Umělá inteligence
Adobe Research Rozšiřuje Disentangled GAN Face Editing

Není těžké pochopit, proč je entanglement problémem v image synthesis, protože je to často problém v jiných oblastech života; například je mnohem těžší odstranit kurkumu z kari než vyhodit nakládanou okurku z hamburgeru, a je prakticky nemožné odstranit sladkost z šálku kávy. Některé věci prostě přicházejí v balíčku.
Podobně je entanglement překážkou pro architektury image synthesis, které by ideálně chtěly oddělit různé funkce a koncepty při použití strojového učení pro vytváření nebo editaci obličejů (nebo psů, lodí nebo jiných domén).
Pokud byste mohli oddělit vlákna, jako je věk, pohlaví, barva vlasů, barva kůže, emocionální stav a tak dále, měli byste začátek skutečné instrumentality a flexibility v rámci, který by mohl vytvářet a editovat obličejové obrázky na skutečně granulární úrovni, bez tahání nežádoucích “cestujících” do těchto konverzí.

Při maximálním entanglementu (nahoře vlevo) můžete udělat pouze změnu obrázku naučené GAN sítě na obrázek jiného člověka.
To je efektivní použití nejnovější technologie počítačového vidění k dosažení něčeho, co bylo vyřešeno jinými prostředky před více než třiceti lety.
S určitým stupněm separace (‘Medium Separation’ v předchozím obrázku) je možné provádět style-based změny, jako je barva vlasů, výraz, kosmetické aplikace a omezená rotace hlavy, mezi ostatními.

Source: FEAT: Face Editing with Attention, February 2022, https://arxiv.org/pdf/2202.02713.pdf
Bylo provedeno několik pokusů v posledních dvou letech o vytvoření interaktivních face-editing prostředí, která umožňují uživateli měnit obličejové charakteristiky se slidery a jinými tradičními UI interakcemi, zatímco udržují základní funkce cílového obličeje při přidávání nebo měnění. Nicméně, to se ukázalo jako výzva kvůli podkladovému feature/style entanglementu v latentním prostoru GAN.
Například, brýle trait je často spojena s věkem trait, což znamená, že přidání brýlí může také “zestárnout” obličej, zatímco zestárnění obličeje může přidat brýle, v závislosti na stupni aplikované separace vysokých funkcí (viz ‘Testing’ níže pro příklady).
Nejnápadnější je, že je téměř nemožné změnit barvu vlasů a jiné vlasové aspekty bez přepočítání vlasových vláken a dispozice, což dává “sizzling”, přechodný efekt.

Source: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-to-Latent GAN Traversal
Nový Adobe-led paper entered for WACV 2022 nabízí novou přístup k těmto základním problémům v paper entitled Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images.

