
Изкуствен интелект
InstructIR: Възстановяване на висококачествено изображение след човешки инструкции

Едно изображение може да предаде много, но също така може да бъде помрачено от различни проблеми като замъгляване на движението, мъгла, шум и нисък динамичен диапазон. Тези проблеми, обикновено наричани влошаване на компютърното зрение на ниско ниво, могат да възникнат от трудни условия на околната среда като топлина или дъжд или от ограничения на самата камера. Възстановяването на изображението представлява основно предизвикателство в компютърното зрение, стремейки се да възстановите висококачествено, чисто изображение от такова, показващо такива деградации. Възстановяването на изображение е сложно, тъй като може да има множество решения за възстановяване на дадено изображение. Някои подходи са насочени към специфични деградации, като намаляване на шума или премахване на замъгляване или мъгла.
Въпреки че тези методи могат да дадат добри резултати за определени проблеми, те често се борят да обобщават различни видове деградация. Много рамки използват генерична невронна мрежа за широк спектър от задачи за възстановяване на изображения, но всяка от тези мрежи се обучава отделно. Необходимостта от различни модели за всеки тип деградация прави този подход скъп изчислително и отнема много време, което води до фокусиране върху моделите за възстановяване Всичко в едно в последните разработки. Тези модели използват единичен модел за дълбоко сляпо възстановяване, който адресира множество нива и типове деградация, като често използва специфични за деградацията подкани или насочващи вектори за подобряване на производителността. Въпреки че моделите All-In-One обикновено показват обещаващи резултати, те все още са изправени пред предизвикателства с обратни проблеми.
InstructIR представлява новаторски подход в областта, като е първият възстановяване на изображението рамка, предназначена да ръководи модела на възстановяване чрез инструкции, написани от хора. Той може да обработва подкани на естествен език, за да възстанови висококачествени изображения от влошени такива, като взема предвид различни типове влошаване. InstructIR задава нов стандарт в производителността за широк спектър от задачи за възстановяване на изображения, включително обезводняване, обезшумяване, премахване на замъгляване, премахване на замъгляване и подобряване на изображения при слаба светлина.
Тази статия има за цел да покрие в дълбочина рамката на InstructIR и ние изследваме механизма, методологията, архитектурата на рамката заедно с нейното сравнение с най-съвременните рамки за генериране на изображения и видео. Така че да започваме.
InstructIR: Възстановяване на висококачествено изображение
Възстановяването на изображението е основен проблем в компютърното зрение, тъй като има за цел да възстанови висококачествено чисто изображение от изображение, което демонстрира деградации. В компютърното зрение на ниско ниво деградациите са термин, използван за представяне на неприятни ефекти, наблюдавани в изображение, като замъгляване на движението, мъгла, шум, нисък динамичен диапазон и други. Причината, поради която възстановяването на изображения е сложно обратно предизвикателство, е, че може да има множество различни решения за възстановяване на всяко изображение. Някои рамки се фокусират върху специфични деградации, като намаляване на шума на екземпляра или обезшумяване на изображението, докато други могат да се съсредоточат повече върху премахване на замъгляване или премахване на замъгляване, или изчистване на мъгла или премахване на замъгляване.
Последните методи за дълбоко обучение показаха по-силна и по-последователна производителност в сравнение с традиционните методи за възстановяване на изображения. Тези модели за дълбоко обучение за възстановяване на изображения предлагат използването на невронни мрежи, базирани на трансформатори и конволюционни невронни мрежи. Тези модели могат да бъдат обучени независимо за разнообразни задачи за възстановяване на изображения и също така притежават способността да улавят локални и глобални взаимодействия на характеристиките и да ги подобряват, което води до задоволителна и последователна производителност. Въпреки че някои от тези методи могат да работят адекватно за специфични видове разграждане, те обикновено не се екстраполират добре към различни видове разграждане. Освен това, докато много съществуващи рамки използват една и съща невронна мрежа за множество задачи за възстановяване на изображения, всяка формулировка на невронна мрежа се обучава отделно. Следователно е очевидно, че използването на отделен невронен модел за всяка възможна деградация е непрактично и отнема много време, поради което последните рамки за възстановяване на изображения са се концентрирали върху проксита за възстановяване на всичко в едно.
Моделите "всичко в едно" или моделите за многодеградация или многозадачност за възстановяване на изображения набират популярност в полето на компютърното зрение, тъй като са в състояние да възстановят множество типове и нива на деградации в изображение, без да е необходимо моделите да се обучават независимо за всяко деградация . Моделите "всичко в едно" за възстановяване на изображения използват един модел за дълбоко сляпо възстановяване на изображения, за да се справят с различни видове и нива на влошаване на изображението. Различните модели All-In-One прилагат различни подходи за насочване на слепия модел за възстановяване на влошено изображение, например спомагателен модел за класифициране на влошаването или многоизмерни насочващи вектори или подкани, за да помогне на модела да възстанови различни типове влошаване в рамките на изображение.
Като се има предвид това, стигаме до текстово-базирана манипулация на изображения, тъй като тя беше внедрена от няколко рамки през последните няколко години за генериране на текст към изображение и задачи за текстово-базирано редактиране на изображения. Тези модели често използват текстови подкани, за да опишат действия или изображения заедно с тях модели, базирани на дифузия за генериране на съответните изображения. Основното вдъхновение за рамката InstructIR е рамката InstructPix2Pix, която позволява на модела да редактира изображението, като използва потребителски инструкции, които инструктират модела какво действие да извърши вместо текстови етикети, описания или надписи на входното изображение. В резултат на това потребителите могат да използват естествени писмени текстове, за да инструктират модела какво действие да извърши, без да е необходимо да предоставят примерни изображения или допълнителни описания на изображения.
Надграждайки тези основи, рамката InstructIR е първият модел за компютърно зрение, който използва написани от човека инструкции за постигане на възстановяване на изображението и решаване на обратни проблеми. За подкани на естествен език, моделът InstructIR може да възстанови висококачествени изображения от техните влошени двойници и също така взема предвид множество типове влошаване. Рамката на InstructIR е в състояние да осигури най-съвременна производителност при широк спектър от задачи за възстановяване на изображения, включително обезцветяване на изображението, обезшумяване, премахване на замъгляване, премахване на замъгляване и подобряване на изображението при слаба светлина. За разлика от съществуващите произведения, които постигат възстановяване на изображение с помощта на научени вектори за насочване или вграждане на подкани, рамката на InstructIR използва необработени потребителски подкани в текстова форма. Рамката на InstructIR е в състояние да се обобщи за възстановяване на изображения с помощта на човешки писмени инструкции, а единният модел "всичко в едно", внедрен от InstructIR, покрива повече задачи за възстановяване от по-ранните модели. Следващата фигура демонстрира разнообразните проби за възстановяване на рамката InstructIR.

