
Изкуствен интелект
YOLOv7: Най-модерният алгоритъм за откриване на обекти?

6 юли 2022 г. ще бъде отбелязан като забележителност в историята на ИИ, тъй като на този ден беше пуснат YOLOv7. Още от стартирането си, YOLOv7 е най-горещата тема в общността на разработчиците на Computer Vision и по правилните причини. YOLOv7 вече се смята за крайъгълен камък в индустрията за откриване на обекти.
Скоро след Документът YOLOv7 беше публикуван, той се оказа най-бързият и най-точен модел за откриване на възражения в реално време. Но как YOLOv7 надминава своите предшественици? Какво прави YOLOv7 толкова ефективен при изпълнението на задачи за компютърно зрение?
В тази статия ще се опитаме да анализираме модела YOLOv7 и ще се опитаме да намерим отговора на въпроса защо YOLOv7 вече се превръща в индустриален стандарт? Но преди да можем да отговорим на това, ще трябва да разгледаме кратката история на откриването на обекти.
Какво е откриване на обект?
Откриването на обекти е клон на компютърното зрение който идентифицира и локализира обекти в изображение или видео файл. Откриването на обекти е градивният елемент на множество приложения, включително самоуправляващи се автомобили, наблюдавано наблюдение и дори роботика.
Един модел за откриване на обект може да бъде класифициран в две различни категории, едноизстрелни детектори, намлява многоизстрелни детектори.
Откриване на обекти в реално време
За да разберем наистина как работи YOLOv7, за нас е важно да разберем основната цел на YOLOv7, “Откриване на обекти в реално време”. Откриването на обекти в реално време е ключов компонент на съвременното компютърно зрение. Моделите за откриване на обекти в реално време се опитват да идентифицират и локализират интересни обекти в реално време. Моделите за откриване на обекти в реално време направиха наистина ефективно за разработчиците проследяването на интересни обекти в движещ се кадър като видео или вход за наблюдение на живо.

Моделите за откриване на обекти в реално време са по същество една крачка напред от конвенционалните модели за откриване на изображения. Докато първият се използва за проследяване на обекти във видео файлове, вторият локализира и идентифицира обекти в неподвижна рамка като изображение.
В резултат на това моделите за откриване на обекти в реално време са наистина ефективни за видео анализи, автономни превозни средства, преброяване на обекти, проследяване на множество обекти и много други.
Какво е YOLO?
YOLO или „Гледаш само веднъж” е семейство модели за откриване на обекти в реално време. Концепцията YOLO беше представена за първи път през 2016 г. от Джоузеф Редмън и за нея се заговори почти мигновено, защото беше много по-бърза и много по-точна от съществуващите алгоритми за откриване на обекти. Не след дълго алгоритъмът YOLO се превърна в стандарт в индустрията за компютърно зрение.