Supplemental material from the paper Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images. Here we see that base characteristics in the learned face are not dragged into unrelated changes. See full video embed at end of article for better detail and resolution. Source: https://www.youtube.com/watch?v=rf_61llRH0Q
Paper je veden Adobe Applied Scientist Siavash Khodadadeh, společně s čtyřmi dalšími Adobe výzkumníky a výzkumníkem z Department of Computer Science at the University of Central Florida.
Paper je zajímavý částečně proto, že Adobe operuje v tomto prostoru již nějakou dobu, a je lákavé si představit, že tato funkčnost vstoupí do Creative Suite projektu v příštích několika letech; ale hlavně proto, že architektura vytvořená pro projekt bere jiný přístup k udržení vizuální integrity v GAN face editoru, zatímco se provádějí změny.
Autoři prohlašují:
‘[We] train a neural network to perform a latent-to-latent transformation which finds the latent encoding corresponding to the image with the changed attribute. As the technique is one-shot, it does not rely on a linear or non-linear trajectory of the gradual change of the attributes.
‘By training the network end-to-end over the full generation pipeline, the system can adapt to the latent spaces of off-the-shelf generator architectures. Conservation properties, such as maintaining the identity of the person can be encoded in the form of training losses.
‘Once the latent-to-latent network was trained, it can be reused for arbitrary images without retraining.’
To znamená, že navrhovaná architektura přichází s koncovým uživatelem v dokončeném stavu. Stále potřebuje spustit neuronovou síť na místních zdrojích, ale nové obrázky lze “přidat” a být připraveny pro úpravu téměř okamžitě, protože rámec je dostatečně odpojen, aby nemusel být dále trénován.
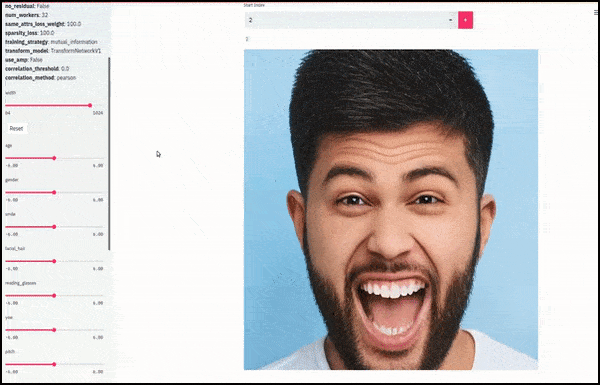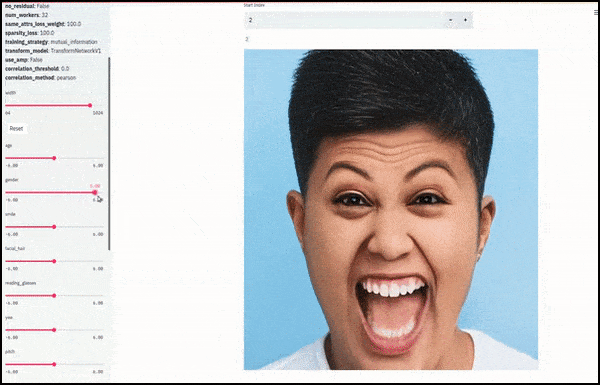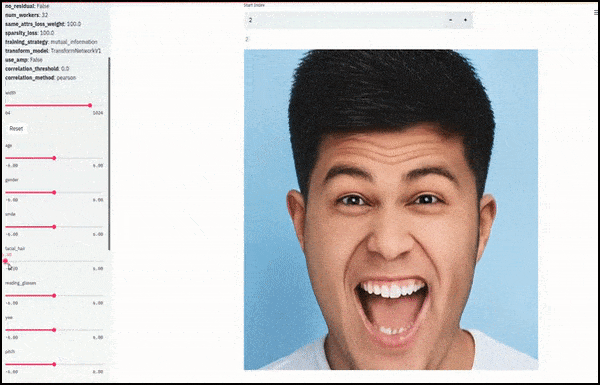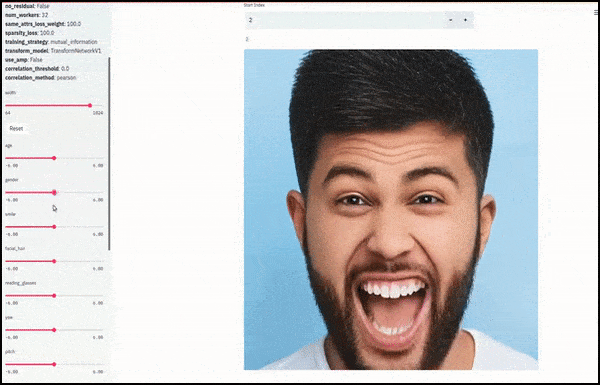
Gender and facial hair changed as sliders plot random and arbitrary paths through the latent space, not just ‘scrubbing between endpoints’. See video embedded at end of article for more transformations at better resolution.
Mezi hlavní úspěchy v práci je schopnost sítě “zmrazit” identity v latentním prostoru změnou pouze atributu v cílovém vektoru a poskytováním “korekčních termínů”, které zachovávají identity, které se transformují.
V podstatě je navrhovaná síť vložena do širší architektury, která orchestruje všechny zpracované prvky, které procházejí předem trénovanými komponentami s zmrazenými váhami, které nebudou produkovat nežádoucí boční účinky na transformace.
Protože proces trénování závisí na tripletech, které lze vygenerovat buď ze semenového obrázku (pod GAN inversion) nebo existující počáteční latentní kódování, celý proces trénování je nesupervizovaný, s tacitními akcemi obvyklého rozsahu systémů označování a kultivace v takových systémech efektivně zapékán do architektury. Ve skutečnosti nový systém používá off-the-shelf attribute regresory:
‘[The] number of attributes that our network can independently control is only limited by the capabilities of the recognizer(s) – if one has a recognizer for an attribute, we can add it to arbitrary faces. In our experiments, we trained the latent-to-latent network to allow the adjustment of 35 different facial attributes, more than any previous approach.’
Systém zahrnuje další bezpečnostní opatření proti nežádoucím “vedlejšímu” transformacím: v případě absence žádosti o změnu atributu bude latent-to-latent síť mapovat latentní vektor na sebe sama, dále zvyšuje stabilní persistenci cílové identity.
Rozpoznávání obličeje
Jednou z opakujících se problémů s GAN a encoder/decoder-based face editory v posledních několika letech byla skutečnost, že aplikované transformace tendují ke zhoršení podobnosti. Aby se tomu zabránilo, Adobe projekt používá zabudovaný rozpoznávací síť obličeje nazvaný FaceNet jako diskriminátor.

