
Umělá inteligence
LipSync3D od Googlu nabízí vylepšenou synchronizaci pohybu úst „Deepfaked“.

A spolupráce mezi výzkumníky Google AI a Indian Institute of Technology Kharagpur nabízí nový rámec pro syntézu mluvících hlav ze zvukového obsahu. Projekt si klade za cíl vytvořit optimalizované způsoby s rozumnými zdroji, jak vytvořit videoobsah „mluvící hlavy“ ze zvuku, pro účely synchronizace pohybů rtů s dabovaným nebo strojově přeloženým zvukem a pro použití v avatarech, v interaktivních aplikacích a dalších prostředí v reálném čase.

Zdroj: https://www.youtube.com/watch?v=L1StbX9OznY
Modely strojového učení trénované v tomto procesu – nazývané LipSync3D – vyžadují jako vstupní data pouze jedno video identity cílové tváře. Potrubí pro přípravu dat odděluje extrakci geometrie obličeje od hodnocení osvětlení a dalších aspektů vstupního videa, což umožňuje hospodárnější a cílenější trénink.
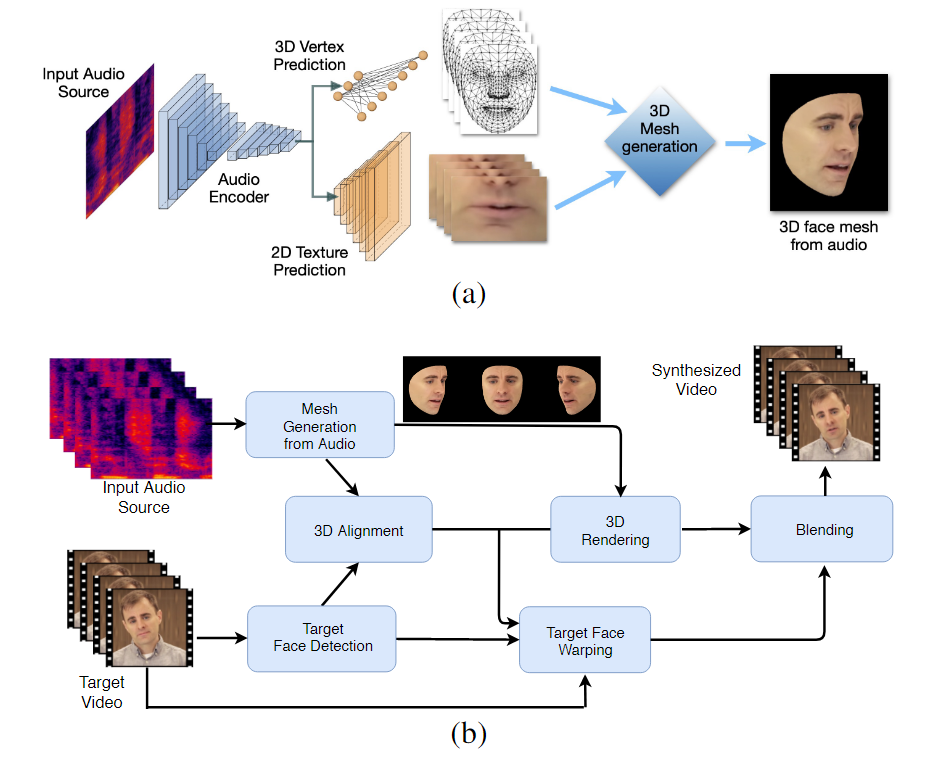
Dvoufázový pracovní postup LipSync3D. Nahoře generování dynamicky texturovaného 3D obličeje z „cílového“ zvuku; níže vložení vygenerované sítě do cílového videa.
Ve skutečnosti může být nejpozoruhodnějším příspěvkem LipSync3D k výzkumnému úsilí v této oblasti jeho algoritmus normalizace osvětlení, který odděluje trénink a inferenční osvětlení.