InstructIR: Метод и архитектура
В основата си рамката InstructIR се състои от енкодер на текст и модел на изображение. Моделът използва рамката NAFNet, ефективен модел за възстановяване на изображение, който следва U-Net архитектура като модел на изображението. Освен това моделът прилага техники за маршрутизиране на задачи, за да научи множество задачи, използвайки успешно един модел. Следващата фигура илюстрира подхода за обучение и оценка за рамката на InstructIR.

Черпейки вдъхновение от модела InstructPix2Pix, рамката InstructIR приема човешки писмени инструкции като контролен механизъм, тъй като не е необходимо потребителят да предоставя допълнителна информация. Тези инструкции предлагат изразителен и ясен начин за взаимодействие, позволяващ на потребителите да посочат точното местоположение и вида на влошаването на изображението. Освен това използването на потребителски подкани вместо фиксирани специфични подкани за влошаване подобрява използваемостта и приложенията на модела, тъй като той може да се използва и от потребители, които нямат необходимия опит в областта. За да оборудва рамката на InstructIR с възможност за разбиране на различни подкани, моделът използва GPT-4, голям езиков модел за създаване на различни заявки, с двусмислени и неясни подкани, премахнати след процес на филтриране.
Текстов енкодер
Текстов енкодер се използва от езикови модели за картографиране на потребителските подкани към вграждане на текст или векторно представяне с фиксиран размер. Традиционно текстовият енкодер на a Модел CLIP е жизненоважен компонент за генериране на текстови изображения и модели за манипулиране на текстови изображения за кодиране на потребителски подкани, тъй като рамката CLIP превъзхожда визуалните подкани. Въпреки това, в повечето случаи потребителските подкани за влошаване включват малко или никакво визуално съдържание, поради което правят големите CLIP енкодери безполезни за такива задачи, тъй като това значително ще попречи на ефективността. За да се справи с този проблем, рамката на InstructIR избира текстово базиран енкодер на изречения, който е обучен да кодира изречения в смислено пространство за вграждане. Кодерите за изречения са предварително обучени на милиони примери и въпреки това са компактни и ефективни в сравнение с традиционните текстови кодери, базирани на CLIP, като същевременно имат способността да кодират семантиката на различни потребителски подкани.
Текстово ръководство
Основен аспект на рамката InstructIR е внедряването на кодираната инструкция като контролен механизъм за модела на изображението. Надграждайки това и вдъхновена от маршрутизирането на задачите за обучение на много задачи, рамката InstructIR предлага блок за конструиране на инструкции или ICB, за да даде възможност за специфични за задачите трансформации в рамките на модела. Конвенционалното маршрутизиране на задачи прилага специфични за задачата двоични маски към функциите на канала. Въпреки това, тъй като рамката на InstructIR не познава деградацията, тази техника не се прилага директно. Освен това, за характеристиките на изображението и кодираните инструкции, рамката InstructIR прилага маршрутизиране на задачи и произвежда маската, използвайки линеен слой, активиран с помощта на функцията Sigmoid, за да създаде набор от тегла в зависимост от текстовите вграждания, като по този начин получава c-измерен пер двоична маска на канала. Моделът допълнително подобрява кондиционираните характеристики с помощта на NAFBlock и използва NAFBlock и Instruction Conditioned Block, за да кондиционира характеристиките както в блока на енкодера, така и в блока на декодера.
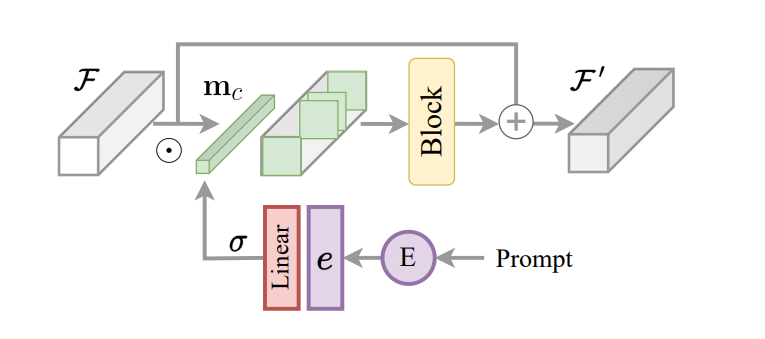
Въпреки че рамката на InstructIR не обуславя изрично филтрите на невронната мрежа, маската улеснява модела да избере най-подходящите канали въз основа на инструкцията и информацията за изображението.
InstructIR: внедряване и резултати