Project architecture, see lower mid-left for inclusion of FaceNet. Source: Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images, OpenAccess.
(Na osobní poznámku, toto se zdá být povzbudivým krokem směrem k integraci standardních systémů rozpoznávání obličeje a dokonce i rozpoznávání výrazu do generativních sítí, pravděpodobně nejlepší způsob, jak překonat slepé pixel>pixel mapování, které dominuje současným deepfake architekturám na úkor věrnosti výrazu a dalších důležitých domén v sektoru generace obličeje.)
Všechny oblasti v latentním prostoru
Další působivou funkcí rámců je jeho schopnost cestovat libovolně mezi potenciálními transformacemi v latentním prostoru, na libovůli uživatele. Několik předchozích systémů, které poskytovaly průzkumné rozhraní, často nechávaly uživatele efektivně “scrubovat” mezi pevnými funkcemi transformačních časovek – působivé, ale často quite lineární nebo preskriptivní zkušeností.

From Improving GAN Equilibrium by Raising Spatial Awareness: here the user scrubs through a range of potential transition points between two latent space locations, but within the confines of pre-trained locations in the latent space. To apply other kinds of transformation based on the same material, reconfiguration and/or retraining is necessary. Source: https://genforce.github.io/eqgan/
Kromě toho, že je systém přístupný zcela novým uživatelským obrázkům, může uživatel také ručně “zmrazit” prvky, které chce zachovat během transformačního procesu. Tímto způsobem může uživatel zajistit, že (například) pozadí se nezmění, nebo že oči zůstanou otevřené nebo zavřené.
Data
Atributová regresní síť byla trénována na třech sítích: FFHQ, CelebAMask-HQ, a místní, GAN-generovaná síť získaná vzorkováním 400 000 vektorů z prostoru Z StyleGAN-V2.
Out-of-distribution (OOD) obrázky byly filtrovány, a atributy byly extrahovány pomocí Microsoft Azure Face API, s výsledným image-set rozděleným 90/10, což zanechalo 721 218 trénovacích obrázků a 72 172 testovacích obrázků pro srovnání.
Testování
Ačkoli experimentální síť byla inicializována pro akomodaci 35 potenciálních transformací, tyto byly zredukovány na osm, aby se provedlo analogické testování proti srovnatelným rámcům InterFaceGAN, GANSpace, a StyleFlow.
Osm vybraných atributů bylo Age, Baldness, Beard, Expression, Gender, Glasses, Pitch, a Yaw. Bylo nutné retoolovat srovnatelné rámce pro některé z osmi atributů, které nebyly zajištěny v původní distribuci, jako je přidání baldness a beard do InterFaceGAN.
Jak se očekávalo, vyšší stupeň entanglementu se udál v riválních architekturách. Například, v jednom testu, InterFaceGAN a StyleFlow obě změnily pohlaví subjektu, když se požádaly o aplikaci age:

Two of the competing frameworks rolled a gender change into the ‘age’ transformation, also changing hair color without direct bidding of the user.
Kromě toho, dvě z rivalů našly, že brýle a věk jsou neseparovatelné aspekty:

Glasses and hair color change thrown in at no extra charge!
Není to uniformní vítězství pro výzkum: jak lze vidět v doprovodném videu vloženém na konci článku, rámec je nejméně účinný, když se snaží extrapolovat různé úhly (yaw), zatímco GANSpace má lepší obecný výsledek pro age a aplikaci brýlí. Latent-to-latent rámec se vázal s GANSpace a StyleFlow ohledně přidání pitch (úhel hlavy).

Results calculated based on a calibration of the MTCNN face detector. Lower results are better.
Pro další podrobnosti a lepší rozlišení příkladů, podívejte se na doprovodné video níže.
https://www.youtube.com/watch?v=rf_61llRH0Q
Poprvé publikováno 16. února 2022.