Основната концепция, която алгоритъмът YOLO предлага, е да се използва невронна мрежа от край до край, използваща ограничаващи кутии и вероятности за класове, за да се правят прогнози в реално време. YOLO беше различен от предишния модел за откриване на обекти в смисъл, че предлагаше различен подход за извършване на откриване на обекти чрез повторно предназначение на класификаторите.
Промяната в подхода проработи, тъй като YOLO скоро се превърна в индустриален стандарт, тъй като разликата в производителността между себе си и други алгоритми за откриване на обекти в реално време бяха значителни. Но каква беше причината, поради която YOLO беше толкова ефективен?
В сравнение с YOLO, тогавашните алгоритми за откриване на обекти използваха регионални мрежи за предложения за откриване на възможни региони от интерес. След това процесът на разпознаване беше извършен за всеки регион поотделно. В резултат на това тези модели често извършват множество итерации на едно и също изображение и оттук липсата на точност и по-високо време за изпълнение. От друга страна, алгоритъмът YOLO използва единичен напълно свързан слой, за да извърши прогнозата наведнъж.
Как работи YOLO?
Има три стъпки, които обясняват как работи алгоритъмът YOLO.
Преформулиране на откриването на обект като проблем с единична регресия
- Алгоритъмът YOLO се опитва да преформулира откриването на обект като единичен регресионен проблем, включително пиксели на изображението, към вероятностите на класа и координатите на ограничителната кутия. Следователно алгоритъмът трябва да погледне изображението само веднъж, за да предвиди и локализира целевите обекти в изображенията.
Причинява имиджа в световен мащаб
Освен това, когато алгоритъмът YOLO прави прогнози, той обмисля изображението глобално. Различава се от техниките, базирани на регионални предложения и плъзгащи се техники, тъй като алгоритъмът YOLO вижда пълното изображение по време на обучение и тестване на набора от данни и е в състояние да кодира контекстуална информация за класовете и как се появяват.
Преди YOLO, Fast R-CNN беше един от най-популярните алгоритми за откриване на обекти, който не можеше да види по-големия контекст в изображението, тъй като използваше грешката да бърка фонови петна в изображение за обект. В сравнение с алгоритъма Fast R-CNN, YOLO е 50% по-точен когато става въпрос за фонови грешки.
Обобщава представянето на обекти
И накрая, алгоритъмът YOLO също има за цел да обобщи представянето на обекти в изображение. В резултат на това, когато алгоритъмът на YOLO беше изпълнен върху набор от данни с естествени изображения и тестван за резултатите, YOLO надмина съществуващите модели на R-CNN с голяма разлика. Това е така, защото YOLO е силно генерализиран, шансовете той да се разпадне, когато се внедри при неочаквани входове или нови домейни, бяха малки.
YOLOv7: Какво ново?
След като имаме основно разбиране какво представляват моделите за откриване на обекти в реално време и какво представлява алгоритъмът YOLO, време е да обсъдим алгоритъма YOLOv7.
Оптимизиране на тренировъчния процес
Алгоритъмът YOLOv7 не само се опитва да оптимизира архитектурата на модела, но също така има за цел да оптимизира процеса на обучение. Той има за цел да използва оптимизационни модули и методи за подобряване на точността на откриване на обекти, увеличаване на разходите за обучение, като същевременно поддържа разходите за смущения. Тези модули за оптимизация могат да бъдат посочени като a тренируема чанта с безплатни предмети.
Насочване на етикета от грубо към фино олово
Алгоритъмът YOLOv7 планира да използва ново присвояване на насочвани етикети от грубо към фино олово вместо конвенционалното Динамично присвояване на етикети. Това е така, защото при динамичното присвояване на етикети, обучението на модел с множество изходни слоеве причинява някои проблеми, най-често срещаният от които е как да присвоите динамични цели за различни клонове и техните изходи.
Повторна параметризация на модела
Повторното параметризиране на модела е важна концепция при откриването на обекти и използването му обикновено е последвано от някои проблеми по време на обучението. Алгоритъмът YOLOv7 планира да използва концепцията за път на разпространение на градиента за анализиране на политиките за повторно параметризиране на модела приложими към различни слоеве в мрежата.
Разширяване и комбинирано мащабиране
Алгоритъмът YOLOv7 също въвежда разширени и комбинирани методи за скалиране за използване и ефективно използване на параметрите и изчисленията за откриване на обекти в реално време.

YOLOv7 : Свързана работа
Откриване на обекти в реално време
YOLO в момента е индустриален стандарт и повечето детектори за обекти в реално време използват YOLO алгоритми и FCOS (напълно конволюционно едноетапно откриване на обекти). Най-модерният детектор на обекти в реално време обикновено има следните характеристики
- По-силна и по-бърза мрежова архитектура.
- Ефективен метод за интегриране на функции.
- Точен метод за откриване на обекти.
- Стабилна функция на загуба.
- Ефективен метод за присвояване на етикети.
- Ефективен метод на обучение.
Алгоритъмът YOLOv7 не използва методи за самоконтролирано обучение и дестилация, които често изискват големи количества данни. Обратно, алгоритъмът YOLOv7 използва метод, който може да се обучава с торба с безплатни предмети.
Повторна параметризация на модела
Техниките за повторно параметризиране на модела се разглеждат като ансамбълна техника, която обединява множество изчислителни модули в етап на интерференция. Техниката може да бъде допълнително разделена на две категории, ансамбъл на ниво модел, намлява ансамбъл на ниво модул.
Сега, за да се получи окончателният модел на смущение, техниката за препараметризиране на ниво модел използва две практики. Първата практика използва различни данни за обучение, за да обучи множество идентични модели и след това осреднява теглата на обучените модели. Алтернативно, другата практика усреднява теглата на моделите по време на различни итерации.
Повторното параметризиране на ниво модул набира огромна популярност напоследък, защото разделя модула на различни модулни клонове или различни идентични клонове по време на фазата на обучение и след това продължава да интегрира тези различни клонове в еквивалентен модул, докато се намесва.
Въпреки това, техниките за повторно параметризиране не могат да бъдат приложени към всички видове архитектура. Това е причината, поради която Алгоритъмът YOLOv7 използва нови техники за повторно параметризиране на модела за проектиране на свързани стратегии подходящ за различни архитектури.
Мащабиране на модела
Мащабирането на модел е процесът на мащабиране нагоре или надолу на съществуващ модел, така че да пасва на различни компютърни устройства. Мащабирането на модела обикновено използва различни фактори като брой слоеве (дълбочина), размер на входните изображения (резолюция), брой пирамиди на характеристиките (етап) и брой канали (Широчината). Тези фактори играят решаваща роля за осигуряване на балансиран компромис за мрежови параметри, скорост на смущения, изчисление и точност на модела.
Един от най-често използваните методи за мащабиране е NAS или търсене на мрежова архитектура който автоматично търси подходящи коефициенти на мащабиране от търсачките без никакви сложни правила. Основният недостатък на използването на NAS е, че това е скъп подход за търсене на подходящи фактори за мащабиране.
Почти всеки модел за повторно параметризиране на модела анализира индивидуални и уникални коефициенти на мащабиране независимо и освен това дори оптимизира тези фактори независимо. Това е така, защото архитектурата на NAS работи с некорелирани коефициенти на мащабиране.
Струва си да се отбележи, че базираните на конкатенация модели като VoVNet or DenseNet променете входната ширина на няколко слоя, когато дълбочината на моделите се мащабира. YOLOv7 работи върху предложена архитектура, базирана на конкатенация, и следователно използва комбиниран метод за мащабиране.

