الذكاء الاصطناعي
Zero123++: صورة واحدة لنموذج أساسي متسق للانتشار متعدد المشاهدات

شهدت السنوات القليلة الماضية تقدما سريعا في الأداء والكفاءة والقدرات الإنتاجية للرواية الناشئة نماذج الذكاء الاصطناعي التوليدية التي تستفيد من مجموعات البيانات الشاملة وممارسات توليد الانتشار ثنائي الأبعاد. اليوم، أصبحت نماذج الذكاء الاصطناعي التوليدية قادرة للغاية على إنشاء أشكال مختلفة من محتوى الوسائط ثنائي الأبعاد، وإلى حد ما ثلاثي الأبعاد، بما في ذلك النصوص والصور ومقاطع الفيديو وملفات GIF والمزيد.
في هذه المقالة، سنتحدث عن إطار عمل Zero123++، وهو نموذج ذكاء اصطناعي توليدي منتشر مشروط بالصور يهدف إلى إنشاء صور متعددة العرض ومتسقة ثلاثية الأبعاد باستخدام إدخال عرض واحد. لتعظيم الميزة المكتسبة من النماذج التوليدية المدربة مسبقًا، ينفذ إطار عمل Zero3++ العديد من خطط التدريب والتكييف لتقليل مقدار الجهد الذي يتطلبه الضبط من نماذج صور الانتشار الجاهزة. سنتعمق أكثر في بنية إطار عمل Zero123++ وعمله ونتائجه، ونحلل قدراته لإنشاء صور متسقة متعددة العرض ذات جودة عالية من صورة واحدة. اذا هيا بنا نبدأ.
Zero123 وZero123++: مقدمة
إطار عمل Zero123++ هو نموذج ذكاء اصطناعي توليدي قائم على الانتشار، يهدف إلى توليد صور ثلاثية الأبعاد متعددة المشاهد باستخدام مدخل عرض واحد. يُعد إطار عمل Zero3++ استمرارًا لإطار عمل Zero123 أو Zero-123-to-1، الذي يعتمد على تقنية توليف صور العرض الجديدة من لقطة واحدة، مما يُمهد الطريق لتحويل الصور الفردية إلى صور ثلاثية الأبعاد مفتوحة المصدر. على الرغم من أن إطار عمل Zero3++ يُقدم أداءً واعدًا، إلا أن الصور التي يُنتجها تُظهر تناقضات هندسية واضحة، وهذا هو السبب الرئيسي في استمرار الفجوة بين المشاهد ثلاثية الأبعاد والصور متعددة المشاهد.
يعمل إطار عمل Zero-1-to-3 كأساس للعديد من أطر العمل الأخرى بما في ذلك SyncDreamer وOne-2-3-45 وConsistent123 والمزيد التي تضيف طبقات إضافية إلى إطار عمل Zero123 للحصول على نتائج أكثر اتساقًا عند إنشاء صور ثلاثية الأبعاد. أطر عمل أخرى مثل ProlificDreamer وDreamFusion وDreamGaussian والمزيد تتبع نهجًا قائمًا على التحسين للحصول على صور ثلاثية الأبعاد عن طريق استخلاص صورة ثلاثية الأبعاد من نماذج مختلفة غير متناسقة. على الرغم من أن هذه التقنيات فعالة، وأنها تولد صورًا ثلاثية الأبعاد مُرضية، إلا أنه يمكن تحسين النتائج من خلال تنفيذ نموذج نشر أساسي قادر على إنشاء صور متعددة العرض بشكل متسق. وبناء على ذلك، فإن إطار عمل Zero3++ يأخذ Zero-3 إلى 3، ويضبط نموذج نشر أساسي متعدد العرض جديد من Stable Diffusion.