Моделът InstructIR може да се обучава от край до край, а моделът на изображението не изисква предварително обучение. Само проекциите за вграждане на текст и класификационната глава трябва да бъдат обучени. Текстовият енкодер се инициализира с помощта на BGE енкодер, подобен на BERT енкодер, който е предварително обучен върху огромно количество контролирани и неконтролирани данни за кодиране на изречения с обща цел. Рамката InstructIR използва модела NAFNet като модел на изображение, а архитектурата на NAFNet се състои от декодер на 4 нива с различен брой блокове на всяко ниво. Моделът също така добавя 4 средни блока между енкодера и декодера за допълнително подобряване на функциите. Освен това, вместо конкатенация за прескачащи връзки, декодерът прилага добавяне, а моделът InstructIR прилага само ICB или Instruction Conditioned Block за маршрутизиране на задачи само в енкодер и декодер. Продължавайки напред, моделът InstructIR е оптимизиран, като се използва загубата между възстановеното изображение и чистото изображение на основата, а загубата на кръстосана ентропия се използва за главата за класификация на намеренията на текстовия енкодер. Моделът InstructIR използва оптимизатора AdamW с размер на партидата 32 и скорост на обучение 5e-4 за почти 500 епохи и също така прилага намаляване на скоростта на обучение чрез косинусово отгряване. Тъй като моделът на изображението в рамката на InstructIR включва само 16 милиона параметъра и има само 100 хиляди научени параметри за проекция на текст, рамката на InstructIR може лесно да бъде обучена на стандартни графични процесори, като по този начин се намаляват изчислителните разходи и се увеличава приложимостта.
Множество резултати от разграждане
За множество деградации и многозадачни възстановявания рамката InstructIR дефинира две първоначални настройки:
- 3D за модели с три деградации за справяне с проблеми с деградацията, като обезмасляване, обезшумяване и обезводняване.
- 5D за пет модела на влошаване за справяне с проблеми с влошаването като премахване на шума на изображението, подобрения при слаба светлина, премахване на замъгленост, обезшумяване и обезводняване.
Производителността на 5D моделите е демонстрирана в следващата таблица и я сравнява с най-съвременните модели за възстановяване на изображения и всичко-в-едно.

Както може да се види, рамката InstructIR с прост модел на изображение и само 16 милиона параметъра може да се справи успешно с пет различни задачи за възстановяване на изображения благодарение на насоките, базирани на инструкции, и осигурява конкурентни резултати. Следващата таблица демонстрира ефективността на рамката върху 3D модели и резултатите са сравними с горните резултати.

Основният акцент на рамката на InstructIR е възстановяването на изображения въз основа на инструкции и следващата фигура демонстрира невероятните способности на модела InstructIR да разбира широк набор от инструкции за дадена задача. Освен това, за състезателна инструкция, моделът InstructIR изпълнява идентичност, която не е принудена.

Заключителни мисли
Възстановяването на изображението е основен проблем в компютърното зрение, тъй като има за цел да възстанови висококачествено чисто изображение от изображение, което демонстрира деградации. В компютърното зрение на ниско ниво деградациите са термин, използван за представяне на неприятни ефекти, наблюдавани в изображение, като замъгляване на движението, мъгла, шум, нисък динамичен диапазон и други. В тази статия говорихме за InstructIR, първата в света рамка за възстановяване на изображения, която има за цел да ръководи модела за възстановяване на изображения, използвайки инструкции, написани от хора. За подкани на естествен език моделът InstructIR може да възстанови висококачествени изображения от техните влошени двойници и също така взема предвид множество типове влошаване. Рамката на InstructIR е в състояние да осигури най-съвременна производителност при широк спектър от задачи за възстановяване на изображения, включително обезцветяване на изображението, обезшумяване, премахване на замъгляване, премахване на замъгляване и подобряване на изображението при слаба светлина.