Цифрата, спомената по-горе, сравнява разширени ефективни мрежи за агрегиране на слоеве (E-ELAN) на различни модели. Предложеният метод E-ELAN поддържа градиентния път на предаване на оригиналната архитектура, но има за цел да увеличи кардиналността на добавените функции, използвайки групова конволюция. Процесът може да подобри функциите, научени от различни карти, и може допълнително да направи използването на изчисления и параметри по-ефективно.
YOLOv7 Архитектура
Моделът YOLOv7 използва моделите YOLOv4, YOLO-R и Scaled YOLOv4 като своя основа. YOLOv7 е резултат от експериментите, проведени върху тези модели, за да се подобрят резултатите и да се направи моделът по-точен.
Разширена ефективна мрежа за агрегиране на слоеве или E-ELAN
E-ELAN е основният градивен елемент на модела YOLOv7 и е извлечен от вече съществуващи модели за мрежова ефективност, главно ELAN.
Основните съображения при проектирането на ефективна архитектура са броят на параметрите, изчислителната плътност и обемът на изчисленията. Други модели също отчитат фактори като влиянието на съотношението вход/изход на канала, разклоненията в архитектурата на мрежата, скоростта на смущения в мрежата, броя на елементите в тензорите на конволюционната мрежа и други.
- CSPVoNet Моделът не само взема предвид гореспоменатите параметри, но също така анализира пътя на градиента, за да научи повече разнообразни характеристики, като активира теглата на различни слоеве. Подходът позволява смущенията да бъдат много по-бързи и точни. The ELAN Архитектурата има за цел да проектира ефективна мрежа за контрол на най-късия най-дълъг градиентен път, така че мрежата да може да бъде по-ефективна при обучение и конвергенция.
ELAN вече е достигнал стабилен етап, независимо от броя на подреждането на изчислителните блокове и дължината на пътя на градиента. Стабилното състояние може да бъде унищожено, ако изчислителните блокове са подредени неограничено и степента на използване на параметъра ще намалее. The предложената E-ELAN архитектура може да реши проблема, тъй като използва кардиналност на разширяване, разбъркване и сливане непрекъснато да подобрява способността за обучение на мрежата, като същевременно запазва оригиналния градиентен път.
Освен това, когато сравняваме архитектурата на E-ELAN с ELAN, единствената разлика е в изчислителния блок, докато архитектурата на преходния слой е непроменена.
E-ELAN предлага разширяване на кардиналността на изчислителните блокове и разширяване на канала чрез използване групова конволюция. След това картата на характеристиките ще бъде изчислена и разбъркана в групи според груповия параметър и след това ще бъде свързана заедно. Броят на каналите във всяка група ще остане същият като в оригиналната архитектура. И накрая, ще бъдат добавени групите карти на функции за изпълнение на кардиналност.
Мащабиране на модели за модели, базирани на конкатенация
Мащабирането на модела помага при коригиране на атрибутите на моделите което помага при генерирането на модели според изискванията и с различни мащаби, за да се отговори на различните скорости на смущения.

