الذكاء الاصطناعي
تحسين التفضيل المباشر: دليل كامل

يعد مواءمة نماذج اللغات الكبيرة (LLMs) مع القيم والتفضيلات الإنسانية أمرًا صعبًا. الطرق التقليدية مثل التعزيز التعلم من ردود الفعل البشرية (RLHF)، مهدت الطريق من خلال دمج المدخلات البشرية لتحسين مخرجات النموذج. ومع ذلك، يمكن أن يكون RLHF معقدًا ومستهلكًا للموارد، ويتطلب قوة حسابية كبيرة ومعالجة البيانات. تحسين التفضيل المباشر تبرز (DPO) كنهج جديد وأكثر انسيابية، حيث تقدم بديلاً فعالاً للطرق التقليدية. بتبسيط عملية التحسين، لا يقتصر دور DPO على تقليل العبء الحسابي فحسب، بل يعزز أيضاً قدرة النموذج على التكيف بسرعة مع التفضيلات البشرية.
في هذا الدليل، سنتعمق في مجال حماية البيانات الشخصية، ونستكشف أسسها وتنفيذها وتطبيقاتها العملية.
الحاجة إلى محاذاة التفضيلات
لفهم دور مديري البيانات، من الضروري فهم أهمية مواءمة برامج ماجستير إدارة الأعمال مع التفضيلات البشرية. فعلى الرغم من قدراتها المذهلة، قد تُنتج برامج ماجستير إدارة الأعمال المُدربة على مجموعات بيانات ضخمة أحيانًا مخرجات غير متسقة أو متحيزة أو غير متوافقة مع القيم الإنسانية. ويتجلى هذا الاختلال في عدة أشكال:
- إنشاء محتوى غير آمن أو ضار
- تقديم معلومات غير دقيقة أو مضللة
- إظهار التحيزات الموجودة في بيانات التدريب
ولمعالجة هذه المشكلات، قام الباحثون بتطوير تقنيات لتحسين درجة الماجستير في القانون باستخدام التغذية الراجعة البشرية. وكان أبرز هذه الأساليب هو RLHF.
فهم RLHF: مقدمة لDPO
يُعدّ التعلم التعزيزي من التغذية الراجعة البشرية (RLHF) الأسلوب الأمثل لمواءمة برامج الماجستير في القانون مع التفضيلات البشرية. دعونا نستعرض عملية التعلم التعزيزي من التغذية الراجعة البشرية لفهم تعقيداتها:
a) الضبط الدقيق الخاضع للإشراف (SFT): تبدأ العملية بضبط ماجستير إدارة الأعمال المدرب مسبقًا على مجموعة بيانات من الاستجابات عالية الجودة. تساعد هذه الخطوة النموذج على إنشاء مخرجات أكثر صلة وتماسكًا للمهمة المستهدفة.
b) نمذجة المكافأة: يتم تدريب نموذج مكافأة منفصل للتنبؤ بالتفضيلات البشرية. وهذا ينطوي على:
- توليد أزواج الاستجابة لمطالبات معينة
- جعل البشر يقيمون الاستجابة التي يفضلونها
- تدريب نموذج للتنبؤ بهذه التفضيلات
c) تعزيز التعلم: يتم بعد ذلك تحسين LLM المضبوط بشكل أكبر باستخدام التعلم المعزز. يوفر نموذج المكافأة ردود الفعل، ويوجه LLM لتوليد استجابات تتوافق مع التفضيلات البشرية.
فيما يلي كود بايثون مبسط لتوضيح عملية RLHF:
على الرغم من فعاليته، إلا أن RLHF له عيوب عديدة:
- يتطلب التدريب وصيانة نماذج متعددة (SFT، ونموذج المكافأة، والنموذج المحسّن لـ RL).
- يمكن أن تكون عملية RL غير مستقرة وحساسة للمعلمات الفائقة
- إنها مكلفة حسابيًا، وتتطلب العديد من التمريرات الأمامية والخلفية عبر النماذج
وقد حفزت هذه القيود على البحث عن بدائل أبسط وأكثر كفاءة، مما أدى إلى تطوير DPO.