في إطار صفر 1 إلى 3، يتم إنشاء كل عرض جديد بشكل مستقل، ويؤدي هذا النهج إلى تناقضات بين وجهات النظر التي تم إنشاؤها لأن نماذج الانتشار لها طبيعة أخذ العينات. لمعالجة هذه المشكلة، يعتمد إطار عمل Zero123++ أسلوب تخطيط التبليط، حيث يكون الكائن محاطًا بستة مشاهدات في صورة واحدة، ويضمن النمذجة الصحيحة للتوزيع المشترك للصور متعددة المشاهدات للكائن.
التحدي الرئيسي الآخر الذي يواجهه المطورون الذين يعملون على إطار عمل Zero-1-to-3 هو أنه لا يستخدم الإمكانات التي يوفرها انتشار مستقر مما يؤدي في النهاية إلى عدم الكفاءة والتكاليف الإضافية. هناك سببان رئيسيان لعدم تمكن إطار عمل Zero-1-to-3 من زيادة الإمكانات التي يوفرها Stable Diffusion
- عند التدريب باستخدام ظروف الصورة، لا يتضمن إطار عمل Zero-1-to-3 آليات التكييف المحلية أو العالمية التي تقدمها Stable Diffusion بشكل فعال.
- أثناء التدريب، يستخدم إطار عمل Zero-1-to-3 دقة منخفضة، وهو أسلوب يتم فيه تقليل دقة المخرجات إلى ما دون دقة التدريب التي يمكن أن تقلل من جودة إنشاء الصور لنماذج الانتشار المستقر.
لمعالجة هذه المشكلات، يطبق إطار عمل Zero123++ مجموعة من تقنيات التكييف التي تزيد من الاستفادة من الموارد التي تقدمها Stable Diffusion، وتحافظ على جودة إنشاء الصور لنماذج Stable Diffusion.
تحسين التكييف والاتساق
في محاولة لتحسين تكييف الصورة واتساق الصورة متعددة العرض، طبق إطار عمل Zero123++ تقنيات مختلفة، حيث كان الهدف الأساسي هو إعادة استخدام التقنيات السابقة المستمدة من نموذج Stable Diffusion الذي تم تدريبه مسبقًا.
جيل العرض المتعدد
تكمن الجودة التي لا غنى عنها في إنشاء صور متسقة ومتعددة العرض في نمذجة التوزيع المشترك للصور المتعددة بشكل صحيح. في إطار عمل صفر إلى 1، يتم تجاهل الارتباط بين الصور متعددة العرض لأنه بالنسبة لكل صورة، يقوم الإطار بنمذجة التوزيع الهامشي المشروط بشكل مستقل ومنفصل. ومع ذلك، في إطار عمل Zero3++، اختار المطورون أسلوب تخطيط التبليط الذي يقوم بتجانب 123 صور في إطار/صورة واحدة لإنشاء عرض متعدد متسق، ويتم توضيح العملية في الصورة التالية.
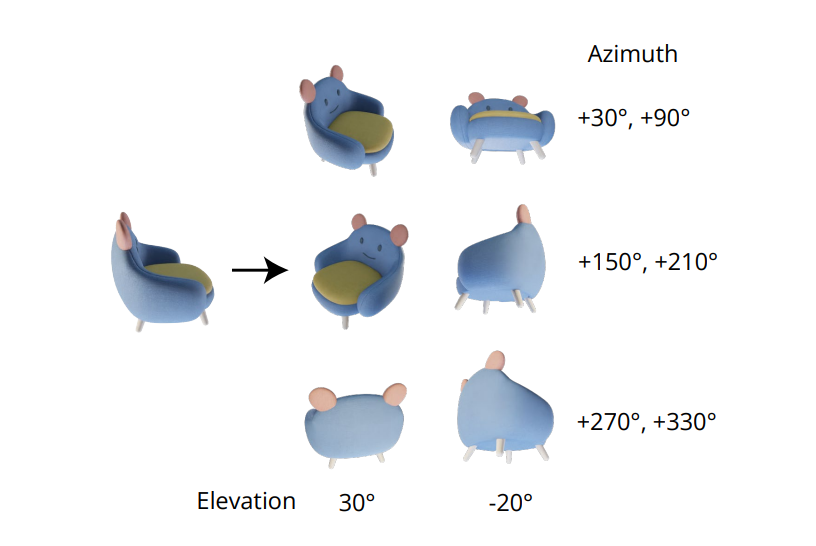