Фигурата говори за мащабиране на модел за различни модели, базирани на конкатенация. Както можете на фигура (a) и (b), изходната ширина на изчислителния блок се увеличава с увеличаване на мащабирането на дълбочината на моделите. В резултат на това входната ширина на предавателните слоеве се увеличава. Ако тези методи са приложени на архитектура, базирана на конкатенация, процесът на мащабиране се извършва в дълбочина и е изобразен на фигура (c).
Следователно може да се заключи, че не е възможно да се анализират мащабиращите фактори независимо за модели, базирани на конкатенация, и по-скоро те трябва да се разглеждат или анализират заедно. Следователно, за базиран на конкатенация модел, подходящо е да се използва съответният метод за мащабиране на комбинирания модел. Освен това, когато коефициентът на дълбочина се мащабира, изходният канал на блока също трябва да бъде мащабиран.
Тренировъчна чанта с безплатни предмети
Чанта с безплатни продукти е термин, който разработчиците използват, за да опишат набор от методи или техники, които могат да променят стратегията или разходите за обучение в опит да се повиши точността на модела. И така, какви са тези обучаеми торби с безплатни предмети в YOLOv7? Нека погледнем.
Планирана повторно параметризирана конволюция
Алгоритъмът YOLOv7 използва градиентни пътища за разпространение на потока, за да определи как идеално да комбинирате мрежа с повторно параметризираната конволюция. Този подход на YOLov7 е опит за противодействие RepConv алгоритъм че въпреки че се представи спокойно на модела VGG, се представя зле, когато се приложи директно към моделите DenseNet и ResNet.
За идентифициране на връзките в конволюционен слой, Алгоритъмът RepConv комбинира намотка 3 × 3 и намотка 1 × 1. Ако анализираме алгоритъма, неговата производителност и архитектурата, ще забележим, че RepConv унищожава конкатенация в DenseNet и остатъка в ResNet.

Изображението по-горе изобразява планиран повторно параметризиран модел. Може да се види, че алгоритъмът YOLov7 установи, че слой в мрежата с конкатенация или остатъчни връзки не трябва да има връзка за идентичност в алгоритъма RepConv. В резултат на това е приемливо да превключвате с RepConvN без връзки за самоличност.
Груб за спомагателни и фини за загуба на олово
Дълбок надзор е клон в компютърните науки, който често намира своето приложение в процеса на обучение на дълбоки мрежи. Основният принцип на дълбокия надзор е, че то добавя допълнителна спомагателна глава в средните слоеве на мрежата заедно с плитките мрежови тежести със загуба на асистент като ръководство. Алгоритъмът YOLOv7 се отнася до главата, която е отговорна за крайния резултат, като водеща глава, а спомагателната глава е главата, която подпомага обучението.
Продължавайки напред, YOLOv7 използва различен метод за присвояване на етикети. Обикновено присвояването на етикети се използва за генериране на етикети чрез препращане директно към основната истина и въз основа на даден набор от правила. През последните години обаче разпределението и качеството на въведените прогнози играят важна роля за генериране на надежден етикет. YOLOv7 генерира мек етикет на обекта чрез използване на прогнозите на ограничителната кутия и истината на земята.
Освен това, новият метод за присвояване на етикети на алгоритъма YOLOv7 използва прогнозите на водещата глава, за да ръководи както водещата, така и спомагателната глава. Методът за присвояване на етикети има две предложени стратегии.
Водещ главен разпределител на етикети
Стратегията прави изчисления на базата на резултатите от прогнозата на водещата глава и основната истина и след това използва оптимизация за генериране на меки етикети. След това тези меки етикети се използват като тренировъчен модел както за водещата глава, така и за спомагателната глава.
Стратегията работи на предположението, че тъй като водещата глава има по-голяма способност за обучение, етикетите, които генерира, трябва да бъдат по-представителни и да корелират между източника и целта.
Устройство за присвояване на етикети с насочена оловна глава от грубо към фино
Тази стратегия също така прави изчисления на базата на резултатите от прогнозата на водещата глава и истината на земята и след това използва оптимизация за генериране на меки етикети. Има обаче ключова разлика. В тази стратегия има два комплекта меки етикети, грубо ниво, намлява фин етикет.
Грубият етикет се генерира чрез облекчаване на ограниченията на положителната проба
процес на присвояване, който третира повече мрежи като положителни цели. Това се прави, за да се избегне рискът от загуба на информация поради по-слабата сила на заучаване на спомагателната глава.