تحسين التفضيل المباشر: المفاهيم الأساسية

تحسين التفضيل المباشر https://arxiv.org/abs/2305.18290
تُقارن هذه الصورة بين نهجين مختلفين لمواءمة مخرجات ماجستير اللغة مع التفضيلات البشرية: التعلم التعزيزي من التغذية الراجعة البشرية (RLHF) وتحسين التفضيلات المباشر (DPO). يعتمد التعلم التعزيزي من التغذية الراجعة البشرية على نموذج مكافآت لتوجيه سياسة نموذج اللغة من خلال حلقات التغذية الراجعة التكرارية، بينما يُحسّن DPO مخرجات النموذج مباشرةً لمطابقة الاستجابات المفضلة لدى البشر باستخدام بيانات التفضيلات. تُبرز هذه المقارنة نقاط القوة والتطبيقات المحتملة لكل طريقة، مُقدمةً رؤىً حول كيفية تدريب ماجستير اللغة في المستقبل على مواءمة أفضل مع التوقعات البشرية.
الأفكار الرئيسية وراء DPO:
a) نمذجة المكافأة الضمنية: يلغي DPO الحاجة إلى نموذج مكافأة منفصل من خلال التعامل مع نموذج اللغة نفسه كوظيفة مكافأة ضمنية.
b) الصياغة القائمة على السياسات: بدلاً من تحسين وظيفة المكافأة، يقوم DPO مباشرة بتحسين السياسة (نموذج اللغة) لزيادة احتمالية الاستجابات المفضلة.
c) حل النموذج المغلق: يستفيد DPO من الرؤية الرياضية التي تسمح بحل مغلق للسياسة المثلى، مما يتجنب الحاجة إلى تحديثات RL المتكررة.
تنفيذ DPO: دليل عملي للتعليمات البرمجية
تُظهر الصورة أدناه مقتطفًا من شيفرة برمجية تُطبّق دالة خسارة DPO باستخدام PyTorch. تلعب هذه الدالة دورًا محوريًا في تحسين كيفية تحديد نماذج اللغة لأولويات المخرجات بناءً على تفضيلات المستخدم. فيما يلي تفصيل للمكونات الرئيسية:
- التوقيع الوظيفي:
dpo_lossتأخذ الوظيفة عدة معلمات بما في ذلك احتمالات سجل السياسة (pi_logps) ، احتمالات سجل النموذج المرجعي (ref_logps)، والمؤشرات التي تمثل الإكمالات المفضلة وغير المفضلة (yw_idxs,yl_idxs). بالإضافة إلى ذلك، أbetaتتحكم المعلمة في قوة عقوبة KL. - استخراج احتمالية السجل: يستخرج الكود احتمالات السجل للإكمالات المفضلة وغير المفضلة من كل من نموذجي السياسة والنموذج المرجعي.
- حساب نسبة السجل: يتم حساب الفرق بين احتمالات السجل للإكمالات المفضلة وغير المفضلة لكل من نموذجي السياسة والنموذج المرجعي. هذه النسبة حاسمة في تحديد اتجاه وحجم التحسين.
- حساب الخسارة والمكافأة: يتم حساب الخسارة باستخدام
logsigmoidوظيفة، في حين يتم تحديد المكافآت عن طريق قياس الفرق بين احتمالات السياسة والسجل المرجعيbeta.

وظيفة فقدان DPO باستخدام PyTorch
دعونا نتعمق في الرياضيات وراء DPO لفهم كيفية تحقيق هذه الأهداف.
رياضيات DPO
DPO هي إعادة صياغة ذكية لمشكلة تعلم التفضيلات. إليك شرحًا خطوة بخطوة:
أ) نقطة البداية: تعظيم المكافأة المقيدة بـ KL
يمكن التعبير عن هدف RLHF الأصلي على النحو التالي:
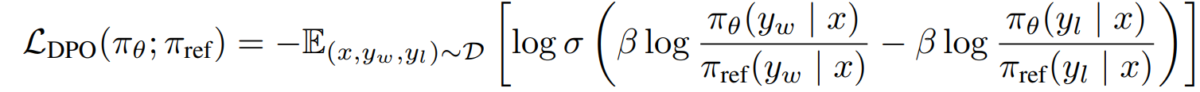
- πθ هي السياسة (نموذج اللغة) التي نقوم بتحسينها
- r(x,y) هي دالة المكافأة
- πref هي سياسة مرجعية (عادةً ما تكون نموذج SFT الأولي)
- β يتحكم في قوة قيد تباعد KL
b) نموذج السياسة الأمثل: ويمكن إثبات أن السياسة المثلى لتحقيق هذا الهدف تأخذ الشكل التالي:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))حيث Z(x) هو ثابت التطبيع.
