
Изкуствен интелект
Създаване на езиков модел в стил GPT за един въпрос

Изследователи от Китай са разработили икономичен метод за създаване на системи за обработка на естествен език в стил GPT-3, като същевременно избягват все по-прекомерния разход на време и пари, свързани с обучението на масиви от данни с голям обем – нарастваща тенденция, която иначе заплашва в крайна сметка да измести този сектор от ИИ за играчи на FAANG и инвеститори на високо ниво.
Предложената рамка се нарича Езиково моделиране, управлявано от задачи (TLM). Вместо да обучава огромен и сложен модел върху огромен корпус от милиарди думи и хиляди етикети и класове, TLM вместо това обучава много по-малък модел, който всъщност включва заявка директно в модела.

Вляво, типичен хипермащабен подход към езикови модели с голям обем; вдясно, тънък метод на TLM за изследване на голям езиков корпус на базата на тема или на въпрос. Източник: https://arxiv.org/pdf/2111.04130.pdf
Ефективно се създава уникален NLP алгоритъм или модел, за да се отговори на един въпрос, вместо да се създаде огромен и тромав общ езиков модел, който може да отговори на по-голямо разнообразие от въпроси.
При тестването на TLM изследователите установиха, че новият подход постига резултати, които са подобни или по-добри от предварително обучените езикови модели, като напр. RoBERTa-Голями хипермащабни НЛП системи като GPT-3 на OpenAI, TRILLION Parameter Switch Transformer на Google Модел, Корея Хипердетелина, AI21 Labs' Джурасик 1, и на Microsoft Megatron-Turing NLG 530B.
При изпитания на TLM върху осем класификационни набора от данни в четири домейна, авторите допълнително установиха, че системата намалява FLOPs за обучение (операции с плаваща запетая в секунда), изисквани от два порядъка. Изследователите се надяват, че TLM може да „демократизира“ сектор, който става все по-елитен, с НЛП модели, толкова големи, че реалистично не могат да бъдат инсталирани локално, и вместо това да седят, в случая на GPT-3, зад скъп и API с ограничен достъп на OpenAI и, сега, Microsoft Azure.
Авторите заявяват, че намаляването на времето за обучение с два порядъка намалява разходите за обучение над 1,000 GPU за един ден до само 8 GPU за 48 часа.
Новото докладва е озаглавен НЛП от нулата без широкомащабно предварително обучение: проста и ефективна рамка, и идва от трима изследователи от университета Цинхуа в Пекин и изследовател от базираната в Китай компания за разработка на изкуствен интелект Recurrent AI, Inc.
Недостъпни отговори
- цена на обучението на ефективни, универсални езикови модели все повече се характеризира като потенциално „топлинно ограничение“ за степента, до която ефективното и точно НЛП може наистина да се разпространи в културата.
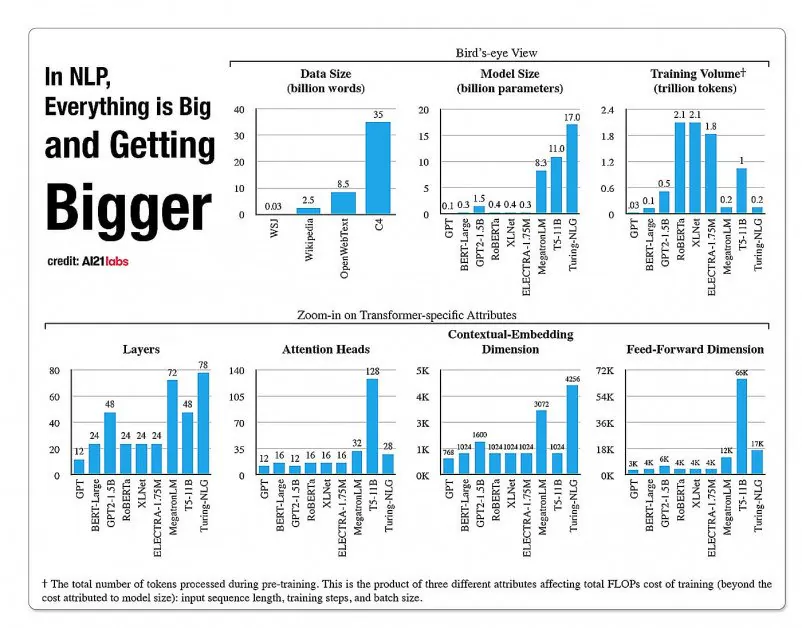
Статистика за растежа на аспектите в архитектурите на моделите на НЛП от доклад за 2020 г. на A121 Labs. Източник: https://arxiv.org/pdf/2004.08900.pdf
През 2019 г. н.с изчислена че струва $61,440 XNUMX USD за обучение на XLNet модел (съобщено по това време, че бие BERT в NLP задачи) за 2.5 дни на 512 ядра в 64 устройства, докато GPT-3 е прогнозна да е струвал 12 милиона долара за обучение – 200 пъти повече от разходите за обучение на своя предшественик, GPT-2 (въпреки че последните преоценки твърдят, че сега може да бъде обучен за само $ 4,600,000 на най-евтините облачни графични процесори) .
Подгрупи от данни, базирани на нуждите на заявката
Вместо това новата предложена архитектура се стреми да извлече точни класификации, етикети и обобщения чрез използване на заявка като вид филтър за дефиниране на подмножество от информация от голяма езикова база данни, която ще бъде обучена, заедно със заявката, за да предостави отговори по ограничена тема.