Oddělení dat osvětlení od obecné geometrie pomáhá LipSync3D vytvářet realističtější výstup pohybu rtů v náročných podmínkách. Jiné přístupy posledních let se omezily na „pevné“ světelné podmínky, které v tomto ohledu neprozradí jejich omezenější kapacitu.
Během předběžného zpracování vstupních datových snímků musí systém identifikovat a odstranit zrcadlové body, protože ty jsou specifické pro světelné podmínky, za kterých bylo video pořízeno, a jinak budou rušit proces opětovného osvětlení.

LipSync3D, jak jeho název napovídá, neprovádí pouhou pixelovou analýzu na tvářích, které vyhodnocuje, ale aktivně využívá identifikované orientační body obličeje ke generování pohyblivých sítí ve stylu CGI spolu s „rozloženými“ texturami, které jsou kolem nich zabaleny v tradičním CGI. potrubí.

Normalizace pozice v LipSync3D. Vlevo jsou vstupní snímky a detekované prvky; uprostřed normalizované vrcholy vyhodnocení generované sítě; a vpravo odpovídající atlas textury, který poskytuje základní pravdu pro předpověď textury. Zdroj: https://arxiv.org/pdf/2106.04185.pdf
Kromě nové metody přesvícení vědci tvrdí, že LipSync3D nabízí tři hlavní inovace předchozí práce: oddělení geometrie, osvětlení, pozice a textury do diskrétních datových toků v normalizovaném prostoru; snadno trénovatelný model auto-regresivní predikce textur, který produkuje časově konzistentní syntézu videa; a vyšší realističnost, jak je hodnoceno lidským hodnocením a objektivními metrikami.

Rozdělení různých aspektů video snímků obličeje umožňuje větší kontrolu při syntéze videa.
LipSync3D dokáže odvodit vhodný pohyb geometrie rtů přímo ze zvuku analýzou fonémů a dalších aspektů řeči a jejich převedením do známých odpovídajících svalových pozic v oblasti úst.

Tento proces využívá kanál společné predikce, kde odvozená geometrie a textura mají vyhrazené kodéry v nastavení autokodéru, ale sdílejí zvukový kodér s řečí, která má být vnucena modelu:

Labilní pohybová syntéza LipSync3D je také určena k napájení stylizovaných CGI avatarů, které jsou ve skutečnosti pouze stejným druhem informací o síti a texturách jako snímky v reálném světě:
Stylizovaný 3D avatar má pohyby rtů poháněné v reálném čase pomocí videa ze zdrojového reproduktoru. V takovém scénáři by nejlepších výsledků bylo dosaženo personalizovaným předškolením.
Vědci také předpokládají použití avatarů s trochu realističtějším dojmem:
![]()
Ukázkové tréninkové doby pro videa se pohybují v rozmezí 3–5 hodin pro 2–5minutové video, v procesu, který využívá TensorFlow, Python a C++ na GeForce GTX 1080. Tréninky používaly velikost dávky 128 snímků přes 500–1000 epoch, přičemž každá epocha představuje kompletní vyhodnocení videa.

Směrem k dynamické re-synchronizaci pohybu rtů
Oblasti opětovné synchronizace rtů pro umístění nové zvukové stopy se v posledních několika letech dostalo velké pozornosti ve výzkumu počítačového vidění (viz níže), v neposlední řadě proto, že jde o vedlejší produkt kontroverzních technologie deepfake.
V roce 2017 University of Washington prezentovaný výzkum schopný naučit se synchronizaci rtů ze zvuku a pomocí něj změnit pohyby rtů tehdejšího prezidenta Obamy. V roce 2018; vedl Institut Maxe Plancka pro informatiku další výzkumná iniciativa pro umožnění přenosu identity>identity videa se synchronizací rtů a vedlejší produkt procesu; a v květnu 2021 startup FlawlessAI s umělou inteligencí odhalil svou patentovanou technologii synchronizace rtů TrueSync. obdržel v tisku jako umožnění vylepšených dabovacích technologií pro hlavní filmová vydání napříč jazyky.
A samozřejmě pokračující vývoj deepfake open source úložišť poskytuje další odvětví aktivního uživatelského výzkumu v této sféře syntézy obličejových obrázků.