علاوة على ذلك، فقد لوحظ أن اتجاهات الكائنات تميل إلى إزالة الغموض عند تدريب النموذج على وضعيات الكاميرا، ولمنع هذا التوضيح، يتم تدريب إطار العمل من صفر إلى 1 على الكاميرا بزوايا الارتفاع والسمت النسبي للإدخال. لتنفيذ هذا النهج، من الضروري معرفة زاوية الارتفاع لعرض الإدخال الذي يتم استخدامه بعد ذلك لتحديد الوضع النسبي بين طرق عرض الإدخال الجديدة. في محاولة لمعرفة زاوية الارتفاع هذه، غالبًا ما تضيف الأطر وحدة تقدير الارتفاع، وغالبًا ما يأتي هذا النهج على حساب أخطاء إضافية في المسار.
جدول الضوضاء
جدول خطي متدرج، يركز جدول الضوضاء الأصلي لـ Stable Diffusion بشكل أساسي على التفاصيل المحلية، ولكن كما هو موضح في الصورة التالية، فهو يحتوي على خطوات قليلة جدًا مع نسبة SNR أو نسبة الإشارة إلى الضوضاء أقل.


تحدث خطوات انخفاض نسبة الإشارة إلى الضوضاء في وقت مبكر خلال مرحلة تقليل الضوضاء، وهي مرحلة حاسمة لتحديد البنية العالمية للتردد المنخفض. إن تقليل عدد الخطوات خلال مرحلة تقليل الضوضاء، سواء أثناء التداخل أو التدريب غالبًا ما يؤدي إلى تباين هيكلي أكبر. على الرغم من أن هذا الإعداد مثالي لإنشاء صورة واحدة، إلا أنه يحد من قدرة إطار العمل على ضمان الاتساق العالمي بين طرق العرض المختلفة. للتغلب على هذه العقبة، يقوم إطار عمل Zero123++ بضبط نموذج LoRA في إطار التنبؤ v لـ Stable Diffusion 2 لأداء مهمة لعبة، ويتم عرض النتائج أدناه.

من خلال جدول الضوضاء الخطي المتدرج، لا يؤدي نموذج LoRA إلى زيادة التناسب، ولكنه يؤدي فقط إلى تبييض الصورة قليلاً. على العكس من ذلك، عند العمل مع جدول الضوضاء الخطي، يقوم إطار عمل LoRA بإنشاء صورة فارغة بنجاح بغض النظر عن موجه الإدخال، مما يدل على تأثير جدول الضوضاء على قدرة الإطار على التكيف مع المتطلبات الجديدة عالميًا.
الاهتمام المرجعي المتدرج للظروف المحلية
يتم ربط مدخلات العرض الفردي أو صور التكييف في إطار عمل Zero-1-to-3 مع المدخلات المزعجة في بُعد الميزة المراد تشويشها لتكييف الصورة.
يؤدي هذا التسلسل إلى مراسلات مكانية غير صحيحة من حيث البكسل بين الصورة المستهدفة والمدخلات. لتوفير مدخلات تكييف محلية مناسبة، يستخدم إطار عمل Zero123++ اهتمامًا مرجعيًا متدرجًا، وهو أسلوب يتم من خلاله إحالة تشغيل نموذج UNet لتقليل الضوضاء على صورة مرجعية إضافية، متبوعًا بإلحاق مصفوفات القيمة ومفتاح الاهتمام الذاتي من المرجع الصورة إلى طبقات الاهتمام المعنية عندما يتم تقليل الضوضاء في إدخال النموذج، وهو موضح في الشكل التالي.

إن نهج الاهتمام المرجعي قادر على توجيه نموذج الانتشار لإنشاء صور تشبه الملمس مع الصورة المرجعية والمحتوى الدلالي دون أي ضبط دقيق. من خلال الضبط الدقيق، يوفر نهج الاهتمام المرجعي نتائج فائقة مع قياس الحجم الكامن.