Авторите заявяват:
„TLM е мотивиран от две ключови идеи. Първо, хората овладяват дадена задача, като използват само малка част от световното знание (напр. студентите трябва да прегледат само няколко глави от всички книги в света, за да се натъпчат за изпит).
„Предполагаме, че има много излишък в големия корпус за конкретна задача. Второ, обучението за контролирани етикетирани данни е много по-ефективно за данни за производителност надолу по веригата, отколкото оптимизирането на целта за езиково моделиране върху немаркирани данни. Въз основа на тези мотивации, TLM използва данните за задачите като заявки, за да извлече малка част от общия корпус. Това е последвано от съвместно оптимизиране на цел на контролирана задача и цел на езиково моделиране, като се използват както извлечените данни, така и данните за задачата.'
Освен че правят високоефективното обучение по НЛП модел достъпно, авторите виждат редица предимства в използването на управлявани от задачи НЛП модели. От една страна, изследователите могат да се насладят на по-голяма гъвкавост с персонализирани стратегии за дължина на последователност, токенизация, настройка на хиперпараметри и представяне на данни.
Изследователите също така предвиждат разработването на хибридни бъдещи системи, които заменят ограниченото предварително обучение на PLM (което иначе не се очаква в текущата реализация) срещу по-голяма гъвкавост и генерализация спрямо времето за обучение. Те смятат системата за крачка напред за напредъка на методите за нулево обобщение в домейна.
Тестване и резултати
TLM беше тестван при предизвикателства за класификация в осем задачи в четири области – биомедицински науки, новини, рецензии и компютърни науки. Задачите бяха разделени на категории с висок и нисък ресурс. Задачите с голям ресурс включват над 5,000 данни за задачи, като напр AGNews намлява RCT, между другото; включени задачи с малко ресурси ChemProt намлява ACL-ARC, Както и на Хиперпартизан набор от данни за откриване на новини.
Изследователите разработиха два комплекта за обучение, озаглавени Corpus-BERT и Corpus-RoBERTa, последният десет пъти по-голям от първия. Експериментите сравняват общите предварително обучени езикови модели БЕРТ (от Google) и РоБЕРТА (от Facebook) към новата архитектура.
Документът отбелязва, че въпреки че TLM е общ метод и трябва да бъде по-ограничен по обхват и приложимост от по-широките и по-обемни съвременни модели, той е в състояние да изпълнява близки до домейн адаптивни методи за фина настройка.

Резултати от сравняване на производителността на TLM спрямо базирани на BERT и RoBERTa набори. Резултатите изброяват среден F1 резултат в три различни скали за обучение и изброяват броя на параметрите, общото изчисление за обучение (FLOP) и размера на обучителния корпус.
Авторите заключават, че TLM е в състояние да постигне резултати, които са сравними или по-добри от PLM, със значително намаляване на необходимите FLOPs и изисква само 1/16 от обучителния корпус. В средни и големи мащаби TLM очевидно може да подобри производителността средно с 0.59 и 0.24 точки, като същевременно намалява размера на данните за обучение с два порядъка.
„Тези резултати потвърждават, че TLM е много точен и много по-ефективен от PLM. Освен това TLM печели повече предимства в ефективността в по-голям мащаб. Това показва, че по-мащабните PLM може да са били обучени да съхраняват по-общи знания, които не са полезни за конкретна задача.