c) ازدواجية سياسة المكافأة: تتمثل الرؤية الأساسية لـ DPO في التعبير عن دالة المكافأة من حيث السياسة المثلى:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))د) نموذج التفضيل بافتراض أن التفضيلات تتبع نموذج برادلي-تيري، يمكننا التعبير عن احتمال تفضيل y1 على y2 على النحو التالي:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))حيث σ هي الوظيفة اللوجستية.
e) هدف DPO باستبدال ازدواجية سياسة المكافآت لدينا في نموذج التفضيل، نصل إلى هدف DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]يمكن تحسين هذا الهدف باستخدام تقنيات النسب التدرج القياسية، دون الحاجة إلى خوارزميات RL.
تنفيذ DPO
الآن بعد أن فهمنا نظرية DPO، دعونا نلقي نظرة على كيفية تطبيقها عمليًا. سنستخدم Python و PyTorch لهذا المثال:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
التحديات والتوجهات المستقبلية
في حين أن DPO يقدم مزايا كبيرة مقارنة بمناهج RLHF التقليدية، إلا أنه لا تزال هناك تحديات ومجالات لمزيد من البحث:
أ) قابلية التوسع إلى نماذج أكبر:
مع استمرار نمو حجم النماذج اللغوية، فإن تطبيق DPO بكفاءة على النماذج التي تحتوي على مئات المليارات من المعلمات يظل تحديًا مفتوحًا. يستكشف الباحثون تقنيات مثل:
- طرق ضبط دقيقة فعالة (على سبيل المثال، LoRA، ضبط البادئة)
- تحسينات التدريب الموزعة
- نقاط التفتيش المتدرجة والتدريب المختلط الدقة
مثال لاستخدام LoRA مع DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
ب) تعدد المهام والتكيف مع اللقطات القليلة:
يعد تطوير تقنيات DPO التي يمكنها التكيف بكفاءة مع المهام أو المجالات الجديدة ذات بيانات التفضيل المحدودة مجالًا نشطًا للبحث. وتشمل النهج التي يجري استكشافها ما يلي:
- أطر التعلم التلوي للتكيف السريع
- الضبط الدقيق الفوري لـ DPO
- نقل التعلم من نماذج التفضيلات العامة إلى مجالات محددة
ج) التعامل مع التفضيلات الغامضة أو المتضاربة:
غالبًا ما تحتوي بيانات التفضيلات الواقعية على غموض أو تضارب. يُعدّ تحسين قدرة مسؤول حماية البيانات على التعامل مع هذه البيانات أمرًا بالغ الأهمية. تشمل الحلول المحتملة ما يلي:
- نمذجة التفضيلات الاحتمالية
- التعلم النشط لحل الغموض
- تجميع تفضيلات الوكيل المتعدد
مثال على نمذجة التفضيل الاحتمالي:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
د) الجمع بين DPO وتقنيات المحاذاة الأخرى:
يمكن أن يؤدي دمج DPO مع أساليب المحاذاة الأخرى إلى أنظمة أكثر قوة وقدرة:
- مبادئ الذكاء الاصطناعي الدستورية من أجل رضا القيد الصريح
- مناقشة ونمذجة المكافأة العودية لاستنباط التفضيلات المعقدة
- التعلم المعزز العكسي لاستنتاج وظائف المكافأة الأساسية
مثال على دمج DPO مع الذكاء الاصطناعي الدستوري:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
الاعتبارات العملية وأفضل الممارسات
عند تنفيذ DPO لتطبيقات العالم الحقيقي، خذ في الاعتبار النصائح التالية:
a) جودة البيانات: جودة البيانات المفضلة لديك أمر بالغ الأهمية. تأكد من أن مجموعة البيانات الخاصة بك:
- يغطي مجموعة متنوعة من المدخلات والسلوكيات المرغوبة
- لديه شروح تفضيلية متسقة وموثوقة
- يوازن بين أنواع مختلفة من التفضيلات (على سبيل المثال، الواقعية والسلامة والأسلوب)
b) ضبط Hyperparameter: على الرغم من أن DPO يحتوي على معلمات تشعبية أقل من RLHF، إلا أن الضبط لا يزال مهمًا:
- β (بيتا): يتحكم في المفاضلة بين رضا التفضيل والاختلاف عن النموذج المرجعي. ابدأ بالقيم المحيطة 0.1-0.5.
