet af CogVideo og forskellige andre projekter, er stadig ekstremt spæde og afhængige af opstrømsforskning i tidsmæssige prioriteringer i forhold til ægte menneskelig bevægelse.
I øjeblikket er Stable Diffusion-video strengt psykedelisk, selvom det måske har en lysere nære fremtid i deepfake-dukke-spil via EbSynth og andre relativt spæde tekst-til-video-initiativer (og det er værd at bemærke manglen på syntetiserede eller “ændrede” personer i Runways seneste promotionsvideo).
En anden værdifuld funktionalitet ville være gennemsigtigt Photoshop-gennemløb, der har været etableret i Cinema4D’s tekstur-editor, blandt andre lignende implementationer. Med dette kan man let flytte billeder mellem programmer og bruge hvert program til at udføre de transformationer, det excellerer i.
Til sidst, og måske aller vigtigst, burde en fuldt udbygget desktop-Stable Diffusion-program være i stand til ikke kun at skifte let mellem checkpoints (dvs. versioner af den underliggende model, der driver systemet), men også være i stand til at opdatere brugerdefinerede Tekstuelle Inversioner, der fungerede med tidligere officielle modeludgaver, men ellers kunne være brudt af senere versioner af modellen (som udviklere på det officielle Discord har antydet kunne være tilfældet).