Фигурата по-горе обяснява използването на обучим пакет с безплатни в алгоритъма YOLOv7. Той изобразява грубо за спомагателната глава и фино за водещата глава. Когато сравняваме модел със спомагателна глава (b) с нормалния модел (a), ще забележим, че схемата в (b) има спомагателна глава, докато в (a) не е.
Фигура (c) изобразява общия независим инструмент за присвояване на етикети, докато фигура (d) и фигура (e) представляват съответно водещия направляван присвоител и водещия направляван присвоител от грубо към фино, използвани от YOLOv7.
Друга обучаема чанта с безплатни предмети
В допълнение към споменатите по-горе, алгоритъмът YOLOv7 използва допълнителни пакети с безплатни продукти, въпреки че не са били предложени от тях първоначално. Те са
- Пакетно нормализиране в Conv-Bn-Activation Technology: Тази стратегия се използва за свързване на конволюционен слой директно към слоя за нормализиране на пакета.
- Неявни знания в YOLOR: YOLOv7 съчетава стратегията с картата на функциите Convolutional.
- Модел на EMA: Моделът EMA се използва като окончателен референтен модел в YOLOv7, въпреки че основната му употреба е да се използва в метода на средния учител.
YOLOv7 : Експерименти
Експериментална настройка
Алгоритъмът YOLOv7 използва Набор от данни на Microsoft COCO за обучение и валидиране техния модел за откриване на обекти и не всички от тези експерименти използват предварително обучен модел. Разработчиците са използвали набора от данни за влакове от 2017 г. за обучение и са използвали набора от данни за валидиране от 2017 г. за избор на хиперпараметри. И накрая, ефективността на резултатите от откриването на обекти YOLOv7 се сравнява с най-съвременните алгоритми за откриване на обекти.
Разработчиците проектираха основен модел за edge GPU (YOLOv7-tiny), нормален GPU (YOLOv7) и облачен GPU (YOLOv7-W6). Освен това алгоритъмът YOLOv7 също използва основен модел за мащабиране на модела според изискванията на различни услуги и получава различни модели. За алгоритъма YOLOv7 мащабирането на стека се извършва на врата и предложените съединения се използват за увеличаване на дълбочината и ширината на модела.
База
Алгоритъмът YOLOv7 използва предишни модели YOLO и алгоритъма за откриване на обект YOLOR като базова линия.

Горната фигура сравнява базовата линия на модела YOLOv7 с други модели за откриване на обекти и резултатите са доста очевидни. В сравнение с Алгоритъм YOLOv4, YOLOv7 не само използва 75% по-малко параметри, но също така използва 15% по-малко изчисления и има 0.4% по-висока точност.
Сравнение с най-съвременните модели на детектори на обекти

Фигурата по-горе показва резултатите, когато YOLOv7 се сравнява с най-съвременните модели за откриване на обекти за мобилни и общи GPU. Може да се отбележи, че методът, предложен от алгоритъма YOLOv7, има най-добрия резултат за компромис между скорост и точност.
Изследване на аблация: Предложен метод за скалиране на съединение