- معدل التعلم: استخدم معدل تعلم أقل من الضبط الدقيق القياسي، وعادة ما يكون في نطاق 1e-6 إلى 1e-5.
- حجم الدفعة: أحجام دفعة أكبر (32-128) غالبًا ما تعمل بشكل جيد لتعلم التفضيلات.
c) صقل متكرر: يمكن تطبيق DPO بشكل متكرر:
- تدريب نموذج أولي باستخدام DPO
- توليد استجابات جديدة باستخدام النموذج المدرب
- جمع بيانات التفضيلات الجديدة على هذه الاستجابات
- إعادة التدريب باستخدام مجموعة البيانات الموسعة

أداء تحسين التفضيل المباشر
تُظهر هذه الصورة أداء نماذج التعلم العميق (LLMs) مثل GPT-4 مقارنةً بالأحكام البشرية عبر تقنيات تدريب متنوعة، بما في ذلك تحسين التفضيلات المباشرة (DPO)، والضبط الدقيق المُشرف (SFT)، وتحسين السياسات القريبة (PPO). يُظهر الجدول أن مخرجات GPT-4 تتوافق بشكل متزايد مع التفضيلات البشرية، وخاصةً في مهام التلخيص. يُظهر مستوى التوافق بين GPT-4 والمراجعين البشريين قدرة النموذج على توليد محتوى يلقى صدى لدى المُقيّمين البشريين، تقريبًا بنفس درجة توافق المحتوى المُولّد من قِبل البشر.
دراسات الحالة والتطبيقات
لتوضيح فعالية DPO، دعونا نلقي نظرة على بعض التطبيقات الواقعية وبعض المتغيرات الخاصة بها:
- DPO التكراري: تم تطويره بواسطة Snorkel (2023)، يجمع هذا المتغير بين أخذ عينات الرفض مع DPO، مما يتيح عملية اختيار أكثر دقة لبيانات التدريب. من خلال التكرار على جولات متعددة من أخذ عينات التفضيلات، يكون النموذج أكثر قدرة على التعميم وتجنب الإفراط في التفضيلات المزعجة أو المتحيزة.
- الاكتتاب العام (تحسين التفضيلات التكرارية): قدمه عازار وآخرون. (2023)، يضيف الاكتتاب العام مصطلح تنظيم لمنع التجهيز الزائد، وهي مشكلة شائعة في التحسين القائم على التفضيلات. يسمح هذا الامتداد للنماذج بالحفاظ على التوازن بين الالتزام بالتفضيلات والحفاظ على قدرات التعميم.
- كتو (تحسين نقل المعرفة): نسخة أحدث من Ethayarajh et al. (2023)، تستغني KTO عن التفضيلات الثنائية تمامًا. وبدلا من ذلك، يركز على نقل المعرفة من نموذج مرجعي إلى نموذج السياسة، وتحسين المواءمة الأكثر سلاسة واتساقا مع القيم الإنسانية.
- DPO متعدد الوسائط للتعلم عبر المجالات بواسطة شو وآخرون. (2024): نهج يتم فيه تطبيق DPO عبر طرائق مختلفة - النص والصورة والصوت - مما يوضح تعدد استخداماته في مواءمة النماذج مع التفضيلات البشرية عبر أنواع البيانات المتنوعة. يسلط هذا البحث الضوء على إمكانات DPO في إنشاء أنظمة ذكاء اصطناعي أكثر شمولاً قادرة على التعامل مع المهام المعقدة ومتعددة الوسائط.