التكييف العالمي: FlexDiffuse
في منهج Stable Diffusion الأصلي، تعد عمليات تضمين النص هي المصدر الوحيد للتضمينات العامة، ويستخدم النهج إطار عمل CLIP كمشفر نص لإجراء اختبارات متبادلة بين عمليات تضمين النص والنماذج الكامنة. ونتيجة لذلك، يتمتع المطورون بحرية استخدام المحاذاة بين مساحات النص وصور CLIP الناتجة لاستخدامها في تكييفات الصورة العامة.
يقترح إطار عمل Zero123++ الاستفادة من متغير قابل للتدريب لآلية التوجيه الخطي لدمج تكييف الصورة العالمي في الإطار بأقل قدر ممكن من الدقة. الكون المثالى كما هو مطلوب، والنتائج موضحة في الصورة التالية. كما يتضح، بدون وجود تكييف شامل للصورة، تكون جودة المحتوى المُولّد بواسطة الإطار مُرضية للمناطق المرئية المُقابلة للصورة المُدخلة. ومع ذلك، تشهد جودة الصورة المُولّدة بواسطة الإطار للمناطق غير المرئية تدهورًا ملحوظًا، ويعود ذلك أساسًا إلى عدم قدرة النموذج على استنتاج الدلالات الشاملة للكائن.

العمارة النموذجية
تم تدريب إطار عمل Zero123++ باستخدام نموذج Stable Diffusion 2v كأساس باستخدام الأساليب والتقنيات المختلفة المذكورة في المقالة. تم تدريب إطار عمل Zero123++ مسبقًا على مجموعة بيانات Objaverse التي يتم تقديمها باستخدام إضاءة HDRI عشوائية. يعتمد الإطار أيضًا نهج جدول التدريب المرحلي المستخدم في إطار عمل Stable Diffusion Image Variations في محاولة لتقليل مقدار الضبط الدقيق المطلوب، والحفاظ على أكبر قدر ممكن في Stable Diffusion السابق.
يمكن تقسيم عمل أو بنية إطار عمل Zero123++ إلى خطوات أو مراحل متسلسلة. تشهد المرحلة الأولى إطار الضبط الدقيق لمصفوفات KV لطبقات الانتباه المتبادل، وطبقات الانتباه الذاتي الخاصة بـ Stable Diffusion مع AdamW كمحسن لها، و1000 خطوة إحماء وجدول معدل التعلم جيب التمام الذي يصل إلى الحد الأقصى عند 7 × 10-5. في المرحلة الثانية، يستخدم الإطار معدل تعلم ثابت محافظ للغاية مع 2000 مجموعة إحماء، ويستخدم نهج Min-SNR لتحقيق أقصى قدر من الكفاءة أثناء التدريب.
Zero123++: النتائج ومقارنة الأداء
الأداء النوعي
لتقييم أداء إطار عمل Zero123++ على أساس الجودة التي تم إنشاؤها، تمت مقارنته بـ SyncDreamer وZero-1-to-3- XL، وهما من أفضل أطر العمل لإنشاء المحتوى. تتم مقارنة الأطر بأربع صور إدخال ذات نطاق مختلف. الصورة الأولى عبارة عن لعبة قطة كهربائية، مأخوذة مباشرة من مجموعة بيانات Objaverse، وتتميز بوجود قدر كبير من عدم اليقين على الطرف الخلفي من الجسم. الثانية صورة طفاية حريق، والثالثة صورة كلب يجلس على صاروخ، تم إنشاؤها بواسطة نموذج SDXL. الصورة النهائية هي رسم توضيحي للأنمي. يتم تحقيق خطوات الرفع المطلوبة للأطر باستخدام طريقة تقدير الارتفاع لإطار عمل One-2-3-4-5، ويتم تحقيق إزالة الخلفية باستخدام إطار عمل SAM. كما هو واضح، يُنشئ إطار عمل Zero123++ صورًا عالية الجودة ومتعددة العرض باستمرار، وهو قادر على التعميم على الرسوم التوضيحية ثنائية الأبعاد خارج المجال، والصور التي تم إنشاؤها بواسطة الذكاء الاصطناعي بشكل متساوٍ.