Фигурата, показана по-горе, сравнява резултатите от използването на различни стратегии за мащабиране на модела. Стратегията за мащабиране в модела YOLOv7 увеличава дълбочината на изчислителния блок с 1.5 пъти и мащабира ширината с 1.25 пъти.
В сравнение с модел, който увеличава само дълбочината, моделът YOLOv7 се представя по-добре с 0.5%, като същевременно използва по-малко параметри и изчислителна мощност. От друга страна, в сравнение с модели, които увеличават само дълбочината, точността на YOLOv7 е подобрена с 0.2%, но броят на параметрите трябва да бъде мащабиран с 2.9%, а изчисленията с 1.2%.
Предложен планиран препараметризиран модел
За да провери общността на предложения си повторно параметризиран модел, the Алгоритъмът YOLOv7 го използва на базирани на остатъци и базирани на конкатенация модели за проверка. За процеса на проверка се използва алгоритъмът YOLOv7 3-подреден ELAN за модела, базиран на конкатенация, и CSPDarknet за модел, базиран на остатък.
За модела, базиран на конкатенация, алгоритъмът заменя 3×3 конволюционните слоеве в 3-подредения ELAN с RepConv. Фигурата по-долу показва подробната конфигурация на Planned RepConv и 3-stacked ELAN.
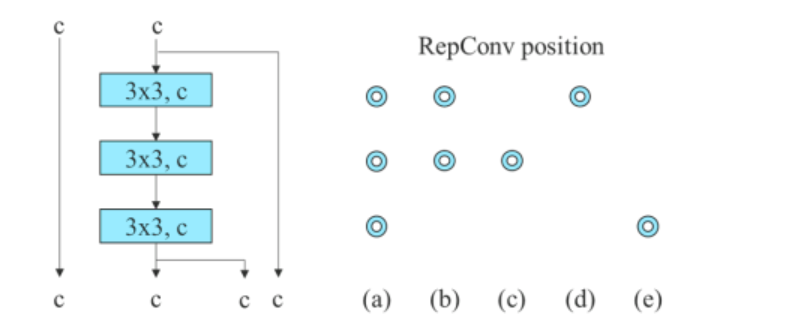
Освен това, когато се работи с модела, базиран на остатъци, алгоритъмът YOLOv7 използва обърнат тъмен блок, тъй като оригиналният тъмен блок няма 3×3 блок за навиване. Фигурата по-долу показва архитектурата на Reversed CSPDarknet, която обръща позициите на 3×3 и 1×1 конволюционния слой. 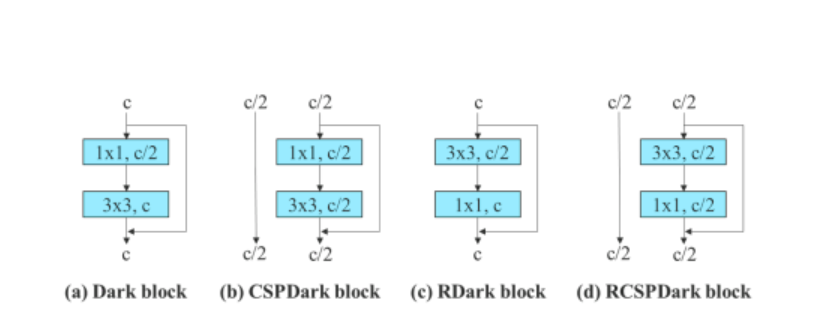
Предложена загуба на асистент за спомагателна глава
За асистентната загуба за спомагателна глава моделът YOLOv7 сравнява независимото присвояване на етикети за методите на спомагателната глава и водещата глава.

Фигурата по-горе съдържа резултатите от изследването на предложената спомагателна глава. Може да се види, че общата производителност на модела се увеличава с увеличаване на загубата на помощник. Освен това присвояването на етикети с насочване на водещи, предложено от модела YOLOv7, се представя по-добре от стратегиите за независимо присвояване на водещи.
YOLOv7 Резултати
Въз основа на горните експерименти, ето резултатът от производителността на YOLov7 в сравнение с други алгоритми за откриване на обекти.

Горната фигура сравнява модела YOLOv7 с други алгоритми за откриване на обекти и може ясно да се види, че YOLOv7 превъзхожда други модели за откриване на възражения по отношение на Средна прецизност (AP) v/s партидна интерференция.
Освен това фигурата по-долу сравнява производителността на YOLOv7 срещу други алгоритми за откриване на възражения в реално време. За пореден път YOLOv7 успява други модели по отношение на цялостната производителност, точност и ефективност.

Ето някои допълнителни наблюдения от резултатите и представянето на YOLOv7.
- YOLOv7-Tiny е най-малкият модел в семейството на YOLO, с над 6 милиона параметъра. YOLOv7-Tiny има средна точност от 35.2% и превъзхожда моделите YOLOv4-Tiny със сравними параметри.
- Моделът YOLOv7 има над 37 милиона параметъра и превъзхожда модели с по-високи параметри като YOLov4.
- Моделът YOLOv7 има най-високата скорост на mAP и FPS в диапазона от 5 до 160 FPS.
Заключение
YOLO или You Only Look Once е най-съвременният модел за откриване на обекти в съвременното компютърно зрение. Алгоритъмът YOLO е известен със своята висока точност и ефективност и в резултат на това намира широко приложение в индустрията за откриване на обекти в реално време. Откакто първият алгоритъм YOLO беше представен през 2016 г., експериментите позволиха на разработчиците непрекъснато да подобряват модела.
Моделът YOLOv7 е най-новото попълнение в семейството на YOLO и е най-мощният YOLo алгоритъм до момента. В тази статия говорихме за основите на YOLOv7 и се опитахме да обясним какво прави YOLOv7 толкова ефективен.