تحليل كمي
لإجراء مقارنة كمية لإطار عمل Zero123++ مع إطاري عمل Zero-1-to-3 وZero-1to-3 XL المتطورين، يقوم المطورون بتقييم درجة تشابه تصحيح الصور الإدراكية (LPIPS) لهذه النماذج على بيانات تقسيم التحقق من الصحة، وهي مجموعة فرعية من مجموعة بيانات Objaverse. لتقييم أداء النموذج عند إنشاء صور متعددة العرض، يقوم المطورون بتجانب الصور المرجعية للحقيقة الأرضية و6 صور تم إنشاؤها على التوالي، ثم يحسبون درجة تشابه تصحيح الصور الإدراكية الحسية (LPIPS). النتائج موضحة أدناه وكما هو واضح، يحقق إطار عمل Zero123++ أفضل أداء في مجموعة التحقق من الصحة المقسمة.

النص إلى تقييم العرض المتعدد
لتقييم قدرة إطار عمل Zero123++ في إنشاء محتوى النص إلى عرض متعدد، يستخدم المطورون أولاً إطار عمل SDXL مع المطالبات النصية لإنشاء صورة، ثم يستخدمون إطار عمل Zero123++ في الصورة التي تم إنشاؤها. يتم عرض النتائج في الصورة التالية، وكما هو واضح، عند مقارنتها بإطار عمل Zero-1-to-3 الذي لا يمكنه ضمان إنشاء عرض متعدد متسق، فإن إطار عمل Zero123++ يُرجع عناصر متعددة متسقة وواقعية ومفصلة للغاية. عرض الصور عن طريق تنفيذ تحويل النص إلى صورة إلى عرض متعدد النهج أو خط الأنابيب.

شبكة التحكم في العمق Zero123++
بالإضافة إلى إطار عمل Zero123++ الأساسي، أصدر المطورون أيضًا Depth ControlNet Zero123++، وهو إصدار يتم التحكم فيه بعمق من الإطار الأصلي الذي تم إنشاؤه باستخدام بنية ControlNet. يتم عرض الصور الخطية المقيسة فيما يتعلق بصور RGB اللاحقة، ويتم تدريب إطار عمل ControlNet للتحكم في هندسة إطار عمل Zero123++ باستخدام إدراك العمق.


الخاتمة
في هذه المقالة، تحدثنا عن Zero123++، وهو نموذج ذكاء اصطناعي توليدي منتشر مشروط بالصور يهدف إلى إنشاء صور متعددة العرض ومتسقة ثلاثية الأبعاد باستخدام إدخال عرض واحد. لتعظيم الميزة المكتسبة من النماذج التوليدية المدربة مسبقًا، ينفذ إطار عمل Zero3++ العديد من خطط التدريب والتكييف لتقليل مقدار الجهد الذي يتطلبه الضبط من نماذج صور الانتشار الجاهزة. لقد ناقشنا أيضًا الأساليب والتحسينات المختلفة التي ينفذها إطار عمل Zero123++ والذي يساعده على تحقيق نتائج قابلة للمقارنة بل وتتجاوز تلك التي حققتها أطر العمل الحالية.
ومع ذلك، على الرغم من كفاءته وقدرته على إنشاء صور عالية الجودة ومتعددة العرض باستمرار، إلا أن إطار عمل Zero123++ لا يزال لديه بعض المجال للتحسين، مع كون مجالات البحث المحتملة بمثابة
- نموذج التكرير على مرحلتين قد يحل ذلك عدم قدرة Zero123++ على تلبية المتطلبات العالمية للاتساق.
- عمليات توسيع النطاق الإضافية لتعزيز قدرة Zero123++ على إنتاج صور ذات جودة أعلى.
